 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Preserving Machine Translation at the Inference Stage: A New Task and Benchmark
Mar 16, 2026Current online translation services require sending user text to cloud servers, posing a risk of privacy leakage when the text contains sensitive information. This risk hinders the application of online translation services in privacy-sensitive scenarios. One way to mitigate this risk for online translation services is introducing privacy protection mechanisms targeting the inference stage of translation models. However, compared to subfields of NLP like text classification and summarization, the machine translation research community has limited exploration of privacy protection during the inference stage. There is no clearly defined privacy protection task for the inference stage, dedicated evaluation datasets and metrics, and reference benchmark methods. The absence of these elements has seriously constrained researchers' in-depth exploration of this direction. To bridge this gap, this paper proposes a novel "Privacy-Preserving Machine Translation" (PPMT) task, aiming to protect the private information in text during the model inference stage. For this task, we constructed three benchmark test datasets, designed corresponding evaluation metrics, and proposed a series of benchmark methods as a starting point for this task. The definition of privacy is complex and diverse. Considering that named entities often contain a large amount of personal privacy and commercial secrets, we have focused our research on protecting only the named entity's privacy in the text. We expect this research work will provide a new perspective and a solid foundation for the privacy protection problem in machine translation.
An Energy-based Model for Word-level AutoCompletion in Computer-aided Translation
Jul 29, 2024Word-level AutoCompletion(WLAC) is a rewarding yet challenging task in Computer-aided Translation. Existing work addresses this task through a classification model based on a neural network that maps the hidden vector of the input context into its corresponding label (i.e., the candidate target word is treated as a label). Since the context hidden vector itself does not take the label into account and it is projected to the label through a linear classifier, the model can not sufficiently leverage valuable information from the source sentence as verified in our experiments, which eventually hinders its overall performance. To alleviate this issue, this work proposes an energy-based model for WLAC, which enables the context hidden vector to capture crucial information from the source sentence. Unfortunately, training and inference suffer from efficiency and effectiveness challenges, thereby we employ three simple yet effective strategies to put our model into practice. Experiments on four standard benchmarks demonstrate that our reranking-based approach achieves substantial improvements (about 6.07%) over the previous state-of-the-art model. Further analyses show that each strategy of our approach contributes to the final performance.
Rethinking Word-Level Auto-Completion in Computer-Aided Translation
Oct 24, 2023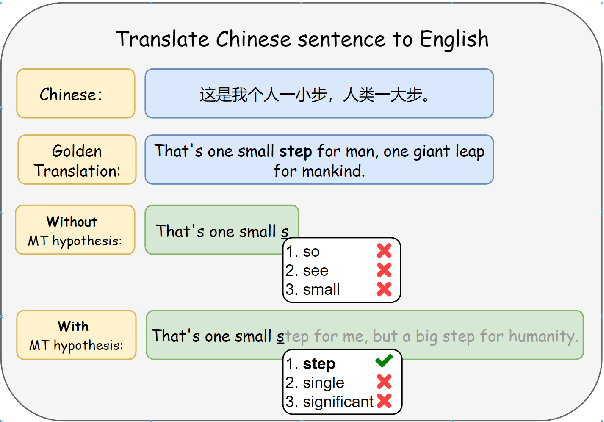
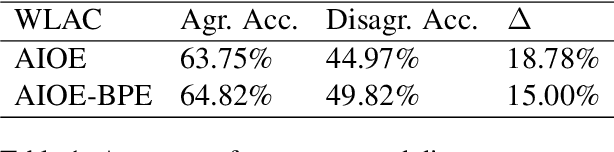

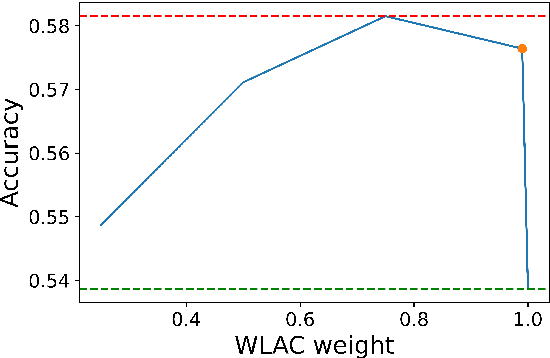
Word-Level Auto-Completion (WLAC) plays a crucial role in Computer-Assisted Translation. It aims at providing word-level auto-completion suggestions for human translators. While previous studies have primarily focused on designing complex model architectures, this paper takes a different perspective by rethinking the fundamental question: what kind of words are good auto-completions? We introduce a measurable criterion to answer this question and discover that existing WLAC models often fail to meet this criterion. Building upon this observation, we propose an effective approach to enhance WLAC performance by promoting adherence to the criterion. Notably, the proposed approach is general and can be applied to various encoder-based architectures. Through extensive experiments, we demonstrate that our approach outperforms the top-performing system submitted to the WLAC shared tasks in WMT2022, while utilizing significantly smaller model sizes.
