 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEARL: Personalized Streaming Video Understanding Model
Mar 20, 2026Human cognition of new concepts is inherently a streaming process: we continuously recognize new objects or identities and update our memories over time. However, current multimodal personalization methods are largely limited to static images or offline videos. This disconnects continuous visual input from instant real-world feedback, limiting their ability to provide the real-time, interactive personalized responses essential for future AI assistants. To bridge this gap, we first propose and formally define the novel task of Personalized Streaming Video Understanding (PSVU). To facilitate research in this new direction, we introduce PEARL-Bench, the first comprehensive benchmark designed specifically to evaluate this challenging setting. It evaluates a model's ability to respond to personalized concepts at exact timestamps under two modes: (1) Frame-level, focusing on a specific person or object in discrete frames, and (2) a novel Video-level, focusing on personalized actions unfolding across continuous frames. PEARL-Bench comprises 132 unique videos and 2,173 fine-grained annotations with precise timestamps. Concept diversity and annotation quality are strictly ensured through a combined pipeline of automated generation and human verification. To tackle this challenging new setting, we further propose PEARL, a plug-and-play, training-free strategy that serves as a strong baseline. Extensive evaluations across 8 offline and online models demonstrate that PEARL achieves state-of-the-art performance. Notably, it brings consistent PSVU improvements when applied to 3 distinct architectures, proving to be a highly effective and robust strategy. We hope this work advances vision-language model (VLM) personalization and inspires further research into streaming personalized AI assistants. Code is available at https://github.com/Yuanhong-Zheng/PEARL.
GENIUS: Generative Fluid Intelligence Evaluation Suite
Feb 11, 2026Unified Multimodal Models (UMMs) have shown remarkable progress in visual generation. Yet, existing benchmarks predominantly assess $\textit{Crystallized Intelligence}$, which relies on recalling accumulated knowledge and learned schemas. This focus overlooks $\textit{Generative Fluid Intelligence (GFI)}$: the capacity to induce patterns, reason through constraints, and adapt to novel scenarios on the fly. To rigorously assess this capability, we introduce $\textbf{GENIUS}$ ($\textbf{GEN}$ Fluid $\textbf{I}$ntelligence Eval$\textbf{U}$ation $\textbf{S}$uite). We formalize $\textit{GFI}$ as a synthesis of three primitives. These include $\textit{Inducing Implicit Patterns}$ (e.g., inferring personalized visual preferences), $\textit{Executing Ad-hoc Constraints}$ (e.g., visualizing abstract metaphors), and $\textit{Adapting to Contextual Knowledge}$ (e.g., simulating counter-intuitive physics). Collectively, these primitives challenge models to solve problems grounded entirely in the immediate context. Our systematic evaluation of 12 representative models reveals significant performance deficits in these tasks. Crucially, our diagnostic analysis disentangles these failure modes. It demonstrates that deficits stem from limited context comprehension rather than insufficient intrinsic generative capability. To bridge this gap, we propose a training-free attention intervention strategy. Ultimately, $\textbf{GENIUS}$ establishes a rigorous standard for $\textit{GFI}$, guiding the field beyond knowledge utilization toward dynamic, general-purpose reasoning. Our dataset and code will be released at: $\href{https://github.com/arctanxarc/GENIUS}{https://github.com/arctanxarc/GENIUS}$.
Orthogonal Model Merging
Feb 05, 2026Merging finetuned Large Language Models (LLMs) has become increasingly important for integrating diverse capabilities into a single unified model. However, prevailing model merging methods rely on linear arithmetic in Euclidean space, which often destroys the intrinsic geometric properties of pretrained weights, such as hyperspherical energy. To address this, we propose Orthogonal Model Merging (OrthoMerge), a method that performs merging operations on the Riemannian manifold formed by the orthogonal group to preserve the geometric structure of the model's weights. By mapping task-specific orthogonal matrices learned by Orthogonal Finetuning (OFT) to the Lie algebra, OrthoMerge enables a principled yet efficient integration that takes into account both the direction and intensity of adaptations. In addition to directly leveraging orthogonal matrices obtained by OFT, we further extend this approach to general models finetuned with non-OFT methods (i.e., low-rank finetuning, full finetuning) via an Orthogonal-Residual Decoupling strategy. This technique extracts the orthogonal components of expert models by solving the orthogonal Procrustes problem, which are then merged on the manifold of the orthogonal group, while the remaining linear residuals are processed through standard additive merging. Extensive empirical results demonstrate the effectiveness of OrthoMerge in mitigating catastrophic forgetting and maintaining model performance across diverse tasks.
