 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-LLaVA: Multi-Concept Personalized Vision-Language Model
Paper and Code
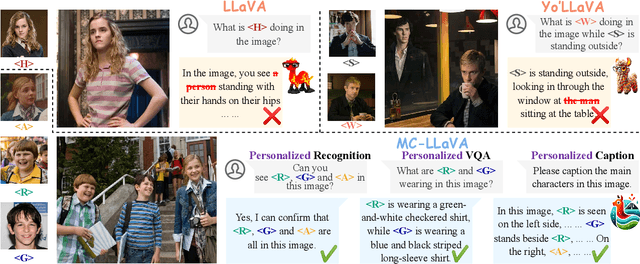

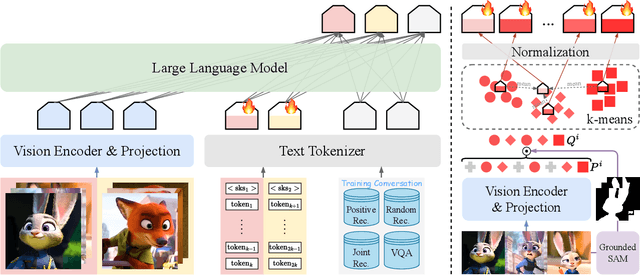
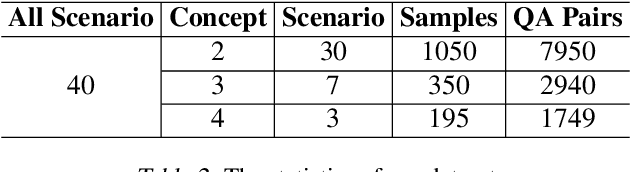
Current vision-language models (VLMs) show exceptional abilities across diverse tasks including visual question answering. To enhance user experience in practical applications, recent studies investigate VLM personalization to understand user-provided concepts. However, existing studies mainly focus on single-concept personalization, neglecting the existence and interplay of multiple concepts, which limits the real-world applicability of personalized VLMs. In this paper, we propose the first multi-concept personalization method named MC-LLaVA along with a high-quality multi-concept personalization dataset. Specifically, MC-LLaVA uses a joint training strategy incorporating multiple concepts in a single training step, allowing VLMs to perform accurately in multi-concept personalization. To reduce the cost of joint training, MC-LLaVA leverages visual token information for concept token initialization, yielding improved concept representation and accelerating joint training. To advance multi-concept personalization research, we further contribute a high-quality dataset. We carefully collect images from various movies that contain multiple characters and manually generate the multi-concept question-answer samples. Our dataset features diverse movie types and question-answer types. We conduct comprehensive qualitative and quantitative experiments to demonstrate that MC-LLaVA can achieve impressive multi-concept personalized responses, paving the way for VLMs to become better user-specific assistants. The code and dataset will be publicly available at https://github.com/arctanxarc/MC-LLaVA.