On Synthetic Data for Back Translation
Oct 20, 2023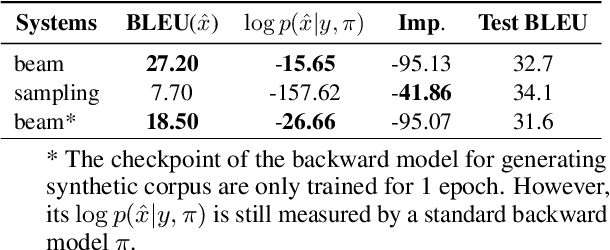
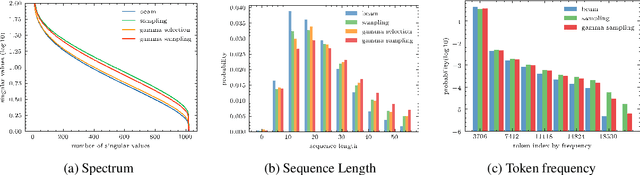

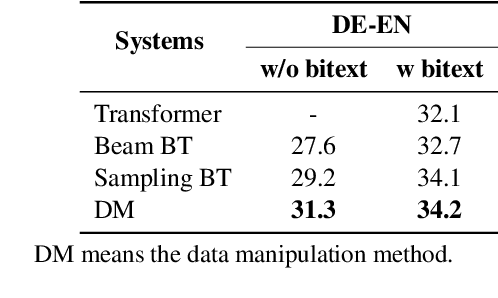
Back translation (BT) is one of the most significant technologies in NMT research fields. Existing attempts on BT share a common characteristic: they employ either beam search or random sampling to generate synthetic data with a backward model but seldom work studies the role of synthetic data in the performance of BT. This motivates us to ask a fundamental question: {\em what kind of synthetic data contributes to BT performance?} Through both theoretical and empirical studies, we identify two key factors on synthetic data controlling the back-translation NMT performance, which are quality and importance. Furthermore, based on our findings, we propose a simple yet effective method to generate synthetic data to better trade off both factors so as to yield a better performance for BT. We run extensive experiments on WMT14 DE-EN, EN-DE, and RU-EN benchmark tasks. By employing our proposed method to generate synthetic data, our BT model significantly outperforms the standard BT baselines (i.e., beam and sampling based methods for data generation), which proves the effectiveness of our proposed methods.
Rethinking Translation Memory Augmented Neural Machine Translation
Jun 12, 2023
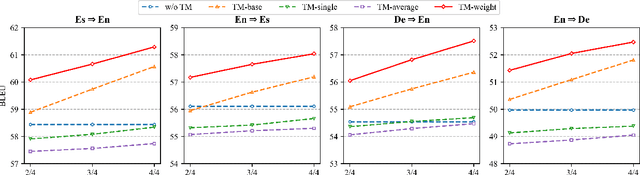
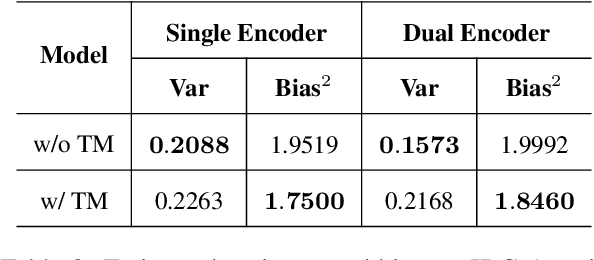
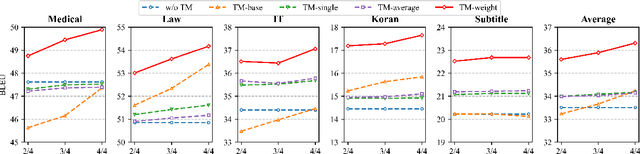
This paper rethinks translation memory augmented neural machine translation (TM-augmented NMT) from two perspectives, i.e., a probabilistic view of retrieval and the variance-bias decomposition principle. The finding demonstrates that TM-augmented NMT is good at the ability of fitting data (i.e., lower bias) but is more sensitive to the fluctuations in the training data (i.e., higher variance), which provides an explanation to a recently reported contradictory phenomenon on the same translation task: TM-augmented NMT substantially advances vanilla NMT under the high-resource scenario whereas it fails under the low-resource scenario. Then we propose a simple yet effective TM-augmented NMT model to promote the variance and address the contradictory phenomenon. Extensive experiments show that the proposed TM-augmented NMT achieves consistent gains over both conventional NMT and existing TM-augmented NMT under two variance-preferable (low-resource and plug-and-play) scenarios as well as the high-resource scenario.
