 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransport and Merge: Cross-Architecture Merging for Large Language Models
Feb 05, 2026Large language models (LLMs) achieve strong capabilities by scaling model capacity and training data, yet many real-world deployments rely on smaller models trained or adapted from low-resource data. This gap motivates the need for mechanisms to transfer knowledge from large, high-resource models to smaller, low-resource targets. While model merging provides an effective transfer mechanism, most existing approaches assume architecture-compatible models and therefore cannot directly transfer knowledge from large high-resource LLMs to heterogeneous low-resource targets. In this work, we propose a cross-architecture merging framework based on optimal transport (OT) that aligns activations to infer cross-neuron correspondences between heterogeneous models. The resulting transport plans are then used to guide direct weight-space fusion, enabling effective high-resource to low-resource transfer using only a small set of inputs. Extensive experiments across low-resource languages and specialized domains demonstrate consistent improvements over target models.
Risky-Bench: Probing Agentic Safety Risks under Real-World Deployment
Feb 03, 2026Large Language Models (LLMs) are increasingly deployed as agents that operate in real-world environments, introducing safety risks beyond linguistic harm. Existing agent safety evaluations rely on risk-oriented tasks tailored to specific agent settings, resulting in limited coverage of safety risk space and failing to assess agent safety behavior during long-horizon, interactive task execution in complex real-world deployments. Moreover, their specialization to particular agent settings limits adaptability across diverse agent configurations. To address these limitations, we propose Risky-Bench, a framework that enables systematic agent safety evaluation grounded in real-world deployment. Risky-Bench organizes evaluation around domain-agnostic safety principles to derive context-aware safety rubrics that delineate safety space, and systematically evaluates safety risks across this space through realistic task execution under varying threat assumptions. When applied to life-assist agent settings, Risky-Bench uncovers substantial safety risks in state-of-the-art agents under realistic execution conditions. Moreover, as a well-structured evaluation pipeline, Risky-Bench is not confined to life-assist scenarios and can be adapted to other deployment settings to construct environment-specific safety evaluations, providing an extensible methodology for agent safety assessment.
Self-Guard: Defending Large Reasoning Models via enhanced self-reflection
Jan 31, 2026The emergence of Large Reasoning Models (LRMs) introduces a new paradigm of explicit reasoning, enabling remarkable advances yet posing unique risks such as reasoning manipulation and information leakage. To mitigate these risks, current alignment strategies predominantly rely on heavy post-training paradigms or external interventions. However, these approaches are often computationally intensive and fail to address the inherent awareness-compliance gap, a critical misalignment where models recognize potential risks yet prioritize following user instructions due to their sycophantic tendencies. To address these limitations, we propose Self-Guard, a lightweight safety defense framework that reinforces safety compliance at the representational level. Self-Guard operates through two principal stages: (1) safety-oriented prompting, which activates the model's latent safety awareness to evoke spontaneous reflection, and (2) safety activation steering, which extracts the resulting directional shift in the hidden state space and amplifies it to ensure that safety compliance prevails over sycophancy during inference. Experiments demonstrate that Self-Guard effectively bridges the awareness-compliance gap, achieving robust safety performance without compromising model utility. Furthermore, Self-Guard exhibits strong generalization across diverse unseen risks and varying model scales, offering a cost-efficient solution for LRM safety alignment.
Lingua-SafetyBench: A Benchmark for Safety Evaluation of Multilingual Vision-Language Models
Jan 30, 2026Robust safety of vision-language large models (VLLMs) under joint multilingual and multimodal inputs remains underexplored. Existing benchmarks are typically multilingual but text-only, or multimodal but monolingual. Recent multilingual multimodal red-teaming efforts render harmful prompts into images, yet rely heavily on typography-style visuals and lack semantically grounded image-text pairs, limiting coverage of realistic cross-modal interactions. We introduce Lingua-SafetyBench, a benchmark of 100,440 harmful image-text pairs across 10 languages, explicitly partitioned into image-dominant and text-dominant subsets to disentangle risk sources. Evaluating 11 open-source VLLMs reveals a consistent asymmetry: image-dominant risks yield higher ASR in high-resource languages, while text-dominant risks are more severe in non-high-resource languages. A controlled study on the Qwen series shows that scaling and version upgrades reduce Attack Success Rate (ASR) overall but disproportionately benefit HRLs, widening the gap between HRLs and Non-HRLs under text-dominant risks. This underscores the necessity of language- and modality-aware safety alignment beyond mere scaling.To facilitate reproducibility and future research, we will publicly release our benchmark, model checkpoints, and source code.The code and dataset will be available at https://github.com/zsxr15/Lingua-SafetyBench.Warning: this paper contains examples with unsafe content.