GRAN-TED: Generating Robust, Aligned, and Nuanced Text Embedding for Diffusion Models
Dec 17, 2025The text encoder is a critical component of text-to-image and text-to-video diffusion models, fundamentally determining the semantic fidelity of the generated content. However, its development has been hindered by two major challenges: the lack of an efficient evaluation framework that reliably predicts downstream generation performance, and the difficulty of effectively adapting pretrained language models for visual synthesis. To address these issues, we introduce GRAN-TED, a paradigm to Generate Robust, Aligned, and Nuanced Text Embeddings for Diffusion models. Our contribution is twofold. First, we propose TED-6K, a novel text-only benchmark that enables efficient and robust assessment of an encoder's representational quality without requiring costly end-to-end model training. We demonstrate that performance on TED-6K, standardized via a lightweight, unified adapter, strongly correlates with an encoder's effectiveness in downstream generation tasks. Second, guided by this validated framework, we develop a superior text encoder using a novel two-stage training paradigm. This process involves an initial fine-tuning stage on a Multimodal Large Language Model for better visual representation, followed by a layer-wise weighting method to extract more nuanced and potent text features. Our experiments show that the resulting GRAN-TED encoder not only achieves state-of-the-art performance on TED-6K but also leads to demonstrable performance gains in text-to-image and text-to-video generation. Our code is available at the following link: https://anonymous.4open.science/r/GRAN-TED-4FCC/.
MMSI-Video-Bench: A Holistic Benchmark for Video-Based Spatial Intelligence
Dec 11, 2025Spatial understanding over continuous visual input is crucial for MLLMs to evolve into general-purpose assistants in physical environments. Yet there is still no comprehensive benchmark that holistically assesses the progress toward this goal. In this work, we introduce MMSI-Video-Bench, a fully human-annotated benchmark for video-based spatial intelligence in MLLMs. It operationalizes a four-level framework, Perception, Planning, Prediction, and Cross-Video Reasoning, through 1,106 questions grounded in 1,278 clips from 25 datasets and in-house videos. Each item is carefully designed and reviewed by 3DV experts with explanatory rationales to ensure precise, unambiguous grounding. Leveraging its diverse data sources and holistic task coverage, MMSI-Video-Bench also supports three domain-oriented sub-benchmarks (Indoor Scene Perception Bench, Robot Bench and Grounding Bench) for targeted capability assessment. We evaluate 25 strong open-source and proprietary MLLMs, revealing a striking human--AI gap: many models perform near chance, and the best reasoning model lags humans by nearly 60%. We further find that spatially fine-tuned models still fail to generalize effectively on our benchmark. Fine-grained error analysis exposes systematic failures in geometric reasoning, motion grounding, long-horizon prediction, and cross-video correspondence. We also show that typical frame-sampling strategies transfer poorly to our reasoning-intensive benchmark, and that neither 3D spatial cues nor chain-of-thought prompting yields meaningful gains. We expect our benchmark to establish a solid testbed for advancing video-based spatial intelligence.