Effidit: Your AI Writing Assistant
Aug 04, 2022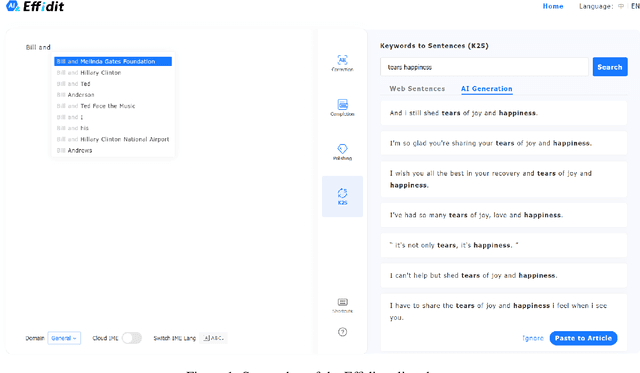

In this technical report, we introduce Effidit (Efficient and Intelligent Editing), a digital writing assistant that facilitates users to write higher-quality text more efficiently by using artificial intelligence (AI) technologies. Previous writing assistants typically provide the function of error checking (to detect and correct spelling and grammatical errors) and limited text-rewriting functionality. With the emergence of large-scale neural language models, some systems support automatically completing a sentence or a paragraph. In Effidit, we significantly expand the capacities of a writing assistant by providing functions in five categories: text completion, error checking, text polishing, keywords to sentences (K2S), and cloud input methods (cloud IME). In the text completion category, Effidit supports generation-based sentence completion, retrieval-based sentence completion, and phrase completion. In contrast, many other writing assistants so far only provide one or two of the three functions. For text polishing, we have three functions: (context-aware) phrase polishing, sentence paraphrasing, and sentence expansion, whereas many other writing assistants often support one or two functions in this category. The main contents of this report include major modules of Effidit, methods for implementing these modules, and evaluation results of some key methods.
Visualizing the Relationship Between Encoded Linguistic Information and Task Performance
Mar 29, 2022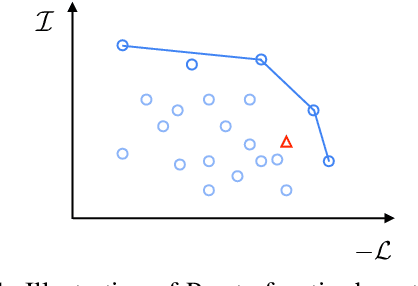
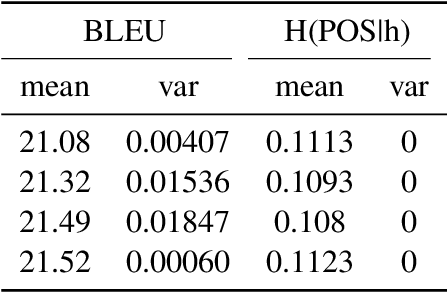
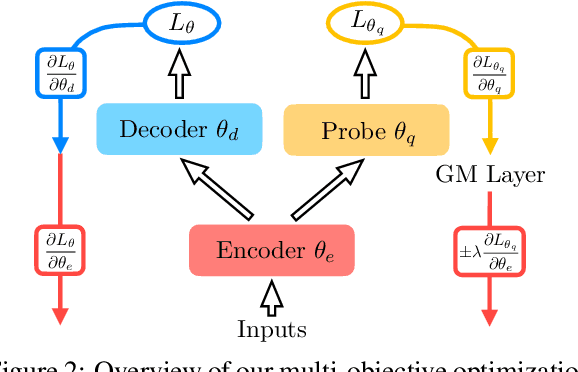
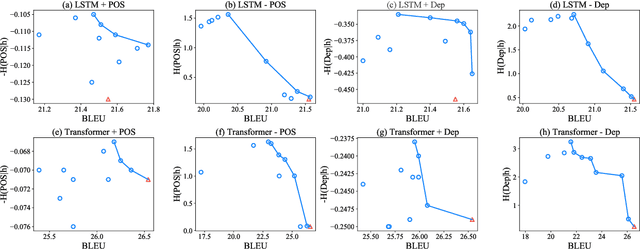