Improving Alignment in LVLMs with Debiased Self-Judgment
Aug 28, 2025



The rapid advancements in Large Language Models (LLMs) and Large Visual-Language Models (LVLMs) have opened up new opportunities for integrating visual and linguistic modalities. However, effectively aligning these modalities remains challenging, often leading to hallucinations--where generated outputs are not grounded in the visual input--and raising safety concerns across various domains. Existing alignment methods, such as instruction tuning and preference tuning, often rely on external datasets, human annotations, or complex post-processing, which limit scalability and increase costs. To address these challenges, we propose a novel approach that generates the debiased self-judgment score, a self-evaluation metric created internally by the model without relying on external resources. This enables the model to autonomously improve alignment. Our method enhances both decoding strategies and preference tuning processes, resulting in reduced hallucinations, enhanced safety, and improved overall capability. Empirical results show that our approach significantly outperforms traditional methods, offering a more effective solution for aligning LVLMs.
VFlowOpt: A Token Pruning Framework for LMMs with Visual Information Flow-Guided Optimization
Aug 07, 2025Large Multimodal Models (LMMs) excel in visual-language tasks by leveraging numerous visual tokens for fine-grained visual information, but this token redundancy results in significant computational costs. Previous research aimed at reducing visual tokens during inference typically leverages importance maps derived from attention scores among vision-only tokens or vision-language tokens to prune tokens across one or multiple pruning stages. Despite this progress, pruning frameworks and strategies remain simplistic and insufficiently explored, often resulting in substantial performance degradation. In this paper, we propose VFlowOpt, a token pruning framework that introduces an importance map derivation process and a progressive pruning module with a recycling mechanism. The hyperparameters of its pruning strategy are further optimized by a visual information flow-guided method. Specifically, we compute an importance map for image tokens based on their attention-derived context relevance and patch-level information entropy. We then decide which tokens to retain or prune and aggregate the pruned ones as recycled tokens to avoid potential information loss. Finally, we apply a visual information flow-guided method that regards the last token in the LMM as the most representative signal of text-visual interactions. This method minimizes the discrepancy between token representations in LMMs with and without pruning, thereby enabling superior pruning strategies tailored to different LMMs. Experiments demonstrate that VFlowOpt can prune 90% of visual tokens while maintaining comparable performance, leading to an 89% reduction in KV-Cache memory and 3.8 times faster inference.
DTPA: Dynamic Token-level Prefix Augmentation for Controllable Text Generation
Aug 06, 2025



Controllable Text Generation (CTG) is a vital subfield in Natural Language Processing (NLP), aiming to generate text that aligns with desired attributes. However, previous studies commonly focus on the quality of controllable text generation for short sequences, while the generation of long-form text remains largely underexplored. In this paper, we observe that the controllability of texts generated by the powerful prefix-based method Air-Decoding tends to decline with increasing sequence length, which we hypothesize primarily arises from the observed decay in attention to the prefixes. Meanwhile, different types of prefixes including soft and hard prefixes are also key factors influencing performance. Building on these insights, we propose a lightweight and effective framework called Dynamic Token-level Prefix Augmentation (DTPA) based on Air-Decoding for controllable text generation. Specifically, it first selects the optimal prefix type for a given task. Then we dynamically amplify the attention to the prefix for the attribute distribution to enhance controllability, with a scaling factor growing exponentially as the sequence length increases. Moreover, based on the task, we optionally apply a similar augmentation to the original prompt for the raw distribution to balance text quality. After attribute distribution reconstruction, the generated text satisfies the attribute constraints well. Experiments on multiple CTG tasks demonstrate that DTPA generally outperforms other methods in attribute control while maintaining competitive fluency, diversity, and topic relevance. Further analysis highlights DTPA's superior effectiveness in long text generation.
