 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAM4D: Fast 4D World Action Model via Spatial Register Tokens
Jun 12, 2026World action models (WAMs) have recently shown promise in jointly modeling future observations and executable robot actions. However, most existing WAMs still operate in 2D video or latent spaces, where visually plausible rollouts miss the 3D spatial constraints and occluded contact geometry required for precise manipulation. While geometric foundation models offer strong priors for recovering dense 3D structure and motion from visual observations, forcing WAMs to predict the dense 4D representation introduces costly geometric decoding and slows down causal action generation. To address the trade-off, we present WAM4D, a fast 4D world action model that uses lightweight spatial register tokens as training-time future-depth readouts to transfer pretrained geometric priors into a causal video-action transformer, then removes the register branch for lightweight action inference. To prevent non-causal shortcuts, we further design causal mixture attention for the Mixture-of-Transformers (MoT) WAM backbone, defining modality-specific visibility among video, action, and geometry tokens. Comprehensive experiments on RoboTwin 2.0 and challenging real-world manipulation tasks show that WAM4D improves spatial consistency and achieves competitive action prediction while maintaining efficient inference.
GraspFoM: Towards Reconstruction-Driven Robotic Grasping with 3D Foundation Priors
Jun 07, 2026Robotic grasping is a fundamental capability in robotic manipulation. Yet grasping remains challenging under partial observations. Reliable grasping depends on both local contact cues and object-level 3D structure. Existing geometry-aware grasping methods recognize the value of reconstruction, but they typically treat geometry as an intermediate prediction rather than a reusable object prior for grasping. In this paper, we present GraspFoM, a unified framework that leverages 3D foundation priors (SAM3D) to build a shared 3D object latent for both reconstruction and grasp pose prediction. Built on this shared object latent, we introduce an anchor-initialized truncated pose-reasoning diffuser that predicts continuous and multimodal grasp poses without directly relying on discrete grasp candidates. We further investigate the interaction between reconstruction and grasping through a reconstruction-aware scorer and a residual latent updater. Reconstruction provides grounded geometric cues, while grasp supervision refines the shared object latent toward grasp-relevant affordances. GraspFoM jointly predicts grasp poses and reconstructs high-fidelity 3D assets in mesh and 3DGS forms. Comprehensive experiments demonstrate that GraspFoM achieves state-of-the-art results on both reconstruction and grasping. Notably, these improvements require only a small number of additional trainable parameters. Component-wise ablation studies also demonstrate the contribution of each component.
SparseStreet: Sparse Gaussian Splatting for Real-Time Street Scene Simulation
Jun 02, 2026While 3D Gaussian Splatting has shown promising results in street scene reconstruction, existing methods require massive numbers of Gaussian primitives to capture fine details, leading to prohibitive storage costs and slow rendering speeds. We observe that dynamic objects (e.g., vehicles and pedestrians) demand high-fidelity representations to maintain temporal consistency, while static background regions often contain substantial redundancy. Motivated by this, we propose SparseStreet, a general compression framework specifically designed for street scenes. First, we introduce a node-based learnable pruning strategy that systematically removes low-contributing Gaussian primitives while preserving visually critical regions. Second, after the scene representation stabilizes, we apply background compression, further reducing redundancy in static regions. Our method effectively preserves the geometry and appearance of dynamic objects while significantly reducing the total number of Gaussian primitives. Extensive experiments on the Waymo and nuScenes demonstrate that SparseStreet achieves up to 80% compression ratio with minimal quality degradation, enabling resource-efficient, high-fidelity dynamic scene reconstruction. Project website: https://sparsestreet.github.io/.
Feed-Forward Gaussian Splatting from Sparse Aerial Views
May 19, 2026Reconstructing large-scale urban scenes from sparse aerial views is a crucial yet challenging task. Due to biased top-down and shallow-oblique camera poses, sparse aerial captures exhibit strong evidence imbalance: roofs and open regions are repeatedly observed, while facades, distant buildings, and occluded structures receive little multi-view support. Existing feed-forward 3D Gaussian Splatting methods directly regress a deterministic representation from sparse inputs, but this often leads to ghosting, melted facades, and stretched textures. Recent pseudo-view and video-based generative reconstruction methods use additional supervision or generative priors. However, they often lack a clear separation between observed geometry and prior-driven content, which can lead to plausible but inconsistent structures. We propose AnyCity, an observation-grounded generative reconstruction framework for sparse aerial urban scenes. AnyCity first predicts an observation-supported geometry latent to anchor reliable structures, and then uses scaffold-conditioned aerial completion tokens to predict a gated residual update for weakly constrained content before Gaussian decoding. During training, dense-to-sparse distillation transfers structural cues from dense-view reconstruction, while an aerial-adapted video diffusion prior provides fine-grained urban appearance cues through gated token conditioning. Observation-preserving objectives keep the refined representation consistent with input-supported geometry. At inference time, AnyCity reconstructs the final 3D Gaussian scene from sparse aerial views in a single feed-forward pass, achieving coherent urban novel-view synthesis with second-level inference. Experiments on synthetic, aerial-domain, UAV-textured, and real-world scenes show consistent improvements over feed-forward baselines.
