 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearch on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
MirrorMark: A Distortion-Free Multi-Bit Watermark for Large Language Models
Jan 29, 2026As large language models (LLMs) become integral to applications such as question answering and content creation, reliable content attribution has become increasingly important. Watermarking is a promising approach, but existing methods either provide only binary signals or distort the sampling distribution, degrading text quality; distortion-free approaches, in turn, often suffer from weak detectability or robustness. We propose MirrorMark, a multi-bit and distortion-free watermark for LLMs. By mirroring sampling randomness in a measure-preserving manner, MirrorMark embeds multi-bit messages without altering the token probability distribution, preserving text quality by design. To improve robustness, we introduce a context-based scheduler that balances token assignments across message positions while remaining resilient to insertions and deletions. We further provide a theoretical analysis of the equal error rate to interpret empirical performance. Experiments show that MirrorMark matches the text quality of non-watermarked generation while achieving substantially stronger detectability: with 54 bits embedded in 300 tokens, it improves bit accuracy by 8-12% and correctly identifies up to 11% more watermarked texts at 1% false positive rate.
Rethinking Driving World Model as Synthetic Data Generator for Perception Tasks
Oct 22, 2025Recent advancements in driving world models enable controllable generation of high-quality RGB videos or multimodal videos. Existing methods primarily focus on metrics related to generation quality and controllability. However, they often overlook the evaluation of downstream perception tasks, which are $\mathbf{really\ crucial}$ for the performance of autonomous driving. Existing methods usually leverage a training strategy that first pretrains on synthetic data and finetunes on real data, resulting in twice the epochs compared to the baseline (real data only). When we double the epochs in the baseline, the benefit of synthetic data becomes negligible. To thoroughly demonstrate the benefit of synthetic data, we introduce Dream4Drive, a novel synthetic data generation framework designed for enhancing the downstream perception tasks. Dream4Drive first decomposes the input video into several 3D-aware guidance maps and subsequently renders the 3D assets onto these guidance maps. Finally, the driving world model is fine-tuned to produce the edited, multi-view photorealistic videos, which can be used to train the downstream perception models. Dream4Drive enables unprecedented flexibility in generating multi-view corner cases at scale, significantly boosting corner case perception in autonomous driving. To facilitate future research, we also contribute a large-scale 3D asset dataset named DriveObj3D, covering the typical categories in driving scenarios and enabling diverse 3D-aware video editing. We conduct comprehensive experiments to show that Dream4Drive can effectively boost the performance of downstream perception models under various training epochs. Project: $\href{https://wm-research.github.io/Dream4Drive/}{this\ https\ URL}$
StealthInk: A Multi-bit and Stealthy Watermark for Large Language Models
Jun 05, 2025
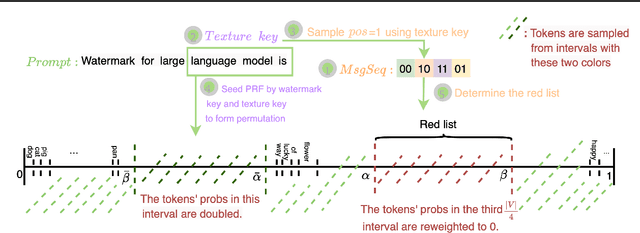
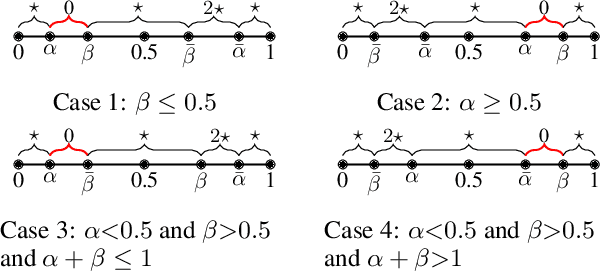
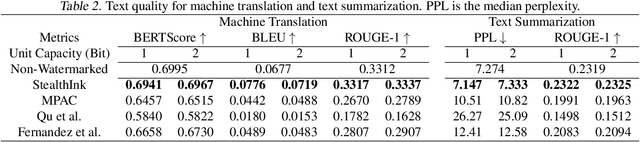
Watermarking for large language models (LLMs) offers a promising approach to identifying AI-generated text. Existing approaches, however, either compromise the distribution of original generated text by LLMs or are limited to embedding zero-bit information that only allows for watermark detection but ignores identification. We present StealthInk, a stealthy multi-bit watermarking scheme that preserves the original text distribution while enabling the embedding of provenance data, such as userID, TimeStamp, and modelID, within LLM-generated text. This enhances fast traceability without requiring access to the language model's API or prompts. We derive a lower bound on the number of tokens necessary for watermark detection at a fixed equal error rate, which provides insights on how to enhance the capacity. Comprehensive empirical evaluations across diverse tasks highlight the stealthiness, detectability, and resilience of StealthInk, establishing it as an effective solution for LLM watermarking applications.
