 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMEM: Unified Memory Extraction and Management Framework for Generalizable Memory
Feb 11, 2026Self-evolving memory serves as the trainable parameters for Large Language Models (LLMs)-based agents, where extraction (distilling insights from experience) and management (updating the memory bank) must be tightly coordinated. Existing methods predominately optimize memory management while treating memory extraction as a static process, resulting in poor generalization, where agents accumulate instance-specific noise rather than robust memories. To address this, we propose Unified Memory Extraction and Management (UMEM), a self-evolving agent framework that jointly optimizes a Large Language Model to simultaneous extract and manage memories. To mitigate overfitting to specific instances, we introduce Semantic Neighborhood Modeling and optimize the model with a neighborhood-level marginal utility reward via GRPO. This approach ensures memory generalizability by evaluating memory utility across clusters of semantically related queries. Extensive experiments across five benchmarks demonstrate that UMEM significantly outperforms highly competitive baselines, achieving up to a 10.67% improvement in multi-turn interactive tasks. Futhermore, UMEM maintains a monotonic growth curve during continuous evolution. Codes and models will be publicly released.
MJ-Bench: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?
Jul 05, 2024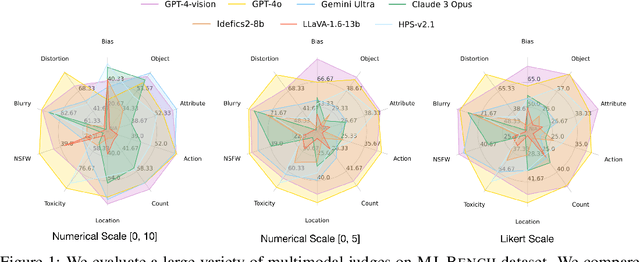
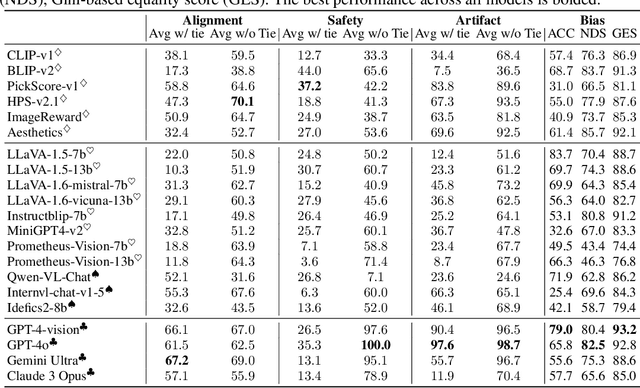

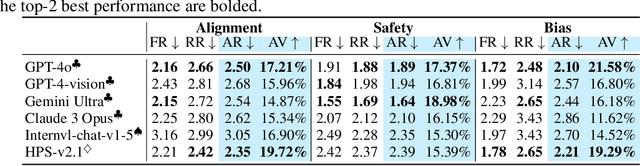
While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output. To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes. To address this issue, we introduce MJ-Bench, a novel benchmark which incorporates a comprehensive preference dataset to evaluate multimodal judges in providing feedback for image generation models across four key perspectives: alignment, safety, image quality, and bias. Specifically, we evaluate a large variety of multimodal judges including smaller-sized CLIP-based scoring models, open-source VLMs (e.g. LLaVA family), and close-source VLMs (e.g. GPT-4o, Claude 3) on each decomposed subcategory of our preference dataset. Experiments reveal that close-source VLMs generally provide better feedback, with GPT-4o outperforming other judges in average. Compared with open-source VLMs, smaller-sized scoring models can provide better feedback regarding text-image alignment and image quality, while VLMs provide more accurate feedback regarding safety and generation bias due to their stronger reasoning capabilities. Further studies in feedback scale reveal that VLM judges can generally provide more accurate and stable feedback in natural language (Likert-scale) than numerical scales. Notably, human evaluations on end-to-end fine-tuned models using separate feedback from these multimodal judges provide similar conclusions, further confirming the effectiveness of MJ-Bench. All data, code, models are available at https://huggingface.co/MJ-Bench.