The Unseen Bias: How Norm Discrepancy in Pre-Norm MLLMs Leads to Visual Information Loss
Dec 09, 2025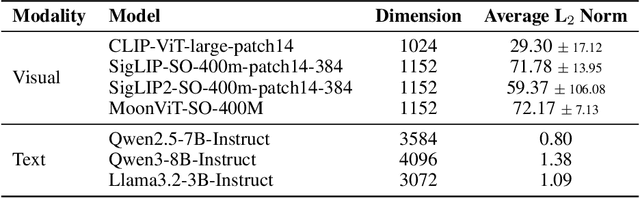

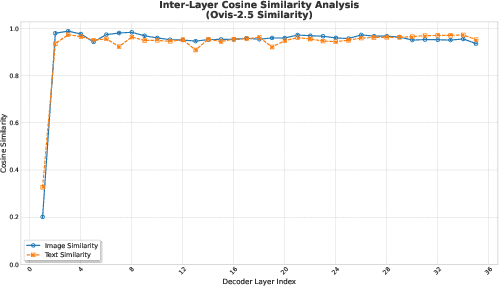

Multimodal Large Language Models (MLLMs), which couple pre-trained vision encoders and language models, have shown remarkable capabilities. However, their reliance on the ubiquitous Pre-Norm architecture introduces a subtle yet critical flaw: a severe norm disparity between the high-norm visual tokens and the low-norm text tokens. In this work, we present a formal theoretical analysis demonstrating that this imbalance is not a static issue. Instead, it induces an ``asymmetric update dynamic,'' where high-norm visual tokens exhibit a ``representational inertia,'' causing them to transform semantically much slower than their textual counterparts. This fundamentally impairs effective cross-modal feature fusion. Our empirical validation across a range of mainstream MLLMs confirms that this theoretical dynamic -- the persistence of norm disparity and the resulting asymmetric update rates -- is a prevalent phenomenon. Based on this insight, we propose a remarkably simple yet effective solution: inserting a single, carefully initialized LayerNorm layer after the visual projector to enforce norm alignment. Experiments conducted on the LLaVA-1.5 architecture show that this intervention yields significant performance gains not only on a wide suite of multimodal benchmarks but also, notably, on text-only evaluations such as MMLU, suggesting that resolving the architectural imbalance leads to a more holistically capable model.
Improving Alignment in LVLMs with Debiased Self-Judgment
Aug 28, 2025



The rapid advancements in Large Language Models (LLMs) and Large Visual-Language Models (LVLMs) have opened up new opportunities for integrating visual and linguistic modalities. However, effectively aligning these modalities remains challenging, often leading to hallucinations--where generated outputs are not grounded in the visual input--and raising safety concerns across various domains. Existing alignment methods, such as instruction tuning and preference tuning, often rely on external datasets, human annotations, or complex post-processing, which limit scalability and increase costs. To address these