VEGA: Visual Encoder Grounding Alignment for Spatially-Aware Vision-Language-Action Models
May 11, 2026Precise spatial reasoning is fundamental to robotic manipulation, yet the visual backbones of current vision-language-action (VLA) models are predominantly pretrained on 2D image data without explicit 3D geometric supervision, resulting in representations that lack accurate spatial awareness. Existing implicit spatial grounding methods partially address this by aligning VLA features with those of 3D-aware foundation models, but they rely on empirical layer search and perform alignment on LLM-level visual tokens where spatial structure has already been entangled with linguistic semantics, limiting both generalizability and geometric interpretability. We propose VEGA (Visual Encoder Grounding Alignment), a simple yet effective framework that directly aligns the output of the VLA's visual encoder with spatially-aware features from DINOv2-FiT3D, a DINOv2 model fine-tuned with multi-view consistent 3D Gaussian Splatting supervision. By performing alignment at the visual encoder output level, VEGA grounds spatial awareness before any linguistic entanglement occurs, offering a more interpretable and principled alignment target. The alignment is implemented via a lightweight projector trained with a cosine similarity loss alongside the standard action prediction objective, and is discarded at inference time, introducing no additional computational overhead. Extensive experiments on simulation benchmark and real-world manipulation tasks demonstrate that VEGA consistently outperforms existing implicit spatial grounding baselines, establishing a new state-of-the-art among implicit spatial grounding methods for VLA models.
PhyMix: Towards Physically Consistent Single-Image 3D Indoor Scene Generation with Implicit--Explicit Optimization
Apr 11, 2026Existing single-image 3D indoor scene generators often produce results that look visually plausible but fail to obey real-world physics, limiting their reliability in robotics, embodied AI, and design. To examine this gap, we introduce a unified Physics Evaluator that measures four main aspects: geometric priors, contact, stability, and deployability, which are further decomposed into nine sub-constraints, establishing the first benchmark to measure physical consistency. Based on this evaluator, our analysis shows that state-of-the-art methods remain largely physics-unaware. To overcome this limitation, we further propose a framework that integrates feedback from the Physics Evaluator into both training and inference, enhancing the physical plausibility of generated scenes. Specifically, we propose PhyMix, which is composed of two complementary components: (i) implicit alignment via Scene-GRPO, a critic-free group-relative policy optimization that leverages the Physics Evaluator as a preference signal and biases sampling towards physically feasible layouts, and (ii) explicit refinement via a plug-and-play Test-Time Optimizer (TTO) that uses differentiable evaluator signals to correct residual violations during generation. Overall, our method unifies evaluation, reward shaping, and inference-time correction, producing 3D indoor scenes that are visually faithful and physically plausible. Extensive synthetic evaluations confirm state-of-the-art performance in both visual fidelity and physical plausibility, and extensive qualitative examples in stylized and real-world images further showcase the robustness of the method. We will release codes and models upon publication.
EvoDriveVLA: Evolving Autonomous Driving Vision-Language-Action Model via Collaborative Perception-Planning Distillation
Mar 10, 2026Vision-Language-Action models have shown great promise for autonomous driving, yet they suffer from degraded perception after unfreezing the visual encoder and struggle with accumulated instability in long-term planning. To address these challenges, we propose EvoDriveVLA-a novel collaborative perception-planning distillation framework that integrates self-anchored perceptual constraints and oracle-guided trajectory optimization. Specifically, self-anchored visual distillation leverages self-anchor teacher to deliver visual anchoring constraints, regularizing student representations via trajectory-guided key-region awareness. In parallel, oracle-guided trajectory distillation employs a future-aware oracle teacher with coarse-to-fine trajectory refinement and Monte Carlo dropout sampling to produce high-quality trajectory candidates, thereby selecting the optimal trajectory to guide the student's prediction. EvoDriveVLA achieves SOTA performance in open-loop evaluation and significantly enhances performance in closed-loop evaluation. Our code is available at: https://github.com/hey-cjj/EvoDriveVLA.