Towards Faithful Explanations: Boosting Rationalization with Shortcuts Discovery
Mar 12, 2024



The remarkable success in neural networks provokes the selective rationalization. It explains the prediction results by identifying a small subset of the inputs sufficient to support them. Since existing methods still suffer from adopting the shortcuts in data to compose rationales and limited large-scale annotated rationales by human, in this paper, we propose a Shortcuts-fused Selective Rationalization (SSR) method, which boosts the rationalization by discovering and exploiting potential shortcuts. Specifically, SSR first designs a shortcuts discovery approach to detect several potential shortcuts. Then, by introducing the identified shortcuts, we propose two strategies to mitigate the problem of utilizing shortcuts to compose rationales. Finally, we develop two data augmentations methods to close the gap in the number of annotated rationales. Extensive experimental results on real-world datasets clearly validate the effectiveness of our proposed method.
Communication-Efficient Personalized Federated Learning for Speech-to-Text Tasks
Jan 18, 2024To protect privacy and meet legal regulations, federated learning (FL) has gained significant attention for training speech-to-text (S2T) systems, including automatic speech recognition (ASR) and speech translation (ST). However, the commonly used FL approach (i.e., \textsc{FedAvg}) in S2T tasks typically suffers from extensive communication overhead due to multi-round interactions based on the whole model and performance degradation caused by data heterogeneity among clients.To address these issues, we propose a personalized federated S2T framework that introduces \textsc{FedLoRA}, a lightweight LoRA module for client-side tuning and interaction with the server to minimize communication overhead, and \textsc{FedMem}, a global model equipped with a $k$-nearest-neighbor ($k$NN) classifier that captures client-specific distributional shifts to achieve personalization and overcome data heterogeneity. Extensive experiments based on Conformer and Whisper backbone models on CoVoST and GigaSpeech benchmarks show that our approach significantly reduces the communication overhead on all S2T tasks and effectively personalizes the global model to overcome data heterogeneity.
Lost in the Source Language: How Large Language Models Evaluate the Quality of Machine Translation
Jan 12, 2024



Large Language Models (LLMs) have achieved remarkable results in the machine translation evaluation task, yet there remains a gap in knowledge regarding how they utilize the provided data to conduct evaluations. This study aims to explore how LLMs leverage source and reference information in evaluating translations, with the ultimate goal of better understanding the working mechanism of LLMs. To this end, we design the controlled experiments across various input modes and model types, and employ both coarse-grained and fine-grained prompts to discern the utility of source versus reference information. Surprisingly, we find that reference information significantly enhances the evaluation accuracy, while source information sometimes is counterproductive, indicating a lack of cross-lingual capability when using LLMs to evaluate translations. We further conduct a meta-evaluation for translation error detection of LLMs, observing a similar phenomenon. These findings also suggest a potential research direction for LLMs that fully exploits the cross-lingual capability of LLMs to achieve better performance in machine translation evaluation tasks.
IMTLab: An Open-Source Platform for Building, Evaluating, and Diagnosing Interactive Machine Translation Systems
Oct 17, 2023We present IMTLab, an open-source end-to-end interactive machine translation (IMT) system platform that enables researchers to quickly build IMT systems with state-of-the-art models, perform an end-to-end evaluation, and diagnose the weakness of systems. IMTLab treats the whole interactive translation process as a task-oriented dialogue with a human-in-the-loop setting, in which human interventions can be explicitly incorporated to produce high-quality, error-free translations. To this end, a general communication interface is designed to support the flexible IMT architectures and user policies. Based on the proposed design, we construct a simulated and real interactive environment to achieve end-to-end evaluation and leverage the framework to systematically evaluate previous IMT systems. Our simulated and manual experiments show that the prefix-constrained decoding approach still gains the lowest editing cost in the end-to-end evaluation, while BiTIIMT achieves comparable editing cost with a better interactive experience.
