 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVGT-2: Vision-Geometry-Action Model for Autonomous Driving at Scale
Apr 01, 2026End-to-end autonomous driving has evolved from the conventional paradigm based on sparse perception into vision-language-action (VLA) models, which focus on learning language descriptions as an auxiliary task to facilitate planning. In this paper, we propose an alternative Vision-Geometry-Action (VGA) paradigm that advocates dense 3D geometry as the critical cue for autonomous driving. As vehicles operate in a 3D world, we think dense 3D geometry provides the most comprehensive information for decision-making. However, most existing geometry reconstruction methods (e.g., DVGT) rely on computationally expensive batch processing of multi-frame inputs and cannot be applied to online planning. To address this, we introduce a streaming Driving Visual Geometry Transformer (DVGT-2), which processes inputs in an online manner and jointly outputs dense geometry and trajectory planning for the current frame. We employ temporal causal attention and cache historical features to support on-the-fly inference. To further enhance efficiency, we propose a sliding-window streaming strategy and use historical caches within a certain interval to avoid repetitive computations. Despite the faster speed, DVGT-2 achieves superior geometry reconstruction performance on various datasets. The same trained DVGT-2 can be directly applied to planning across diverse camera configurations without fine-tuning, including closed-loop NAVSIM and open-loop nuScenes benchmarks.
Vega: Learning to Drive with Natural Language Instructions
Mar 26, 2026Vision-language-action models have reshaped autonomous driving to incorporate languages into the decision-making process. However, most existing pipelines only utilize the language modality for scene descriptions or reasoning and lack the flexibility to follow diverse user instructions for personalized driving. To address this, we first construct a large-scale driving dataset (InstructScene) containing around 100,000 scenes annotated with diverse driving instructions with the corresponding trajectories. We then propose a unified Vision-Language-World-Action model, Vega, for instruction-based generation and planning. We employ the autoregressive paradigm to process visual inputs (vision) and language instructions (language) and the diffusion paradigm to generate future predictions (world modeling) and trajectories (action). We perform joint attention to enable interactions between the modalities and use individual projection layers for different modalities for more capabilities. Extensive experiments demonstrate that our method not only achieves superior planning performance but also exhibits strong instruction-following abilities, paving the way for more intelligent and personalized driving systems.
UniQueR: Unified Query-based Feedforward 3D Reconstruction
Mar 24, 2026We present UniQueR, a unified query-based feedforward framework for efficient and accurate 3D reconstruction from unposed images. Existing feedforward models such as DUSt3R, VGGT, and AnySplat typically predict per-pixel point maps or pixel-aligned Gaussians, which remain fundamentally 2.5D and limited to visible surfaces. In contrast, UniQueR formulates reconstruction as a sparse 3D query inference problem. Our model learns a compact set of 3D anchor points that act as explicit geometric queries, enabling the network to infer scene structure, including geometry in occluded regions--in a single forward pass. Each query encodes spatial and appearance priors directly in global 3D space (instead of per-frame camera space) and spawns a set of 3D Gaussians for differentiable rendering. By leveraging unified query interactions across multi-view features and a decoupled cross-attention design, UniQueR achieves strong geometric expressiveness while substantially reducing memory and computational cost. Experiments on Mip-NeRF 360 and VR-NeRF demonstrate that UniQueR surpasses state-of-the-art feedforward methods in both rendering quality and geometric accuracy, using an order of magnitude fewer primitives than dense alternatives.
Measuring 3D Spatial Geometric Consistency in Dynamic Generated Videos
Mar 19, 2026Recent generative models can produce high-fidelity videos, yet they often exhibit 3D spatial geometric inconsistencies. Existing evaluation methods fail to accurately characterize these inconsistencies: fidelity-centric metrics like FVD are insensitive to geometric distortions, while consistency-focused benchmarks often penalize valid foreground dynamics. To address this gap, we introduce SGC, a metric for evaluating 3D \textbf{S}patial \textbf{G}eometric \textbf{C}onsistency in dynamically generated videos. We quantify geometric consistency by measuring the divergence among multiple camera poses estimated from distinct local regions. Our approach first separates static from dynamic regions, then partitions the static background into spatially coherent sub-regions. We predict depth for each pixel, estimate a local camera pose for each subregion, and compute the divergence among these poses to quantify geometric consistency. Experiments on real and generative videos demonstrate that SGC robustly quantifies geometric inconsistencies, effectively identifying critical failures missed by existing metrics.
