 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWow, wo, val! A Comprehensive Embodied World Model Evaluation Turing Test
Jan 07, 2026As world models gain momentum in Embodied AI, an increasing number of works explore using video foundation models as predictive world models for downstream embodied tasks like 3D prediction or interactive generation. However, before exploring these downstream tasks, video foundation models still have two critical questions unanswered: (1) whether their generative generalization is sufficient to maintain perceptual fidelity in the eyes of human observers, and (2) whether they are robust enough to serve as a universal prior for real-world embodied agents. To provide a standardized framework for answering these questions, we introduce the Embodied Turing Test benchmark: WoW-World-Eval (Wow,wo,val). Building upon 609 robot manipulation data, Wow-wo-val examines five core abilities, including perception, planning, prediction, generalization, and execution. We propose a comprehensive evaluation protocol with 22 metrics to assess the models' generation ability, which achieves a high Pearson Correlation between the overall score and human preference (>0.93) and establishes a reliable foundation for the Human Turing Test. On Wow-wo-val, models achieve only 17.27 on long-horizon planning and at best 68.02 on physical consistency, indicating limited spatiotemporal consistency and physical reasoning. For the Inverse Dynamic Model Turing Test, we first use an IDM to evaluate the video foundation models' execution accuracy in the real world. However, most models collapse to $\approx$ 0% success, while WoW maintains a 40.74% success rate. These findings point to a noticeable gap between the generated videos and the real world, highlighting the urgency and necessity of benchmarking World Model in Embodied AI.
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
OmniIndoor3D: Comprehensive Indoor 3D Reconstruction
May 27, 2025We propose a novel framework for comprehensive indoor 3D reconstruction using Gaussian representations, called OmniIndoor3D. This framework enables accurate appearance, geometry, and panoptic reconstruction of diverse indoor scenes captured by a consumer-level RGB-D camera. Since 3DGS is primarily optimized for photorealistic rendering, it lacks the precise geometry critical for high-quality panoptic reconstruction. Therefore, OmniIndoor3D first combines multiple RGB-D images to create a coarse 3D reconstruction, which is then used to initialize the 3D Gaussians and guide the 3DGS training. To decouple the optimization conflict between appearance and geometry, we introduce a lightweight MLP that adjusts the geometric properties of 3D Gaussians. The introduced lightweight MLP serves as a low-pass filter for geometry reconstruction and significantly reduces noise in indoor scenes. To improve the distribution of Gaussian primitives, we propose a densification strategy guided by panoptic priors to encourage smoothness on planar surfaces. Through the joint optimization of appearance, geometry, and panoptic reconstruction, OmniIndoor3D provides comprehensive 3D indoor scene understanding, which facilitates accurate and robust robotic navigation. We perform thorough evaluations across multiple datasets, and OmniIndoor3D achieves state-of-the-art results in appearance, geometry, and panoptic reconstruction. We believe our work bridges a critical gap in indoor 3D reconstruction. The code will be released at: https://ucwxb.github.io/OmniIndoor3D/
MixedGaussianAvatar: Realistically and Geometrically Accurate Head Avatar via Mixed 2D-3D Gaussian Splatting
Dec 06, 2024



Reconstructing high-fidelity 3D head avatars is crucial in various applications such as virtual reality. The pioneering methods reconstruct realistic head avatars with Neural Radiance Fields (NeRF), which have been limited by training and rendering speed. Recent methods based on 3D Gaussian Splatting (3DGS) significantly improve the efficiency of training and rendering. However, the surface inconsistency of 3DGS results in subpar geometric accuracy; later, 2DGS uses 2D surfels to enhance geometric accuracy at the expense of rendering fidelity. To leverage the benefits of both 2DGS and 3DGS, we propose a novel method named MixedGaussianAvatar for realistically and geometrically accurate head avatar reconstruction. Our main idea is to utilize 2D Gaussians to reconstruct the surface of the 3D head, ensuring geometric accuracy. We attach the 2D Gaussians to the triangular mesh of the FLAME model and connect additional 3D Gaussians to those 2D Gaussians where the rendering quality of 2DGS is inadequate, creating a mixed 2D-3D Gaussian representation. These 2D-3D Gaussians can then be animated using FLAME parameters. We further introduce a progressive training strategy that first trains the 2D Gaussians and then fine-tunes the mixed 2D-3D Gaussians. We demonstrate the superiority of MixedGaussianAvatar through comprehensive experiments. The code will be released at: https://github.com/ChenVoid/MGA/.
EMD: Explicit Motion Modeling for High-Quality Street Gaussian Splatting
Nov 23, 2024



Photorealistic reconstruction of street scenes is essential for developing real-world simulators in autonomous driving. While recent methods based on 3D/4D Gaussian Splatting (GS) have demonstrated promising results, they still encounter challenges in complex street scenes due to the unpredictable motion of dynamic objects. Current methods typically decompose street scenes into static and dynamic objects, learning the Gaussians in either a supervised manner (e.g., w/ 3D bounding-box) or a self-supervised manner (e.g., w/o 3D bounding-box). However, these approaches do not effectively model the motions of dynamic objects (e.g., the motion speed of pedestrians is clearly different from that of vehicles), resulting in suboptimal scene decomposition. To address this, we propose Explicit Motion Decomposition (EMD), which models the motions of dynamic objects by introducing learnable motion embeddings to the Gaussians, enhancing the decomposition in street scenes. The proposed EMD is a plug-and-play approach applicable to various baseline methods. We also propose tailored training strategies to apply EMD to both supervised and self-supervised baselines. Through comprehensive experimentation, we illustrate the effectiveness of our approach with various established baselines. The code will be released at: https://qingpowuwu.github.io/emdgaussian.github.io/.
Implicit Neural Image Field for Biological Microscopy Image Compression
May 29, 2024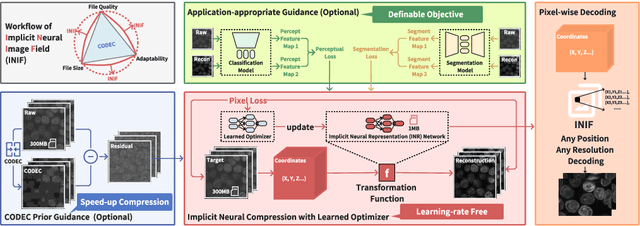


The rapid pace of innovation in biological microscopy imaging has led to large images, putting pressure on data storage and impeding efficient sharing, management, and visualization. This necessitates the development of efficient compression solutions. Traditional CODEC methods struggle to adapt to the diverse bioimaging data and often suffer from sub-optimal compression. In this study, we propose an adaptive compression workflow based on Implicit Neural Representation (INR). This approach permits application-specific compression objectives, capable of compressing images of any shape and arbitrary pixel-wise decompression. We demonstrated on a wide range of microscopy images from real applications that our workflow not only achieved high, controllable compression ratios (e.g., 512x) but also preserved detailed information critical for downstream analysis.