Is Artificial Intelligence Generated Image Detection a Solved Problem?
May 18, 2025



The rapid advancement of generative models, such as GANs and Diffusion models, has enabled the creation of highly realistic synthetic images, raising serious concerns about misinformation, deepfakes, and copyright infringement. Although numerous Artificial Intelligence Generated Image (AIGI) detectors have been proposed, often reporting high accuracy, their effectiveness in real-world scenarios remains questionable. To bridge this gap, we introduce AIGIBench, a comprehensive benchmark designed to rigorously evaluate the robustness and generalization capabilities of state-of-the-art AIGI detectors. AIGIBench simulates real-world challenges through four core tasks: multi-source generalization, robustness to image degradation, sensitivity to data augmentation, and impact of test-time pre-processing. It includes 23 diverse fake image subsets that span both advanced and widely adopted image generation techniques, along with real-world samples collected from social media and AI art platforms. Extensive experiments on 11 advanced detectors demonstrate that, despite their high reported accuracy in controlled settings, these detectors suffer significant performance drops on real-world data, limited benefits from common augmentations, and nuanced effects of pre-processing, highlighting the need for more robust detection strategies. By providing a unified and realistic evaluation framework, AIGIBench offers valuable insights to guide future research toward dependable and generalizable AIGI detection.
Gaussian Shading++: Rethinking the Realistic Deployment Challenge of Performance-Lossless Image Watermark for Diffusion Models
Apr 21, 2025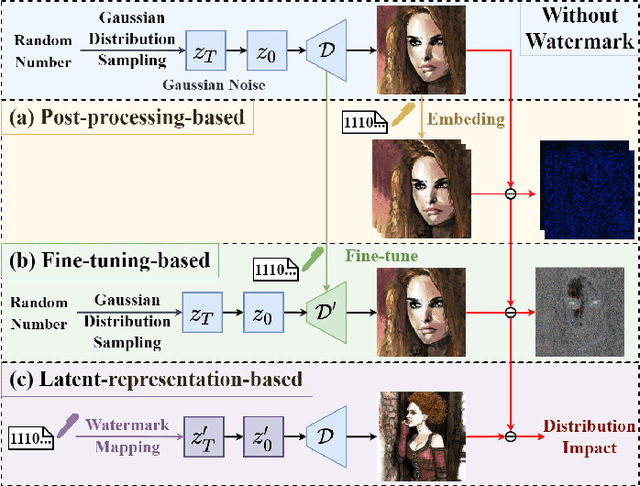


Ethical concerns surrounding copyright protection and inappropriate content generation pose challenges for the practical implementation of diffusion models. One effective solution involves watermarking the generated images. Existing methods primarily focus on ensuring that watermark embedding does not degrade the model performance. However, they often overlook critical challenges in real-world deployment scenarios, such as the complexity of watermark key management, user-defined generation parameters, and the difficulty of verification by arbitrary third parties. To address this issue, we propose Gaussian Shading++, a diffusion model watermarking method tailored for real-world deployment. We propose a double-channel design that leverages pseudorandom error-correcting codes to encode the random seed required for watermark pseudorandomization, achieving performance-lossless watermarking under a fixed watermark key and overcoming key management challenges. Additionally, we model the distortions introduced during generation and inversion as an additive white Gaussian noise channel and employ a novel soft decision decoding strategy during extraction, ensuring strong robustness even when generation parameters vary. To enable third-party verification, we incorporate public key signatures, which provide a certain level of resistance against forgery attacks even when model inversion capabilities are fully disclosed. Extensive experiments demonstrate that Gaussian Shading++ not only maintains performance losslessness but also outperforms existing methods in terms of robustness, making it a more practical solution for real-world deployment.
Concept-as-Tree: Synthetic Data is All You Need for VLM Personalization
Mar 17, 2025Vision-Language Models (VLMs) have demonstrated exceptional performance in various multi-modal tasks. Recently, there has been an increasing interest in improving the personalization capabilities of VLMs. To better integrate user-provided concepts into VLMs, many methods use positive and negative samples to fine-tune these models. However, the scarcity of user-provided positive samples and the low quality of retrieved negative samples pose challenges for fine-tuning. To reveal the relationship between sample and model performance, we systematically investigate the impact of positive and negative samples (easy and hard) and their diversity on VLM personalization tasks. Based on the detailed analysis, we introduce Concept-as-Tree (CaT), which represents a concept as a tree structure, thereby enabling the data generation of positive and negative samples with varying difficulty and diversity for VLM personalization. With a well-designed data filtering strategy, our CaT framework can ensure the quality of generated data, constituting a powerful pipeline. We perform thorough experiments with various VLM personalization baselines to assess the effectiveness of the pipeline, alleviating the lack of positive samples and the low quality of negative samples. Our results demonstrate that CaT equipped with the proposed data filter significantly enhances the personalization capabilities of VLMs across the MyVLM, Yo'LLaVA, and MC-LLaVA datasets. To our knowledge, this work is the first controllable synthetic data pipeline for VLM personalization. The code is released at \href{https://github.com/zengkaiya/CaT}{https://github.com/zengkaiya/CaT}.