DriveTok: 3D Driving Scene Tokenization for Unified Multi-View Reconstruction and Understanding
Mar 19, 2026With the growing adoption of vision-language-action models and world models in autonomous driving systems, scalable image tokenization becomes crucial as the interface for the visual modality. However, most existing tokenizers are designed for monocular and 2D scenes, leading to inefficiency and inter-view inconsistency when applied to high-resolution multi-view driving scenes. To address this, we propose DriveTok, an efficient 3D driving scene tokenizer for unified multi-view reconstruction and understanding. DriveTok first obtains semantically rich visual features from vision foundation models and then transforms them into the scene tokens with 3D deformable cross-attention. For decoding, we employ a multi-view transformer to reconstruct multi-view features from the scene tokens and use multiple heads to obtain RGB, depth, and semantic reconstructions. We also add a 3D head directly on the scene tokens for 3D semantic occupancy prediction for better spatial awareness. With the multiple training objectives, DriveTok learns unified scene tokens that integrate semantic, geometric, and textural information for efficient multi-view tokenization. Extensive experiments on the widely used nuScenes dataset demonstrate that the scene tokens from DriveTok perform well on image reconstruction, semantic segmentation, depth prediction, and 3D occupancy prediction tasks.
TwinRL-VLA: Digital Twin-Driven Reinforcement Learning for Real-World Robotic Manipulation
Feb 09, 2026Despite strong generalization capabilities, Vision-Language-Action (VLA) models remain constrained by the high cost of expert demonstrations and insufficient real-world interaction. While online reinforcement learning (RL) has shown promise in improving general foundation models, applying RL to VLA manipulation in real-world settings is still hindered by low exploration efficiency and a restricted exploration space. Through systematic real-world experiments, we observe that the effective exploration space of online RL is closely tied to the data distribution of supervised fine-tuning (SFT). Motivated by this observation, we propose TwinRL, a digital twin-real-world collaborative RL framework designed to scale and guide exploration for VLA models. First, a high-fidelity digital twin is efficiently reconstructed from smartphone-captured scenes, enabling realistic bidirectional transfer between real and simulated environments. During the SFT warm-up stage, we introduce an exploration space expansion strategy using digital twins to broaden the support of the data trajectory distribution. Building on this enhanced initialization, we propose a sim-to-real guided exploration strategy to further accelerate online RL. Specifically, TwinRL performs efficient and parallel online RL in the digital twin prior to deployment, effectively bridging the gap between offline and online training stages. Subsequently, we exploit efficient digital twin sampling to identify failure-prone yet informative configurations, which are used to guide targeted human-in-the-loop rollouts on the real robot. In our experiments, TwinRL approaches 100% success in both in-distribution regions covered by real-world demonstrations and out-of-distribution regions, delivering at least a 30% speedup over prior real-world RL methods and requiring only about 20 minutes on average across four tasks.
Moaw: Unleashing Motion Awareness for Video Diffusion Models
Jan 19, 2026Video diffusion models, trained on large-scale datasets, naturally capture correspondences of shared features across frames. Recent works have exploited this property for tasks such as optical flow prediction and tracking in a zero-shot setting. Motivated by these findings, we investigate whether supervised training can more fully harness the tracking capability of video diffusion models. To this end, we propose Moaw, a framework that unleashes motion awareness for video diffusion models and leverages it to facilitate motion transfer. Specifically, we train a diffusion model for motion perception, shifting its modality from image-to-video generation to video-to-dense-tracking. We then construct a motion-labeled dataset to identify features that encode the strongest motion information, and inject them into a structurally identical video generation model. Owing to the homogeneity between the two networks, these features can be naturally adapted in a zero-shot manner, enabling motion transfer without additional adapters. Our work provides a new paradigm for bridging generative modeling and motion understanding, paving the way for more unified and controllable video learning frameworks.
NeXT-IMDL: Build Benchmark for NeXT-Generation Image Manipulation Detection & Localization
Dec 29, 2025The accessibility surge and abuse risks of user-friendly image editing models have created an urgent need for generalizable, up-to-date methods for Image Manipulation Detection and Localization (IMDL). Current IMDL research typically uses cross-dataset evaluation, where models trained on one benchmark are tested on others. However, this simplified evaluation approach conceals the fragility of existing methods when handling diverse AI-generated content, leading to misleading impressions of progress. This paper challenges this illusion by proposing NeXT-IMDL, a large-scale diagnostic benchmark designed not just to collect data, but to probe the generalization boundaries of current detectors systematically. Specifically, NeXT-IMDL categorizes AIGC-based manipulations along four fundamental axes: editing models, manipulation types, content semantics, and forgery granularity. Built upon this, NeXT-IMDL implements five rigorous cross-dimension evaluation protocols. Our extensive experiments on 11 representative models reveal a critical insight: while these models perform well in their original settings, they exhibit systemic failures and significant performance degradation when evaluated under our designed protocols that simulate real-world, various generalization scenarios. By providing this diagnostic toolkit and the new findings, we aim to advance the development towards building truly robust, next-generation IMDL models.