challenges, we propose a novel approach that generates the debiased self-judgment score, a self-evaluation metric created internally by the model without relying on external resources. This enables the model to autonomously improve alignment. Our method enhances both decoding strategies and preference tuning processes, resulting in reduced hallucinations, enhanced safety, and improved overall capability. Empirical results show that our approach significantly outperforms traditional methods, offering a more effective solution for aligning LVLMs.
Small-Large Collaboration: Training-efficient Concept Personalization for Large VLM using a Meta Personalized Small VLM
Aug 10, 2025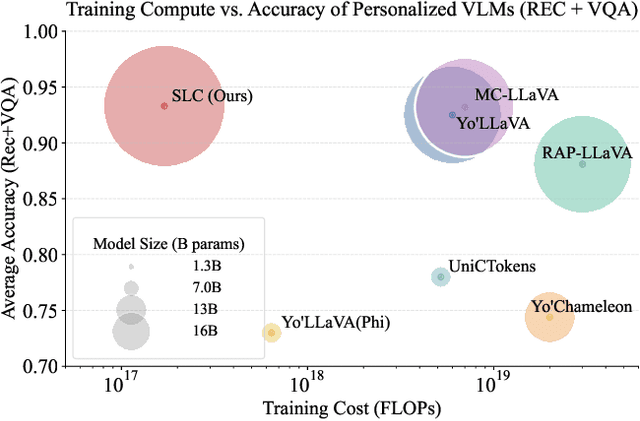
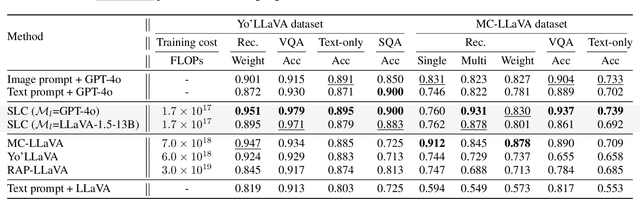
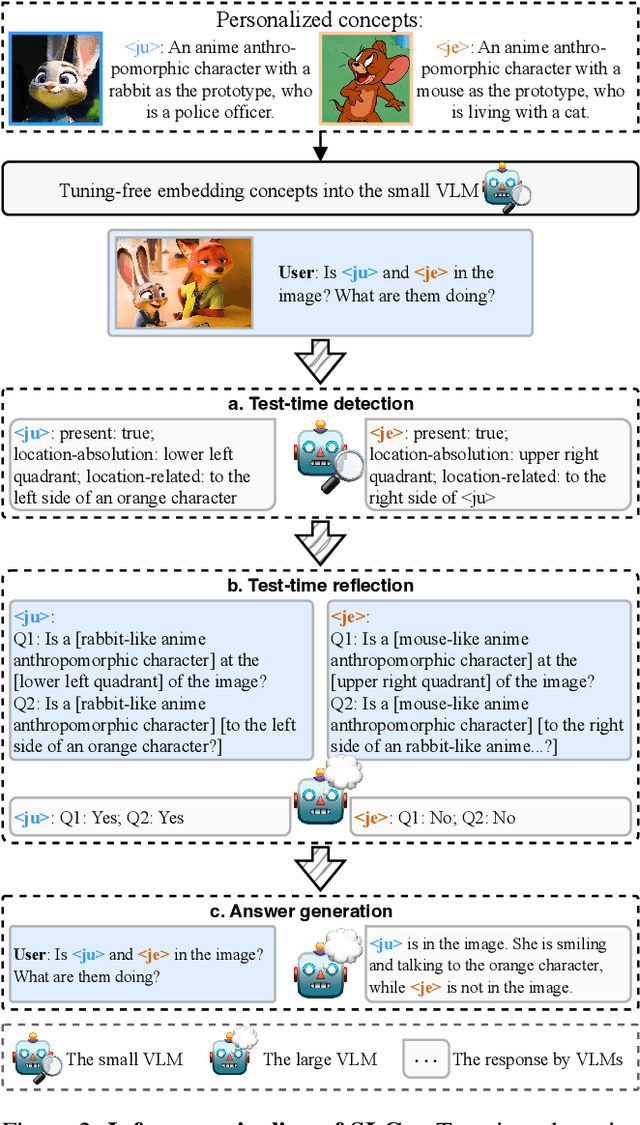
Personalizing Vision-Language Models (VLMs) to transform them into daily assistants has emerged as a trending research direction. However, leading companies like OpenAI continue to increase model size and develop complex designs such as the chain of thought (CoT). While large VLMs are proficient in complex multi-modal understanding, their high training costs and limited access via paid APIs restrict direct personalization. Conversely, small VLMs are easily personalized and freely available, but they lack sufficient reasoning capabilities. Inspired by this, we propose a novel collaborative framework named Small-Large Collaboration (SLC) for large VLM personalization, where the small VLM is responsible for generating personalized information, while the large model integrates this personalized information to deliver accurate responses. To effectively incorporate personalized information, we develop a test-time reflection strategy, preventing the potential hallucination of the small VLM. Since SLC only needs to train a meta personalized small VLM for the large VLMs, the overall process is training-efficient. To the best of our knowledge, this is the first training-efficient framework that supports both open-source and closed-source large VLMs, enabling broader real-world personalized applications. We conduct thorough experiments across various benchmarks and large VLMs to demonstrate the effectiveness of the proposed SLC framework. The code will be released at https://github.com/Hhankyangg/SLC.
