 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Self-Rewarding Vision Language Models
Paper and Code
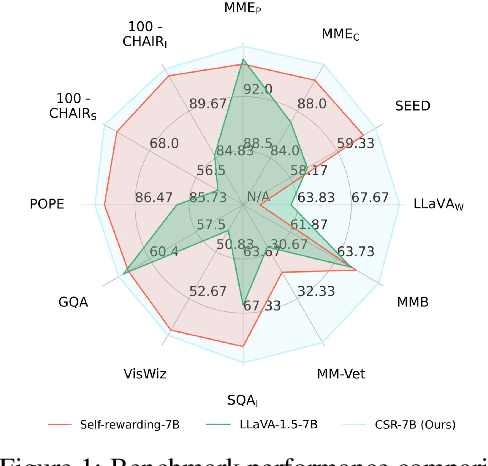
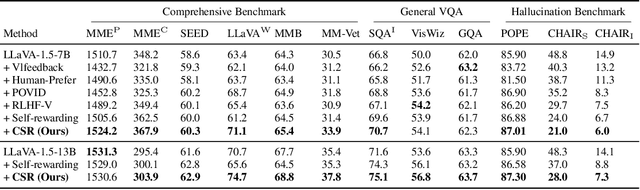
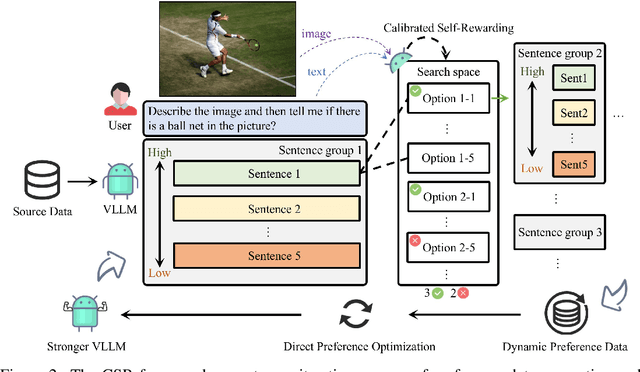
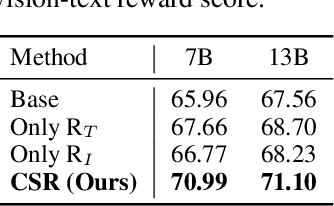
Large Vision-Language Models (LVLMs) have made substantial progress by integrating pre-trained large language models (LLMs) and vision models through instruction tuning. Despite these advancements, LVLMs often exhibit the hallucination phenomenon, where generated text responses appear linguistically plausible but contradict the input image, indicating a misalignment between image and text pairs. This misalignment arises because the model tends to prioritize textual information over visual input, even when both the language model and visual representations are of high quality. Existing methods leverage additional models or human annotations to curate preference data and enhance modality alignment through preference optimization. These approaches may not effectively reflect the target LVLM's preferences, making the curated preferences easily distinguishable. Our work addresses these challenges by proposing the Calibrated Self-Rewarding (CSR) approach, which enables the model to self-improve by iteratively generating candidate responses, evaluating the reward for each response, and curating preference data for fine-tuning. In the reward modeling, we employ a step-wise strategy and incorporate visual constraints into the self-rewarding process to place greater emphasis on visual input. Empirical results demonstrate that CSR enhances performance and reduces hallucinations across ten benchmarks and tasks, achieving substantial improvements over existing methods by 7.62%. Our empirical results are further supported by rigorous theoretical analysis, under mild assumptions, verifying the effectiveness of introducing visual constraints into the self-rewarding paradigm. Additionally, CSR shows compatibility with different vision-language models and the ability to incrementally improve performance through iterative fine-tuning. Our data and code are available at https://github.com/YiyangZhou/CSR.