 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamKV: Streaming Video Question-Answering with Segment-based KV Cache Retrieval and Compression
Nov 10, 2025



Video Large Language Models (Video-LLMs) have demonstrated significant potential in the areas of video captioning, search, and summarization. However, current Video-LLMs still face challenges with long real-world videos. Recent methods have introduced a retrieval mechanism that retrieves query-relevant KV caches for question answering, enhancing the efficiency and accuracy of long real-world videos. However, the compression and retrieval of KV caches are still not fully explored. In this paper, we propose \textbf{StreamKV}, a training-free framework that seamlessly equips Video-LLMs with advanced KV cache retrieval and compression. Compared to previous methods that used uniform partitioning, StreamKV dynamically partitions video streams into semantic segments, which better preserves semantic information. For KV cache retrieval, StreamKV calculates a summary vector for each segment to retain segment-level information essential for retrieval. For KV cache compression, StreamKV introduces a guidance prompt designed to capture the key semantic elements within each segment, ensuring only the most informative KV caches are retained for answering questions. Moreover, StreamKV unifies KV cache retrieval and compression within a single module, performing both in a layer-adaptive manner, thereby further improving the effectiveness of streaming video question answering. Extensive experiments on public StreamingVQA benchmarks demonstrate that StreamKV significantly outperforms existing Online Video-LLMs, achieving superior accuracy while substantially improving both memory efficiency and computational latency. The code has been released at https://github.com/sou1p0wer/StreamKV.
T2Vid: Translating Long Text into Multi-Image is the Catalyst for Video-LLMs
Dec 02, 2024



The success of Multimodal Large Language Models (MLLMs) in the image domain has garnered wide attention from the research community. Drawing on previous successful experiences, researchers have recently explored extending the success to the video understanding realms. Apart from training from scratch, an efficient way is to utilize the pre-trained image-LLMs, leading to two mainstream approaches, i.e. zero-shot inference and further fine-tuning with video data. In this work, our study of these approaches harvests an effective data augmentation method. We first make a deeper inspection of the zero-shot inference way and identify two limitations, i.e. limited generalization and lack of temporal understanding capabilities. Thus, we further investigate the fine-tuning approach and find a low learning efficiency when simply using all the video data samples, which can be attributed to a lack of instruction diversity. Aiming at this issue, we develop a method called T2Vid to synthesize video-like samples to enrich the instruction diversity in the training corpus. Integrating these data enables a simple and efficient training scheme, which achieves performance comparable to or even superior to using full video datasets by training with just 15% the sample size. Meanwhile, we find that the proposed scheme can boost the performance of long video understanding without training with long video samples. We hope our study will spark more thinking about using MLLMs for video understanding and curation of high-quality data. The code is released at https://github.com/xjtupanda/T2Vid.
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
May 31, 2024