RSATalker: Realistic Socially-Aware Talking Head Generation for Multi-Turn Conversation
Jan 15, 2026Talking head generation is increasingly important in virtual reality (VR), especially for social scenarios involving multi-turn conversation. Existing approaches face notable limitations: mesh-based 3D methods can model dual-person dialogue but lack realistic textures, while large-model-based 2D methods produce natural appearances but incur prohibitive computational costs. Recently, 3D Gaussian Splatting (3DGS) based methods achieve efficient and realistic rendering but remain speaker-only and ignore social relationships. We introduce RSATalker, the first framework that leverages 3DGS for realistic and socially-aware talking head generation with support for multi-turn conversation. Our method first drives mesh-based 3D facial motion from speech, then binds 3D Gaussians to mesh facets to render high-fidelity 2D avatar videos. To capture interpersonal dynamics, we propose a socially-aware module that encodes social relationships, including blood and non-blood as well as equal and unequal, into high-level embeddings through a learnable query mechanism. We design a three-stage training paradigm and construct the RSATalker dataset with speech-mesh-image triplets annotated with social relationships. Extensive experiments demonstrate that RSATalker achieves state-of-the-art performance in both realism and social awareness. The code and dataset will be released.
ParkGaussian: Surround-view 3D Gaussian Splatting for Autonomous Parking
Jan 04, 2026Parking is a critical task for autonomous driving systems (ADS), with unique challenges in crowded parking slots and GPS-denied environments. However, existing works focus on 2D parking slot perception, mapping, and localization, 3D reconstruction remains underexplored, which is crucial for capturing complex spatial geometry in parking scenarios. Naively improving the visual quality of reconstructed parking scenes does not directly benefit autonomous parking, as the key entry point for parking is the slots perception module. To address these limitations, we curate the first benchmark named ParkRecon3D, specifically designed for parking scene reconstruction. It includes sensor data from four surround-view fisheye cameras with calibrated extrinsics and dense parking slot annotations. We then propose ParkGaussian, the first framework that integrates 3D Gaussian Splatting (3DGS) for parking scene reconstruction. To further improve the alignment between reconstruction and downstream parking slot detection, we introduce a slot-aware reconstruction strategy that leverages existing parking perception methods to enhance the synthesis quality of slot regions. Experiments on ParkRecon3D demonstrate that ParkGaussian achieves state-of-the-art reconstruction quality and better preserves perception consistency for downstream tasks. The code and dataset will be released at: https://github.com/wm-research/ParkGaussian
PIGEON: VLM-Driven Object Navigation via Points of Interest Selection
Nov 17, 2025
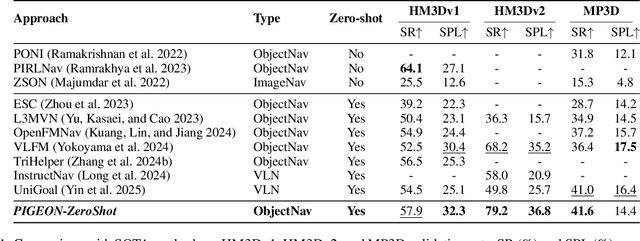

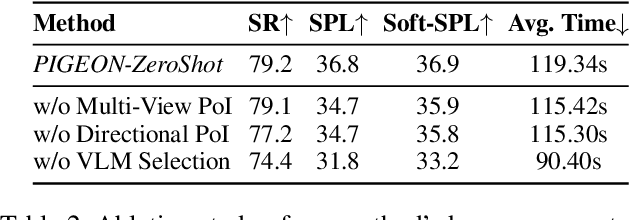
Navigating to a specified object in an unknown environment is a fundamental yet challenging capability of embodied intelligence. However, current methods struggle to balance decision frequency with intelligence, resulting in decisions lacking foresight or discontinuous actions. In this work, we propose PIGEON: Point of Interest Guided Exploration for Object Navigation with VLM, maintaining a lightweight and semantically aligned snapshot memory during exploration as semantic input for the exploration strategy. We use a large Visual-Language Model (VLM), named PIGEON-VL, to select Points of Interest (PoI) formed during exploration and then employ a lower-level planner for action output, increasing the decision frequency. Additionally, this PoI-based decision-making enables the generation of Reinforcement Learning with Verifiable Reward (RLVR) data suitable for simulators. Experiments on classic object navigation benchmarks demonstrate that our zero-shot transfer method achieves state-of-the-art performance, while RLVR further enhances the model's semantic guidance capabilities, enabling deep reasoning during real-time navigation.