 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVGT-2: Vision-Geometry-Action Model for Autonomous Driving at Scale
Apr 01, 2026End-to-end autonomous driving has evolved from the conventional paradigm based on sparse perception into vision-language-action (VLA) models, which focus on learning language descriptions as an auxiliary task to facilitate planning. In this paper, we propose an alternative Vision-Geometry-Action (VGA) paradigm that advocates dense 3D geometry as the critical cue for autonomous driving. As vehicles operate in a 3D world, we think dense 3D geometry provides the most comprehensive information for decision-making. However, most existing geometry reconstruction methods (e.g., DVGT) rely on computationally expensive batch processing of multi-frame inputs and cannot be applied to online planning. To address this, we introduce a streaming Driving Visual Geometry Transformer (DVGT-2), which processes inputs in an online manner and jointly outputs dense geometry and trajectory planning for the current frame. We employ temporal causal attention and cache historical features to support on-the-fly inference. To further enhance efficiency, we propose a sliding-window streaming strategy and use historical caches within a certain interval to avoid repetitive computations. Despite the faster speed, DVGT-2 achieves superior geometry reconstruction performance on various datasets. The same trained DVGT-2 can be directly applied to planning across diverse camera configurations without fine-tuning, including closed-loop NAVSIM and open-loop nuScenes benchmarks.
VILTA: A VLM-in-the-Loop Adversary for Enhancing Driving Policy Robustness
Jan 19, 2026The safe deployment of autonomous driving (AD) systems is fundamentally hindered by the long-tail problem, where rare yet critical driving scenarios are severely underrepresented in real-world data. Existing solutions including safety-critical scenario generation and closed-loop learning often rely on rule-based heuristics, resampling methods and generative models learned from offline datasets, limiting their ability to produce diverse and novel challenges. While recent works leverage Vision Language Models (VLMs) to produce scene descriptions that guide a separate, downstream model in generating hazardous trajectories for agents, such two-stage framework constrains the generative potential of VLMs, as the diversity of the final trajectories is ultimately limited by the generalization ceiling of the downstream algorithm. To overcome these limitations, we introduce VILTA (VLM-In-the-Loop Trajectory Adversary), a novel framework that integrates a VLM into the closed-loop training of AD agents. Unlike prior works, VILTA actively participates in the training loop by comprehending the dynamic driving environment and strategically generating challenging scenarios through direct, fine-grained editing of surrounding agents' future trajectories. This direct-editing approach fully leverages the VLM's powerful generalization capabilities to create a diverse curriculum of plausible yet challenging scenarios that extend beyond the scope of traditional methods. We demonstrate that our approach substantially enhances the safety and robustness of the resulting AD policy, particularly in its ability to navigate critical long-tail events.
DVGT: Driving Visual Geometry Transformer
Dec 18, 2025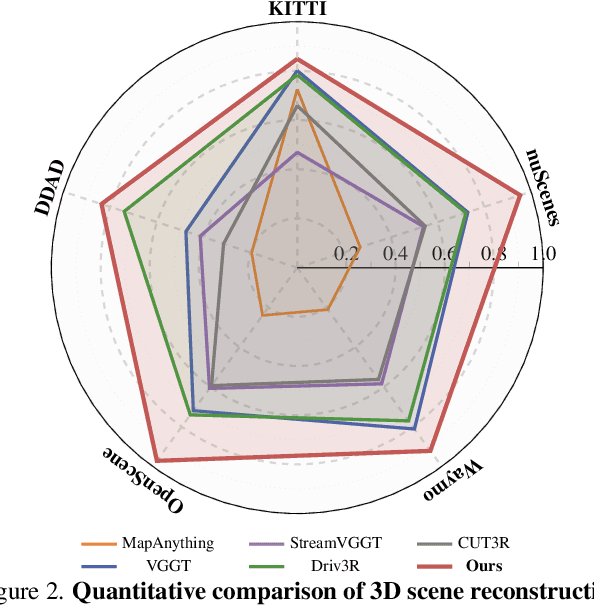
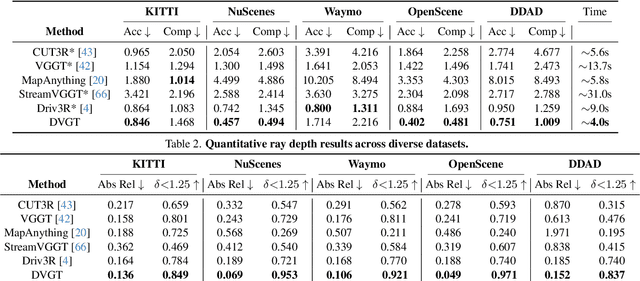
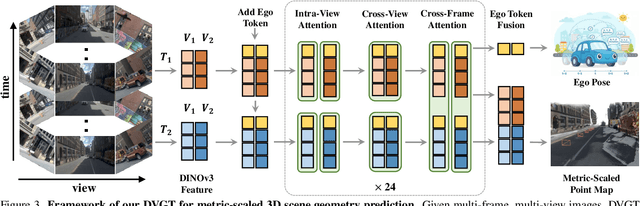
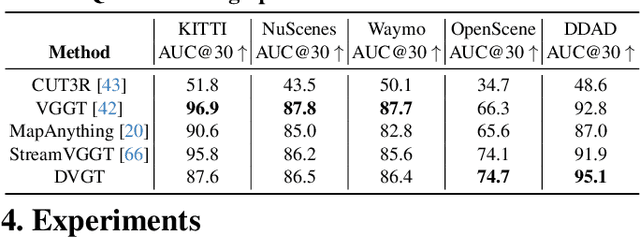