DVGT: Driving Visual Geometry Transformer
Dec 18, 2025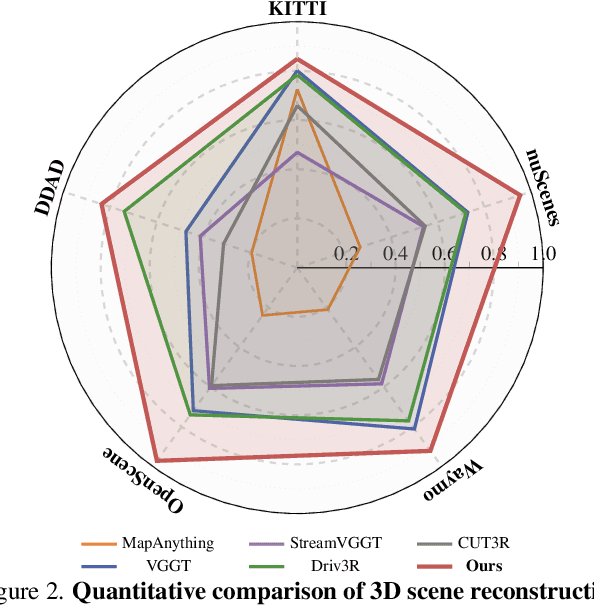
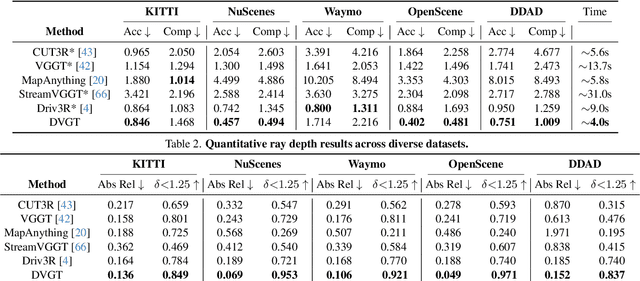
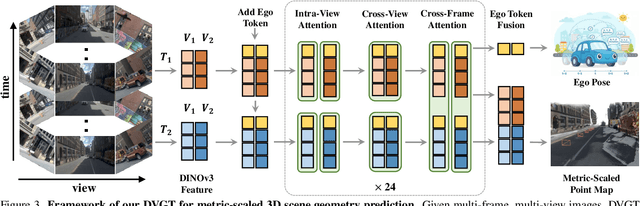
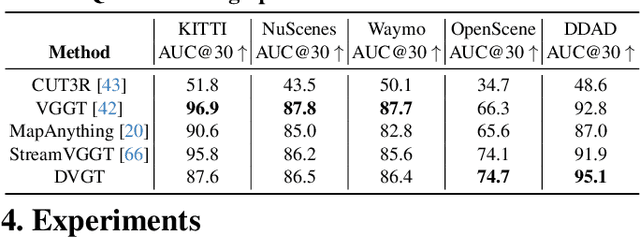
Perceiving and reconstructing 3D scene geometry from visual inputs is crucial for autonomous driving. However, there still lacks a driving-targeted dense geometry perception model that can adapt to different scenarios and camera configurations. To bridge this gap, we propose a Driving Visual Geometry Transformer (DVGT), which reconstructs a global dense 3D point map from a sequence of unposed multi-view visual inputs. We first extract visual features for each image using a DINO backbone, and employ alternating intra-view local attention, cross-view spatial attention, and cross-frame temporal attention to infer geometric relations across images. We then use multiple heads to decode a global point map in the ego coordinate of the first frame and the ego poses for each frame. Unlike conventional methods that rely on precise camera parameters, DVGT is free of explicit 3D geometric priors, enabling flexible processing of arbitrary camera configurations. DVGT directly predicts metric-scaled geometry from image sequences, eliminating the need for post-alignment with external sensors. Trained on a large mixture of driving datasets including nuScenes, OpenScene, Waymo, KITTI, and DDAD, DVGT significantly outperforms existing models on various scenarios. Code is available at https://github.com/wzzheng/DVGT.
SFTok: Bridging the Performance Gap in Discrete Tokenizers
Dec 18, 2025Recent advances in multimodal models highlight the pivotal role of image tokenization in high-resolution image generation. By compressing images into compact latent representations, tokenizers enable generative models to operate in lower-dimensional spaces, thereby improving computational efficiency and reducing complexity. Discrete tokenizers naturally align with the autoregressive paradigm but still lag behind continuous ones, limiting their adoption in multimodal systems. To address this, we propose \textbf{SFTok}, a discrete tokenizer that incorporates a multi-step iterative mechanism for precise reconstruction. By integrating \textbf{self-forcing guided visual reconstruction} and \textbf{debias-and-fitting training strategy}, SFTok resolves the training-inference inconsistency in multi-step process, significantly enhancing image reconstruction quality. At a high compression rate of only 64 tokens per image, SFTok achieves state-of-the-art reconstruction quality on ImageNet (rFID = 1.21) and demonstrates exceptional performance in class-to-image generation tasks (gFID = 2.29).