FedJudge: Federated Legal Large Language Model
Sep 15, 2023
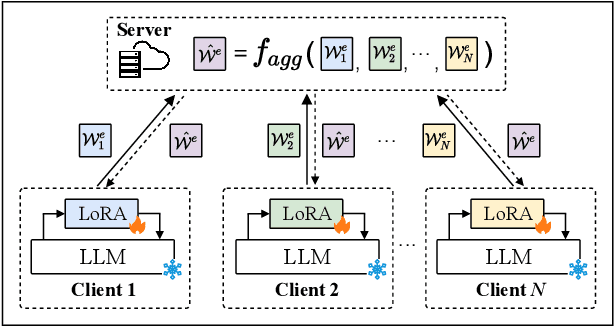
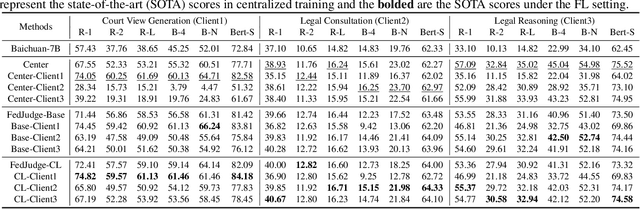
Large Language Models (LLMs) have gained prominence in the field of Legal Intelligence, offering potential applications in assisting legal professionals and laymen. However, the centralized training of these Legal LLMs raises data privacy concerns, as legal data is distributed among various institutions containing sensitive individual information. This paper addresses this challenge by exploring the integration of Legal LLMs with Federated Learning (FL) methodologies. By employing FL, Legal LLMs can be fine-tuned locally on devices or clients, and their parameters are aggregated and distributed on a central server, ensuring data privacy without directly sharing raw data. However, computation and communication overheads hinder the full fine-tuning of LLMs under the FL setting. Moreover, the distribution shift of legal data reduces the effectiveness of FL methods. To this end, in this paper, we propose the first Federated Legal Large Language Model (FedJudge) framework, which fine-tunes Legal LLMs efficiently and effectively. Specifically, FedJudge utilizes parameter-efficient fine-tuning methods to update only a few additional parameters during the FL training. Besides, we explore the continual learning methods to preserve the global model's important parameters when training local clients to mitigate the problem of data shifts. Extensive experimental results on three real-world datasets clearly validate the effectiveness of FedJudge. Code is released at https://github.com/yuelinan/FedJudge.
Nearest Neighbor Machine Translation is Meta-Optimizer on Output Projection Layer
May 22, 2023



Nearest Neighbor Machine Translation ($k$NN-MT) has achieved great success on domain adaptation tasks by integrating pre-trained Neural Machine Translation (NMT) models with domain-specific token-level retrieval. However, the reasons underlying its success have not been thoroughly investigated. In this paper, we provide a comprehensive analysis of $k$NN-MT through theoretical and empirical studies. Initially, we offer a theoretical interpretation of the working mechanism of $k$NN-MT as an efficient technique to implicitly execute gradient descent on the output projection layer of NMT, indicating that it is a specific case of model fine-tuning. Subsequently, we conduct multi-domain experiments and word-level analysis to examine the differences in performance between $k$NN-MT and entire-model fine-tuning. Our findings suggest that: (1) Incorporating $k$NN-MT with adapters yields comparable translation performance to fine-tuning on in-domain test sets, while achieving better performance on out-of-domain test sets; (2) Fine-tuning significantly outperforms $k$NN-MT on the recall of low-frequency domain-specific words, but this gap could be bridged by optimizing the context representations with additional adapter layers.