Novel Object 6D Pose Estimation with a Single Reference View
Mar 07, 2025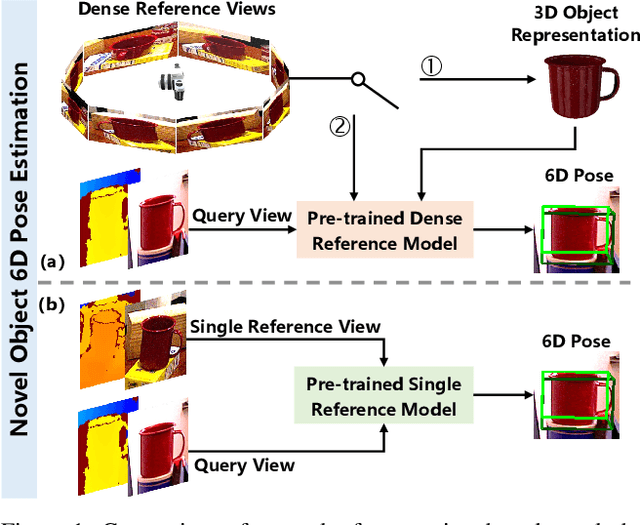
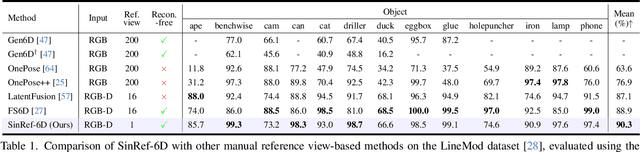
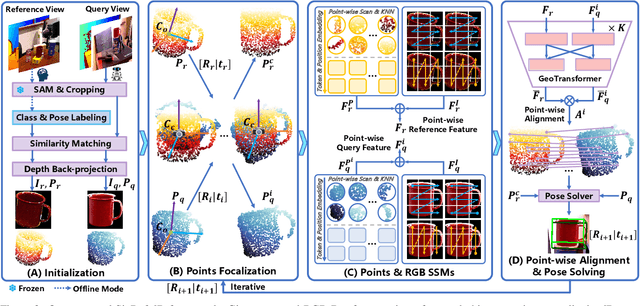
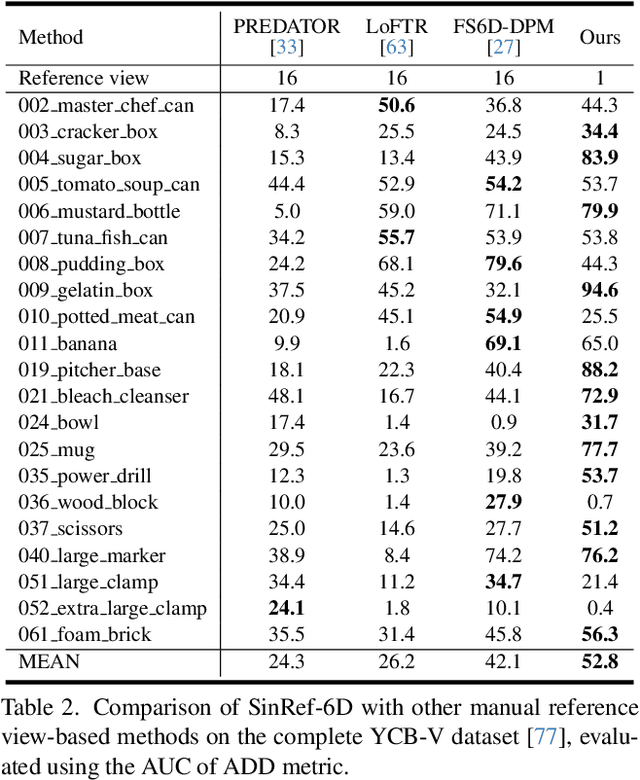
Existing novel object 6D pose estimation methods typically rely on CAD models or dense reference views, which are both difficult to acquire. Using only a single reference view is more scalable, but challenging due to large pose discrepancies and limited geometric and spatial information. To address these issues, we propose a Single-Reference-based novel object 6D (SinRef-6D) pose estimation method. Our key idea is to iteratively establish point-wise alignment in the camera coordinate system based on state space models (SSMs). Specifically, iterative camera-space point-wise alignment can effectively handle large pose discrepancies, while our proposed RGB and Points SSMs can capture long-range dependencies and spatial information from a single view, offering linear complexity and superior spatial modeling capability. Once pre-trained on synthetic data, SinRef-6D can estimate the 6D pose of a novel object using only a single reference view, without requiring retraining or a CAD model. Extensive experiments on six popular datasets and real-world robotic scenes demonstrate that we achieve on-par performance with CAD-based and dense reference view-based methods, despite operating in the more challenging single reference setting. Code will be released at https://github.com/CNJianLiu/SinRef-6D.