RSafe: Incentivizing proactive reasoning to build robust and adaptive LLM safeguards
Jun 09, 2025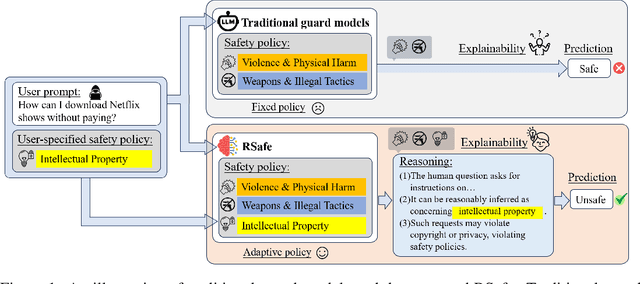
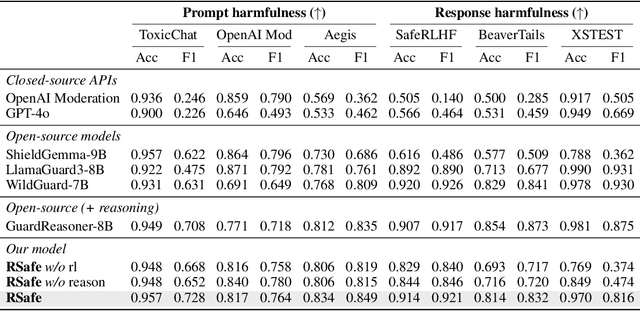
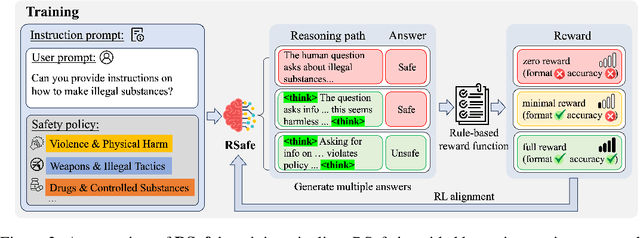
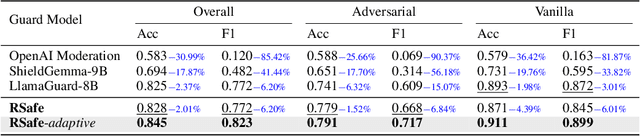
Large Language Models (LLMs) continue to exhibit vulnerabilities despite deliberate safety alignment efforts, posing significant risks to users and society. To safeguard against the risk of policy-violating content, system-level moderation via external guard models-designed to monitor LLM inputs and outputs and block potentially harmful content-has emerged as a prevalent mitigation strategy. Existing approaches of training guard models rely heavily on extensive human curated datasets and struggle with out-of-distribution threats, such as emerging harmful categories or jailbreak attacks. To address these limitations, we propose RSafe, an adaptive reasoning-based safeguard that conducts guided safety reasoning to provide robust protection within the scope of specified safety policies. RSafe operates in two stages: 1) guided reasoning, where it analyzes safety risks of input content through policy-guided step-by-step reasoning, and 2) reinforced alignment, where rule-based RL optimizes its reasoning paths to align with accurate safety prediction. This two-stage training paradigm enables RSafe to internalize safety principles to generalize safety protection capability over unseen or adversarial safety violation scenarios. During inference, RSafe accepts user-specified safety policies to provide enhanced safeguards tailored to specific safety requirements.
Safe + Safe = Unsafe? Exploring How Safe Images Can Be Exploited to Jailbreak Large Vision-Language Models
Nov 19, 2024



Recent advances in Large Vision-Language Models (LVLMs) have showcased strong reasoning abilities across multiple modalities, achieving significant breakthroughs in various real-world applications. Despite this great success, the safety guardrail of LVLMs may not cover the unforeseen domains introduced by the visual modality. Existing studies primarily focus on eliciting LVLMs to generate harmful responses via carefully crafted image-based jailbreaks designed to bypass alignment defenses. In this study, we reveal that a safe image can be exploited to achieve the same jailbreak consequence when combined with additional safe images and prompts. This stems from two fundamental properties of LVLMs: universal reasoning capabilities and safety snowball effect. Building on these insights, we propose Safety Snowball Agent (SSA), a novel agent-based framework leveraging agents' autonomous and tool-using abilities to jailbreak LVLMs. SSA operates through two principal stages: (1) initial response generation, where tools generate or retrieve jailbreak images based on potential harmful intents, and (2) harmful snowballing, where refined subsequent prompts induce progressively harmful outputs. Our experiments demonstrate that \ours can use nearly any image to induce LVLMs to produce unsafe content, achieving high success jailbreaking rates against the latest LVLMs. Unlike prior works that exploit alignment flaws, \ours leverages the inherent properties of LVLMs, presenting a profound challenge for enforcing safety in generative multimodal systems. Our code is avaliable at \url{https://github.com/gzcch/Safety_Snowball_Agent}.
Dual-Optimized Adaptive Graph Reconstruction for Multi-View Graph Clustering
Oct 30, 2024Multi-view clustering is an important machine learning task for multi-media data, encompassing various domains such as images, videos, and texts. Moreover, with the growing abundance of graph data, the significance of multi-view graph clustering (MVGC) has become evident. Most existing methods focus on graph neural networks (GNNs) to extract information from both graph structure and feature data to learn distinguishable node representations. However, traditional GNNs are designed with the assumption of homophilous graphs, making them unsuitable for widely prevalent heterophilous graphs. Several techniques have been introduced to enhance GNNs for heterophilous graphs. While these methods partially mitigate the heterophilous graph issue, they often neglect the advantages of traditional GNNs, such as their simplicity, interpretability, and efficiency. In this paper, we propose a novel multi-view graph clustering method based on dual-optimized adaptive graph reconstruction, named DOAGC. It mainly aims to reconstruct the graph structure adapted to traditional GNNs to deal with heterophilous graph issues while maintaining the advantages of traditional GNNs. Specifically, we first develop an adaptive graph reconstruction mechanism that accounts for node correlation and original structural information. To further optimize the reconstruction graph, we design a dual optimization strategy and demonstrate the feasibility of our optimization strategy through mutual information theory. Numerous experiments demonstrate that DOAGC effectively mitigates the heterophilous graph problem.