Simple and Scalable Nearest Neighbor Machine Translation
Feb 23, 2023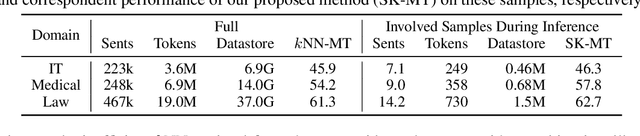
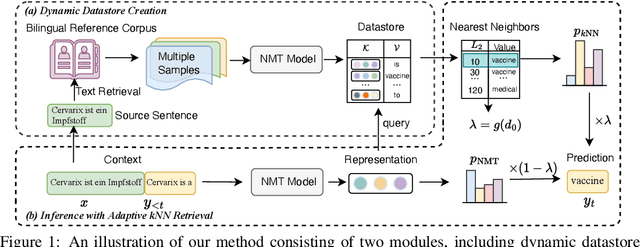
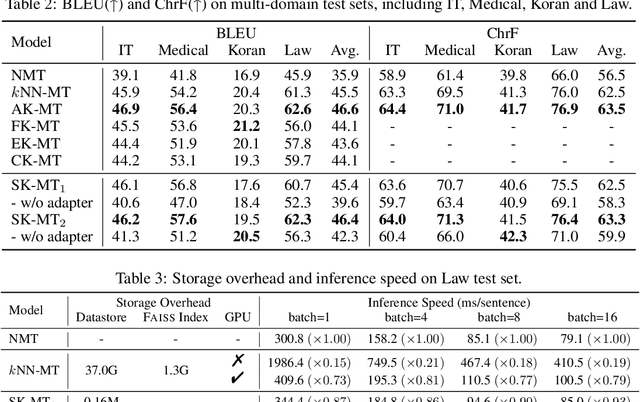
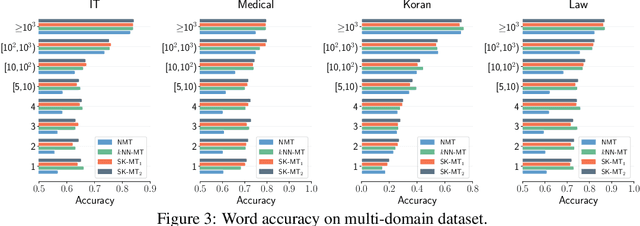
$k$NN-MT is a straightforward yet powerful approach for fast domain adaptation, which directly plugs pre-trained neural machine translation (NMT) models with domain-specific token-level $k$-nearest-neighbor ($k$NN) retrieval to achieve domain adaptation without retraining. Despite being conceptually attractive, $k$NN-MT is burdened with massive storage requirements and high computational complexity since it conducts nearest neighbor searches over the entire reference corpus. In this paper, we propose a simple and scalable nearest neighbor machine translation framework to drastically promote the decoding and storage efficiency of $k$NN-based models while maintaining the translation performance. To this end, we dynamically construct an extremely small datastore for each input via sentence-level retrieval to avoid searching the entire datastore in vanilla $k$NN-MT, based on which we further introduce a distance-aware adapter to adaptively incorporate the $k$NN retrieval results into the pre-trained NMT models. Experiments on machine translation in two general settings, static domain adaptation and online learning, demonstrate that our proposed approach not only achieves almost 90% speed as the NMT model without performance degradation, but also significantly reduces the storage requirements of $k$NN-MT.
Federated Nearest Neighbor Machine Translation
Feb 23, 2023



To protect user privacy and meet legal regulations, federated learning (FL) is attracting significant attention. Training neural machine translation (NMT) models with traditional FL algorithm (e.g., FedAvg) typically relies on multi-round model-based interactions. However, it is impractical and inefficient for machine translation tasks due to the vast communication overheads and heavy synchronization. In this paper, we propose a novel federated nearest neighbor (FedNN) machine translation framework that, instead of multi-round model-based interactions, leverages one-round memorization-based interaction to share knowledge across different clients to build low-overhead privacy-preserving systems. The whole approach equips the public NMT model trained on large-scale accessible data with a $k$-nearest-neighbor ($$kNN) classifier and integrates the external datastore constructed by private text data in all clients to form the final FL model. A two-phase datastore encryption strategy is introduced to achieve privacy-preserving during this process. Extensive experiments show that FedNN significantly reduces computational and communication costs compared with FedAvg, while maintaining promising performance in different FL settings.