 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Contextualized Phrase Retrieval
Mar 25, 2024Phrase-level dense retrieval has shown many appealing characteristics in downstream NLP tasks by leveraging the fine-grained information that phrases offer. In our work, we propose a new task formulation of dense retrieval, cross-lingual contextualized phrase retrieval, which aims to augment cross-lingual applications by addressing polysemy using context information. However, the lack of specific training data and models are the primary challenges to achieve our goal. As a result, we extract pairs of cross-lingual phrases using word alignment information automatically induced from parallel sentences. Subsequently, we train our Cross-lingual Contextualized Phrase Retriever (CCPR) using contrastive learning, which encourages the hidden representations of phrases with similar contexts and semantics to align closely. Comprehensive experiments on both the cross-lingual phrase retrieval task and a downstream task, i.e, machine translation, demonstrate the effectiveness of CCPR. On the phrase retrieval task, CCPR surpasses baselines by a significant margin, achieving a top-1 accuracy that is at least 13 points higher. When utilizing CCPR to augment the large-language-model-based translator, it achieves average gains of 0.7 and 1.5 in BERTScore for translations from X=>En and vice versa, respectively, on WMT16 dataset. Our code and data are available at \url{https://github.com/ghrua/ccpr_release}.
Simple and Scalable Nearest Neighbor Machine Translation
Feb 23, 2023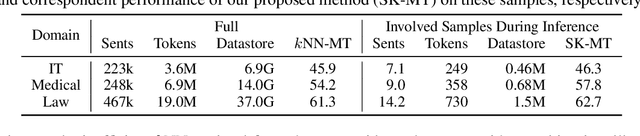
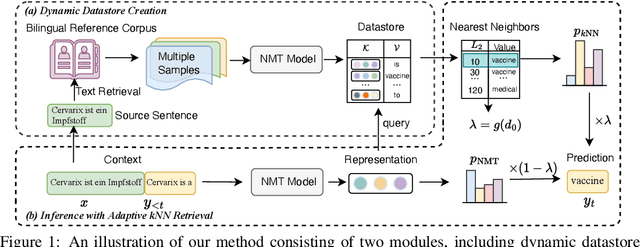
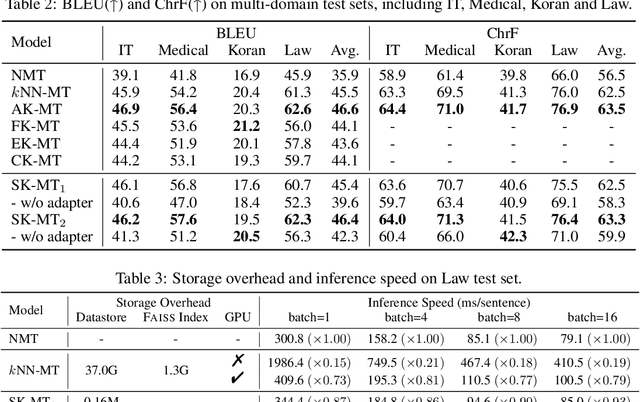
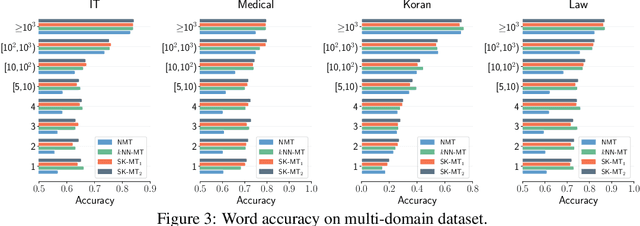
$k$NN-MT is a straightforward yet powerful approach for fast domain adaptation, which directly plugs pre-trained neural machine translation (NMT) models with domain-specific token-level $k$-nearest-neighbor ($k$NN) retrieval to achieve domain adaptation without retraining. Despite being conceptually attractive, $k$NN-MT is burdened with massive storage requirements and high computational complexity since it conducts nearest neighbor searches over the entire reference corpus. In this paper, we propose a simple and scalable nearest neighbor machine translation framework to drastically promote the decoding and storage efficiency of $k$NN-based models while maintaining the translation performance. To this end, we dynamically construct an extremely small datastore for each input via sentence-level retrieval to avoid searching the entire datastore in vanilla $k$NN-MT, based on which we further introduce a distance-aware adapter to adaptively incorporate the $k$NN retrieval results into the pre-trained NMT models. Experiments on machine translation in two general settings, static domain adaptation and online learning, demonstrate that our proposed approach not only achieves almost 90% speed as the NMT model without performance degradation, but also significantly reduces the storage requirements of $k$NN-MT.
DirectQE: Direct Pretraining for Machine Translation Quality Estimation
May 15, 2021
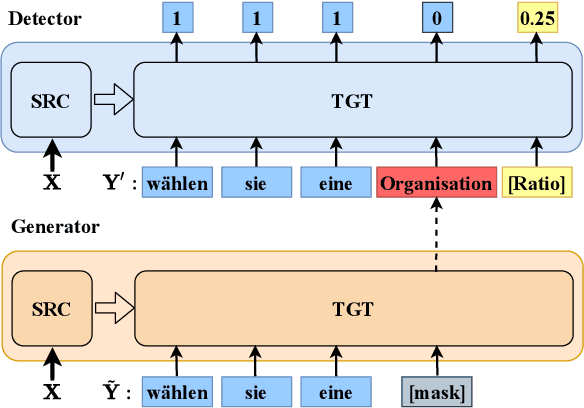
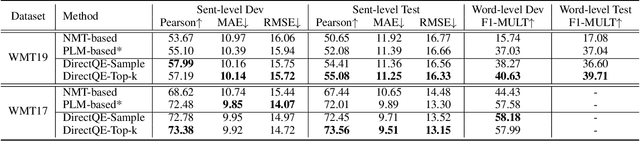
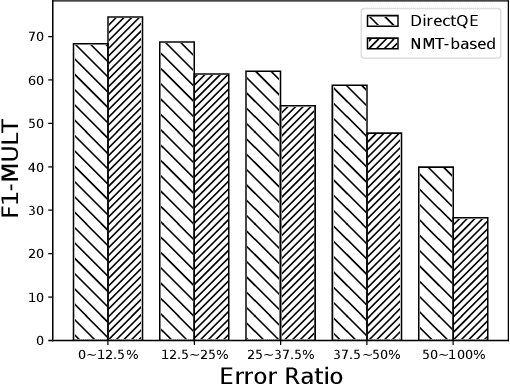
Machine Translation Quality Estimation (QE) is a task of predicting the quality of machine translations without relying on any reference. Recently, the predictor-estimator framework trains the predictor as a feature extractor, which leverages the extra parallel corpora without QE labels, achieving promising QE performance. However, we argue that there are gaps between the predictor and the estimator in both data quality and training objectives, which preclude QE models from benefiting from a large number of parallel corpora more directly. We propose a novel framework called DirectQE that provides a direct pretraining for QE tasks. In DirectQE, a generator is trained to produce pseudo data that is closer to the real QE data, and a detector is pretrained on these data with novel objectives that are akin to the QE task. Experiments on widely used benchmarks show that DirectQE outperforms existing methods, without using any pretraining models such as BERT. We also give extensive analyses showing how fixing the two gaps contributes to our improvements.