VFlowOpt: A Token Pruning Framework for LMMs with Visual Information Flow-Guided Optimization
Aug 07, 2025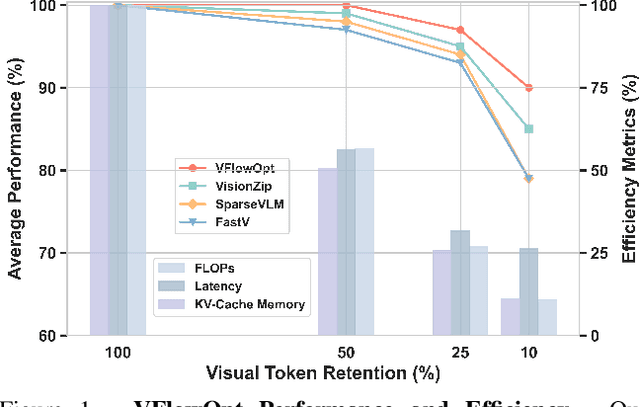
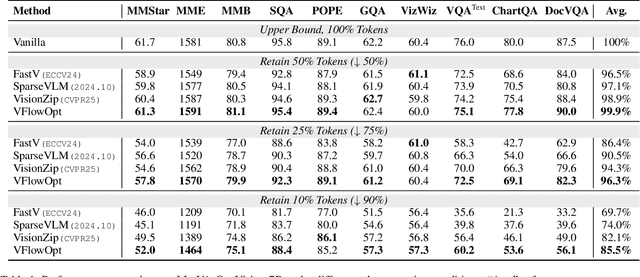
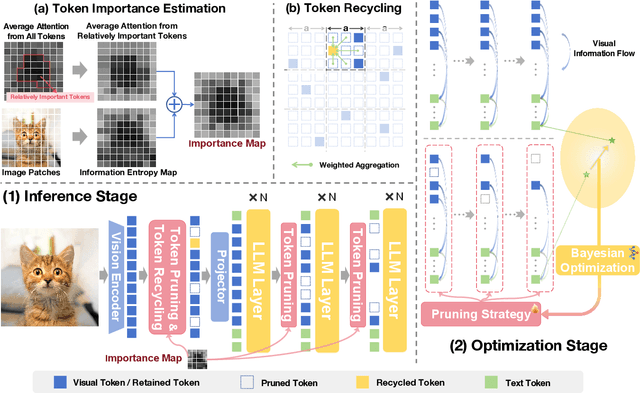
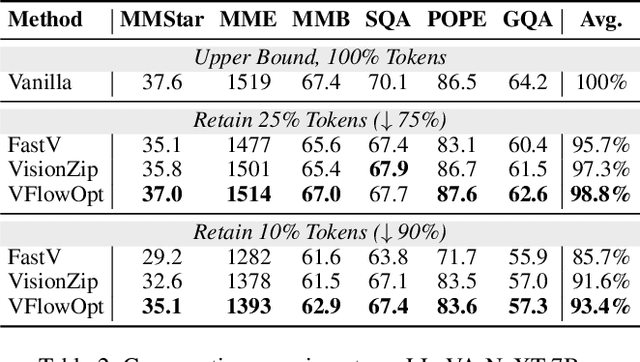
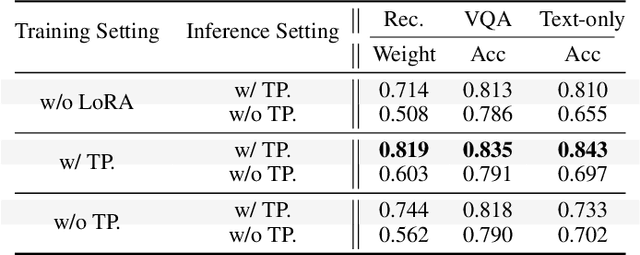
Large Multimodal Models (LMMs) excel in visual-language tasks by leveraging numerous visual tokens for fine-grained visual information, but this token redundancy results in significant computational costs. Previous research aimed at reducing visual tokens during inference typically leverages importance maps derived from attention scores among vision-only tokens or vision-language tokens to prune tokens across one or multiple pruning stages. Despite this progress, pruning frameworks and strategies remain simplistic and insufficiently explored, often resulting in substantial performance degradation. In this paper, we propose VFlowOpt, a token pruning framework that introduces an importance map derivation process and a progressive pruning module with a recycling mechanism. The hyperparameters of its pruning strategy are further optimized by a visual information flow-guided method. Specifically, we compute an importance map for image tokens based on their attention-derived context relevance and patch-level information entropy. We then decide which tokens to retain or prune and aggregate the pruned ones as recycled tokens to avoid potential information loss. Finally, we apply a visual information flow-guided method that regards the last token in the LMM as the most representative signal of text-visual interactions. This method minimizes the discrepancy between token representations in LMMs with and without pruning, thereby enabling superior pruning strategies tailored to different LMMs. Experiments demonstrate that VFlowOpt can prune 90% of visual tokens while maintaining comparable performance, leading to an 89% reduction in KV-Cache memory and 3.8 times faster inference.