Perceiving and reconstructing 3D scene geometry from visual inputs is crucial for autonomous driving. However, there still lacks a driving-targeted dense geometry perception model that can adapt to different scenarios and camera configurations. To bridge this gap, we propose a Driving Visual Geometry Transformer (DVGT), which reconstructs a global dense 3D point map from a sequence of unposed multi-view visual inputs. We first extract visual features for each image using a DINO backbone, and employ alternating intra-view local attention, cross-view spatial attention, and cross-frame temporal attention to infer geometric relations across images. We then use multiple heads to decode a global point map in the ego coordinate of the first frame and the ego poses for each frame. Unlike conventional methods that rely on precise camera parameters, DVGT is free of explicit 3D geometric priors, enabling flexible processing of arbitrary camera configurations. DVGT directly predicts metric-scaled geometry from image sequences, eliminating the need for post-alignment with external sensors. Trained on a large mixture of driving datasets including nuScenes, OpenScene, Waymo, KITTI, and DDAD, DVGT significantly outperforms existing models on various scenarios. Code is available at https://github.com/wzzheng/DVGT.
GaussianAD: Gaussian-Centric End-to-End Autonomous Driving
Dec 13, 2024



Vision-based autonomous driving shows great potential due to its satisfactory performance and low costs. Most existing methods adopt dense representations (e.g., bird's eye view) or sparse representations (e.g., instance boxes) for decision-making, which suffer from the trade-off between comprehensiveness and efficiency. This paper explores a Gaussian-centric end-to-end autonomous driving (GaussianAD) framework and exploits 3D semantic Gaussians to extensively yet sparsely describe the scene. We initialize the scene with uniform 3D Gaussians and use surrounding-view images to progressively refine them to obtain the 3D Gaussian scene representation. We then use sparse convolutions to efficiently perform 3D perception (e.g., 3D detection, semantic map construction). We predict 3D flows for the Gaussians with dynamic semantics and plan the ego trajectory accordingly with an objective of future scene forecasting. Our GaussianAD can be trained in an end-to-end manner with optional perception labels when available. Extensive experiments on the widely used nuScenes dataset verify the effectiveness of our end-to-end GaussianAD on various tasks including motion planning, 3D occupancy prediction, and 4D occupancy forecasting. Code: https://github.com/wzzheng/GaussianAD.
GPD-1: Generative Pre-training for Driving
Dec 11, 2024



Modeling the evolutions of driving scenarios is important for the evaluation and decision-making of autonomous driving systems. Most existing methods focus on one aspect of scene evolution such as map generation, motion prediction, and trajectory planning. In this paper, we propose a unified Generative Pre-training for Driving (GPD-1) model to accomplish all these tasks altogether without additional fine-tuning. We represent each scene with ego, agent, and map tokens and formulate autonomous driving as a unified token generation problem. We adopt the autoregressive transformer architecture and use a scene-level attention mask to enable intra-scene bi-directional interactions. For the ego and agent tokens, we propose a hierarchical positional tokenizer to effectively encode both 2D positions and headings. For the map tokens, we train a map vector-quantized autoencoder to efficiently compress ego-centric semantic maps into discrete tokens. We pre-train our GPD-1 on the large-scale nuPlan dataset and conduct extensive experiments to evaluate its effectiveness. With different prompts, our GPD-1 successfully generalizes to various tasks without finetuning, including scene generation, traffic simulation, closed-loop simulation, map prediction, and motion planning. Code: https://github.com/wzzheng/GPD.