In the quest for artificial general intelligence, Multi-modal Large Language Models (MLLMs) have emerged as a focal point in recent advancements. However, the predominant focus remains on developing their capabilities in static image understanding. The potential of MLLMs in processing sequential visual data is still insufficiently explored, highlighting the absence of a comprehensive, high-quality assessment of their performance. In this paper, we introduce Video-MME, the first-ever full-spectrum, Multi-Modal Evaluation benchmark of MLLMs in Video analysis. Our work distinguishes from existing benchmarks through four key features: 1) Diversity in video types, spanning 6 primary visual domains with 30 subfields to ensure broad scenario generalizability; 2) Duration in temporal dimension, encompassing both short-, medium-, and long-term videos, ranging from 11 seconds to 1 hour, for robust contextual dynamics; 3) Breadth in data modalities, integrating multi-modal inputs besides video frames, including subtitles and audios, to unveil the all-round capabilities of MLLMs; 4) Quality in annotations, utilizing rigorous manual labeling by expert annotators to facilitate precise and reliable model assessment. 900 videos with a total of 256 hours are manually selected and annotated by repeatedly viewing all the video content, resulting in 2,700 question-answer pairs. With Video-MME, we extensively evaluate various state-of-the-art MLLMs, including GPT-4 series and Gemini 1.5 Pro, as well as open-source image models like InternVL-Chat-V1.5 and video models like LLaVA-NeXT-Video. Our experiments reveal that Gemini 1.5 Pro is the best-performing commercial model, significantly outperforming the open-source models. Our dataset along with these findings underscores the need for further improvements in handling longer sequences and multi-modal data. Project Page: https://video-mme.github.io
Simple and Scalable Nearest Neighbor Machine Translation
Feb 23, 2023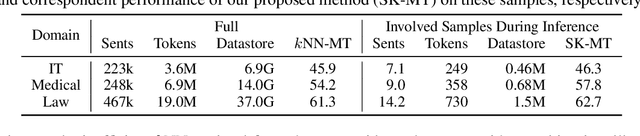
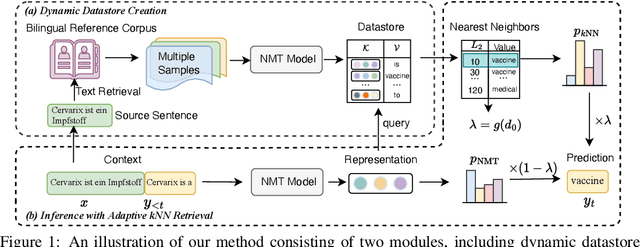
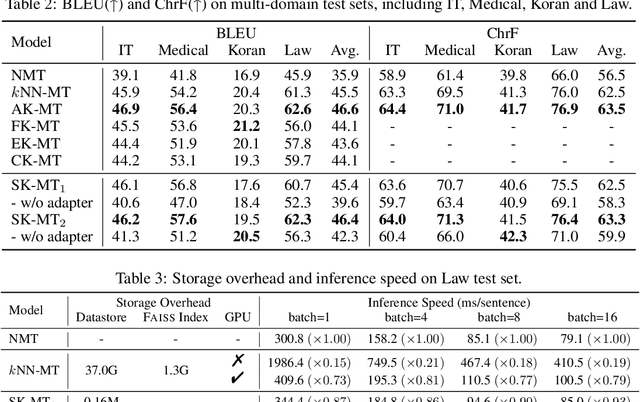
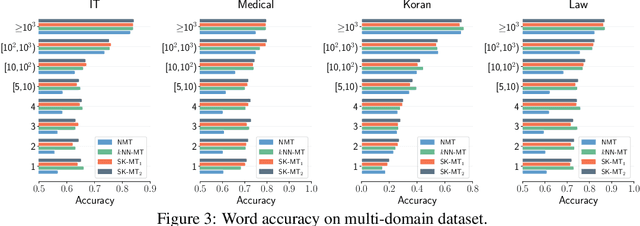
$k$NN-MT is a straightforward yet powerful approach for fast domain adaptation, which directly plugs pre-trained neural machine translation (NMT) models with domain-specific token-level $k$-nearest-neighbor ($k$NN) retrieval to achieve domain adaptation without retraining. Despite being conceptually attractive, $k$NN-MT is burdened with massive storage requirements and high computational complexity since it conducts nearest neighbor searches over the entire reference corpus. In this paper, we propose a simple and scalable nearest neighbor machine translation framework to drastically promote the decoding and storage efficiency of $k$NN-based models while maintaining the translation performance. To this end, we dynamically construct an extremely small datastore for each input via sentence-level retrieval to avoid searching the entire datastore in vanilla $k$NN-MT, based on which we further introduce a distance-aware adapter to adaptively incorporate the $k$NN retrieval results into the pre-trained NMT models. Experiments on machine translation in two general settings, static domain adaptation and online learning, demonstrate that our proposed approach not only achieves almost 90% speed as the NMT model without performance degradation, but also significantly reduces the storage requirements of $k$NN-MT.