VersaVid-R1: A Versatile Video Understanding and Reasoning Model from Question Answering to Captioning Tasks
Jun 10, 2025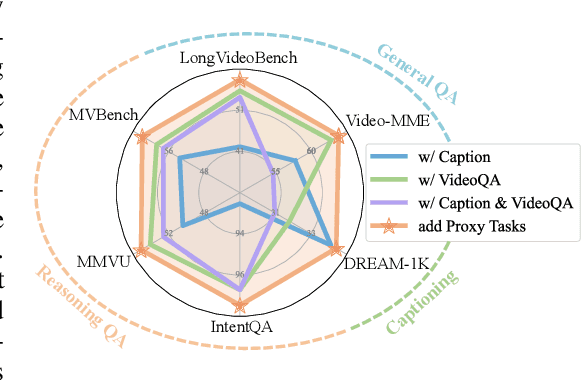
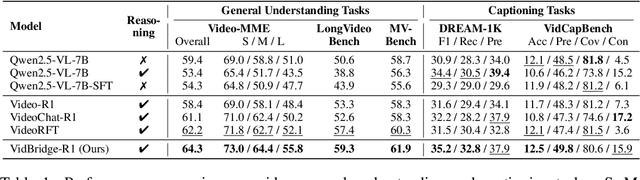
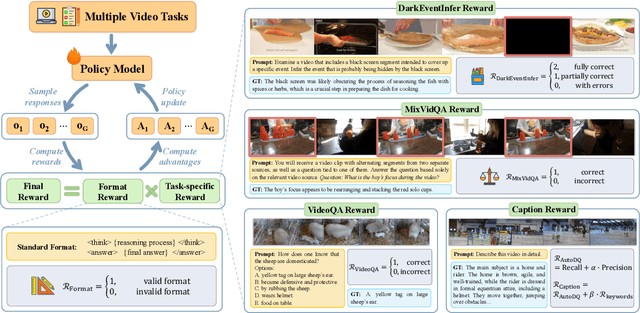
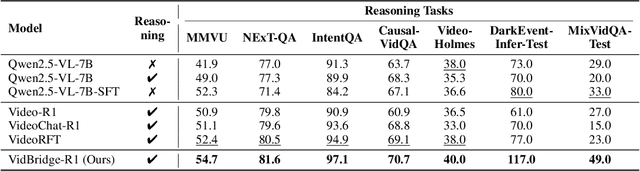
Recent advancements in multimodal large language models have successfully extended the Reason-Then-Respond paradigm to image-based reasoning, yet video-based reasoning remains an underdeveloped frontier, primarily due to the scarcity of high-quality reasoning-oriented data and effective training methodologies. To bridge this gap, we introduce DarkEventInfer and MixVidQA, two novel datasets specifically designed to stimulate the model's advanced video understanding and reasoning abilities. DarkEventinfer presents videos with masked event segments, requiring models to infer the obscured content based on contextual video cues. MixVidQA, on the other hand, presents interleaved video sequences composed of two distinct clips, challenging models to isolate and reason about one while disregarding the other. Leveraging these carefully curated training samples together with reinforcement learning guided by diverse reward functions, we develop VersaVid-R1, the first versatile video understanding and reasoning model under the Reason-Then-Respond paradigm capable of handling multiple-choice and open-ended question answering, as well as video captioning tasks. Extensive experiments demonstrate that VersaVid-R1 significantly outperforms existing models across a broad spectrum of benchmarks, covering video general understanding, cognitive reasoning, and captioning tasks.