MC-LLaVA: Multi-Concept Personalized Vision-Language Model
Nov 18, 2024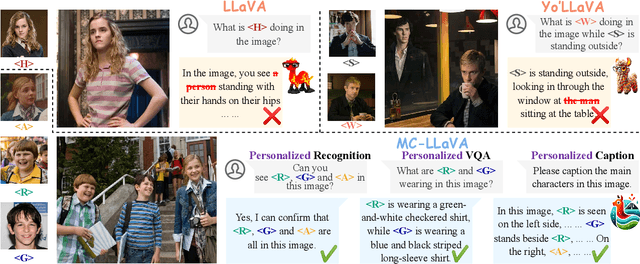

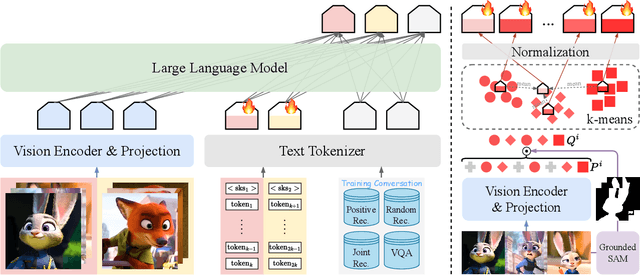
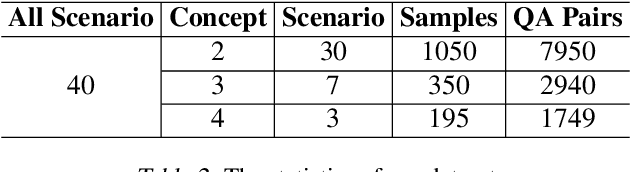
Current vision-language models (VLMs) show exceptional abilities across diverse tasks including visual question answering. To enhance user experience in practical applications, recent studies investigate VLM personalization to understand user-provided concepts. However, existing studies mainly focus on single-concept personalization, neglecting the existence and interplay of multiple concepts, which limits the real-world applicability of personalized VLMs. In this paper, we propose the first multi-concept personalization method named MC-LLaVA along with a high-quality multi-concept personalization dataset. Specifically, MC-LLaVA uses a joint training strategy incorporating multiple concepts in a single training step, allowing VLMs to perform accurately in multi-concept personalization. To reduce the cost of joint training, MC-LLaVA leverages visual token information for concept token initialization, yielding improved concept representation and accelerating joint training. To advance multi-concept personalization research, we further contribute a high-quality dataset. We carefully collect images from various movies that contain multiple characters and manually generate the multi-concept question-answer samples. Our dataset features diverse movie types and question-answer types. We conduct comprehensive qualitative and quantitative experiments to demonstrate that MC-LLaVA can achieve impressive multi-concept personalized responses, paving the way for VLMs to become better user-specific assistants. The code and dataset will be publicly available at https://github.com/arctanxarc/MC-LLaVA.
Natias: Neuron Attribution based Transferable Image Adversarial Steganography
Sep 08, 2024



Image steganography is a technique to conceal secret messages within digital images. Steganalysis, on the contrary, aims to detect the presence of secret messages within images. Recently, deep-learning-based steganalysis methods have achieved excellent detection performance. As a countermeasure, adversarial steganography has garnered considerable attention due to its ability to effectively deceive deep-learning-based steganalysis. However, steganalysts often employ unknown steganalytic models for detection. Therefore, the ability of adversarial steganography to deceive non-target steganalytic models, known as transferability, becomes especially important. Nevertheless, existing adversarial steganographic methods do not consider how to enhance transferability. To address this issue, we propose a novel adversarial steganographic scheme named Natias. Specifically, we first attribute the output of a steganalytic model to each neuron in the target middle layer to identify critical features. Next, we corrupt these critical features that may be adopted by diverse steganalytic models. Consequently, it can promote the transferability of adversarial steganography. Our proposed method can be seamlessly integrated with existing adversarial steganography frameworks. Thorough experimental analyses affirm that our proposed technique possesses improved transferability when contrasted with former approaches, and it attains heightened security in retraining scenarios.