 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cognitive-Mechanistic Human Reliability Analysis Framework: A Nuclear Power Plant Case Study
Apr 25, 2025Traditional human reliability analysis (HRA) methods, such as IDHEAS-ECA, rely on expert judgment and empirical rules that often overlook the cognitive underpinnings of human error. Moreover, conducting human-in-the-loop experiments for advanced nuclear power plants is increasingly impractical due to novel interfaces and limited operational data. This study proposes a cognitive-mechanistic framework (COGMIF) that enhances the IDHEAS-ECA methodology by integrating an ACT-R-based human digital twin (HDT) with TimeGAN-augmented simulation. The ACT-R model simulates operator cognition, including memory retrieval, goal-directed procedural reasoning, and perceptual-motor execution, under high-fidelity scenarios derived from a high-temperature gas-cooled reactor (HTGR) simulator. To overcome the resource constraints of large-scale cognitive modeling, TimeGAN is trained on ACT-R-generated time-series data to produce high-fidelity synthetic operator behavior datasets. These simulations are then used to drive IDHEAS-ECA assessments, enabling scalable, mechanism-informed estimation of human error probabilities (HEPs). Comparative analyses with SPAR-H and sensitivity assessments demonstrate the robustness and practical advantages of the proposed COGMIF. Finally, procedural features are mapped onto a Bayesian network to quantify the influence of contributing factors, revealing key drivers of operational risk. This work offers a credible and computationally efficient pathway to integrate cognitive theory into industrial HRA practices.
KRAIL: A Knowledge-Driven Framework for Base Human Reliability Analysis Integrating IDHEAS and Large Language Models
Dec 20, 2024Human reliability analysis (HRA) is crucial for evaluating and improving the safety of complex systems. Recent efforts have focused on estimating human error probability (HEP), but existing methods often rely heavily on expert knowledge,which can be subjective and time-consuming. Inspired by the success of large language models (LLMs) in natural language processing, this paper introduces a novel two-stage framework for knowledge-driven reliability analysis, integrating IDHEAS and LLMs (KRAIL). This innovative framework enables the semi-automated computation of base HEP values. Additionally, knowledge graphs are utilized as a form of retrieval-augmented generation (RAG) for enhancing the framework' s capability to retrieve and process relevant data efficiently. Experiments are systematically conducted and evaluated on authoritative datasets of human reliability. The experimental results of the proposed methodology demonstrate its superior performance on base HEP estimation under partial information for reliability assessment.
A Hybrid Real-Time Framework for Efficient Fussell-Vesely Importance Evaluation Using Virtual Fault Trees and Graph Neural Networks
Dec 13, 2024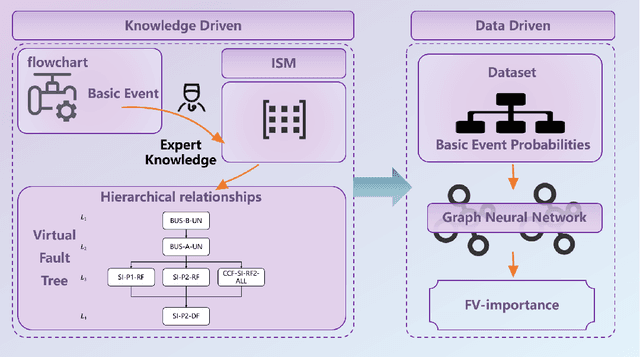



The Fussell-Vesely Importance (FV) reflects the potential impact of a basic event on system failure, and is crucial for ensuring system reliability. However, traditional methods for calculating FV importance are complex and time-consuming, requiring the construction of fault trees and the calculation of minimal cut set. To address these limitations, this study proposes a hybrid real-time framework to evaluate the FV importance of basic events. Our framework combines expert knowledge with a data-driven model. First, we use Interpretive Structural Modeling (ISM) to build a virtual fault tree that captures the relationships between basic events. Unlike traditional fault trees, which include intermediate events, our virtual fault tree consists solely of basic events, reducing its complexity and space requirements. Additionally, our virtual fault tree considers the dependencies between basic events rather than assuming their independence, as is typically done in traditional fault trees. We then feed both the event relationships and relevant data into a graph neural network (GNN). This approach enables a rapid, data-driven calculation of FV importance, significantly reducing processing time and quickly identifying critical events, thus providing robust decision support for risk control. Results demonstrate that our model performs well in terms of MSE, RMSE, MAE, and R2, reducing computational energy consumption and offering real-time, risk-informed decision support for complex systems.