Probing is popular to analyze whether linguistic information can be captured by a well-trained deep neural model, but it is hard to answer how the change of the encoded linguistic information will affect task performance. To this end, we study the dynamic relationship between the encoded linguistic information and task performance from the viewpoint of Pareto Optimality. Its key idea is to obtain a set of models which are Pareto-optimal in terms of both objectives. From this viewpoint, we propose a method to optimize the Pareto-optimal models by formalizing it as a multi-objective optimization problem. We conduct experiments on two popular NLP tasks, i.e., machine translation and language modeling, and investigate the relationship between several kinds of linguistic information and task performances. Experimental results demonstrate that the proposed method is better than a baseline method. Our empirical findings suggest that some syntactic information is helpful for NLP tasks whereas encoding more syntactic information does not necessarily lead to better performance, because the model architecture is also an important factor.
Investigating Data Variance in Evaluations of Automatic Machine Translation Metrics
Mar 29, 2022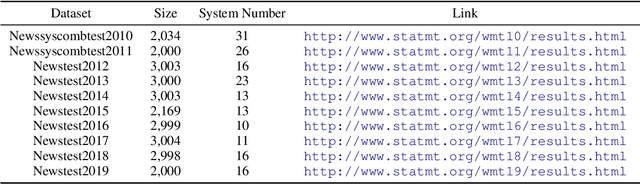
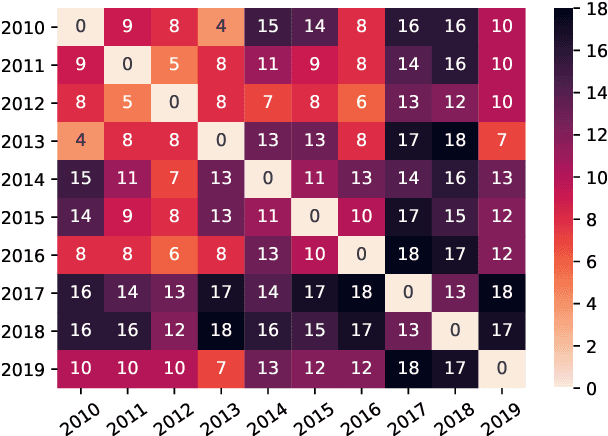
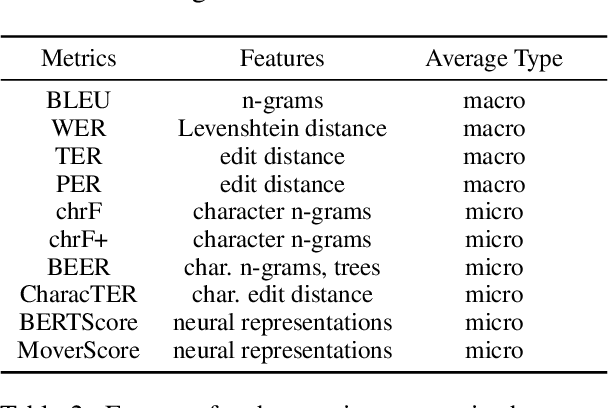
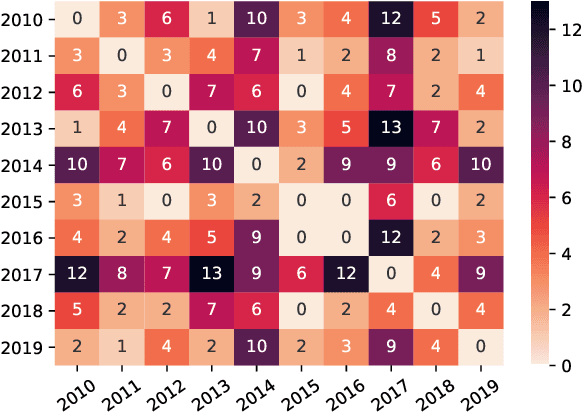
Current practices in metric evaluation focus on one single dataset, e.g., Newstest dataset in each year's WMT Metrics Shared Task. However, in this paper, we qualitatively and quantitatively show that the performances of metrics are sensitive to data. The ranking of metrics varies when the evaluation is conducted on different datasets. Then this paper further investigates two potential hypotheses, i.e., insignificant data points and the deviation of Independent and Identically Distributed (i.i.d) assumption, which may take responsibility for the issue of data variance. In conclusion, our findings suggest that when evaluating automatic translation metrics, researchers should take data variance into account and be cautious to claim the result on a single dataset, because it may leads to inconsistent results with most of other datasets.