MixedGaussianAvatar: Realistically and Geometrically Accurate Head Avatar via Mixed 2D-3D Gaussian Splatting
Dec 06, 2024



Reconstructing high-fidelity 3D head avatars is crucial in various applications such as virtual reality. The pioneering methods reconstruct realistic head avatars with Neural Radiance Fields (NeRF), which have been limited by training and rendering speed. Recent methods based on 3D Gaussian Splatting (3DGS) significantly improve the efficiency of training and rendering. However, the surface inconsistency of 3DGS results in subpar geometric accuracy; later, 2DGS uses 2D surfels to enhance geometric accuracy at the expense of rendering fidelity. To leverage the benefits of both 2DGS and 3DGS, we propose a novel method named MixedGaussianAvatar for realistically and geometrically accurate head avatar reconstruction. Our main idea is to utilize 2D Gaussians to reconstruct the surface of the 3D head, ensuring geometric accuracy. We attach the 2D Gaussians to the triangular mesh of the FLAME model and connect additional 3D Gaussians to those 2D Gaussians where the rendering quality of 2DGS is inadequate, creating a mixed 2D-3D Gaussian representation. These 2D-3D Gaussians can then be animated using FLAME parameters. We further introduce a progressive training strategy that first trains the 2D Gaussians and then fine-tunes the mixed 2D-3D Gaussians. We demonstrate the superiority of MixedGaussianAvatar through comprehensive experiments. The code will be released at: https://github.com/ChenVoid/MGA/.
DiffusionTalker: Personalization and Acceleration for Speech-Driven 3D Face Diffuser
Dec 02, 2023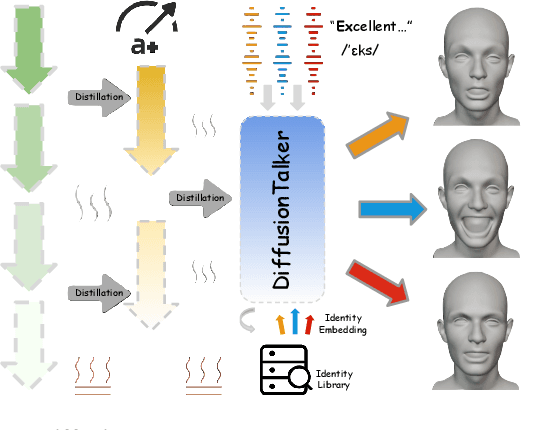
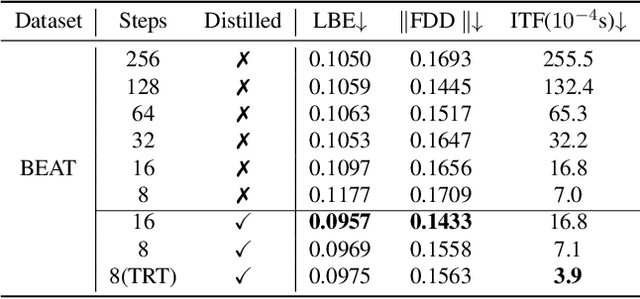
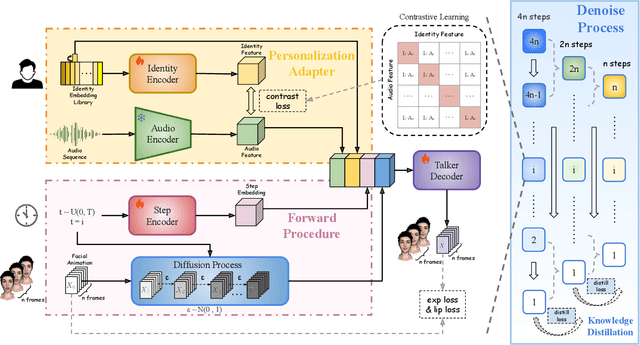
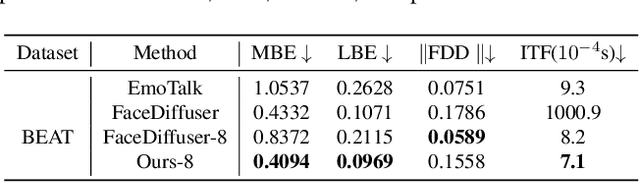
Speech-driven 3D facial animation has been an attractive task in both academia and industry. Traditional methods mostly focus on learning a deterministic mapping from speech to animation. Recent approaches start to consider the non-deterministic fact of speech-driven 3D face animation and employ the diffusion model for the task. However, personalizing facial animation and accelerating animation generation are still two major limitations of existing diffusion-based methods. To address the above limitations, we propose DiffusionTalker, a diffusion-based method that utilizes contrastive learning to personalize 3D facial animation and knowledge distillation to accelerate 3D animation generation. Specifically, to enable personalization, we introduce a learnable talking identity to aggregate knowledge in audio sequences. The proposed identity embeddings extract customized facial cues across different people in a contrastive learning manner. During inference, users can obtain personalized facial animation based on input audio, reflecting a specific talking style. With a trained diffusion model with hundreds of steps, we distill it into a lightweight model with 8 steps for acceleration. Extensive experiments are conducted to demonstrate that our method outperforms state-of-the-art methods. The code will be released.