Exploring and Adapting Chinese GPT to Pinyin Input Method
Mar 02, 2022
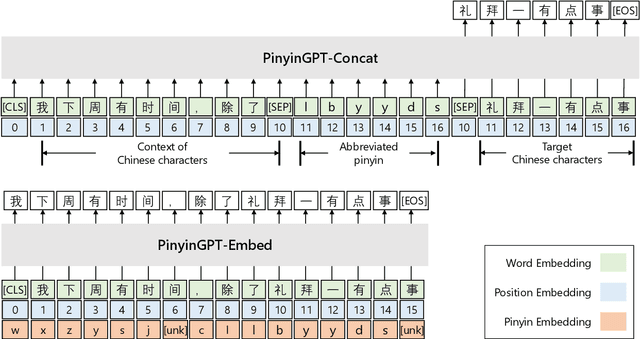

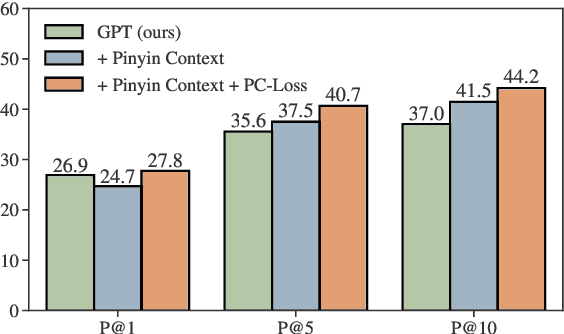
While GPT has become the de-facto method for text generation tasks, its application to pinyin input method remains unexplored. In this work, we make the first exploration to leverage Chinese GPT for pinyin input method. We find that a frozen GPT achieves state-of-the-art performance on perfect pinyin. However, the performance drops dramatically when the input includes abbreviated pinyin. A reason is that an abbreviated pinyin can be mapped to many perfect pinyin, which links to even larger number of Chinese characters. We mitigate this issue with two strategies, including enriching the context with pinyin and optimizing the training process to help distinguish homophones. To further facilitate the evaluation of pinyin input method, we create a dataset consisting of 270K instances from 15 domains. Results show that our approach improves performance on abbreviated pinyin across all domains. Model analysis demonstrates that both strategies contribute to the performance boost.
GWLAN: General Word-Level AutocompletioN for Computer-Aided Translation
May 31, 2021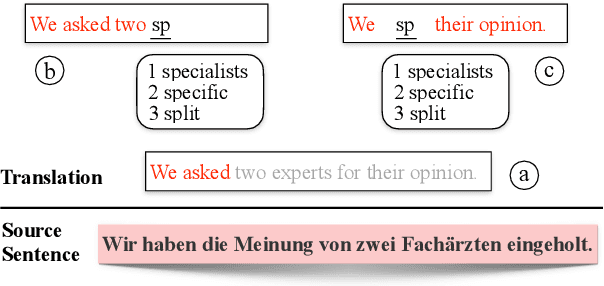
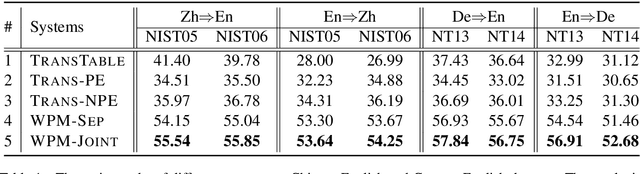
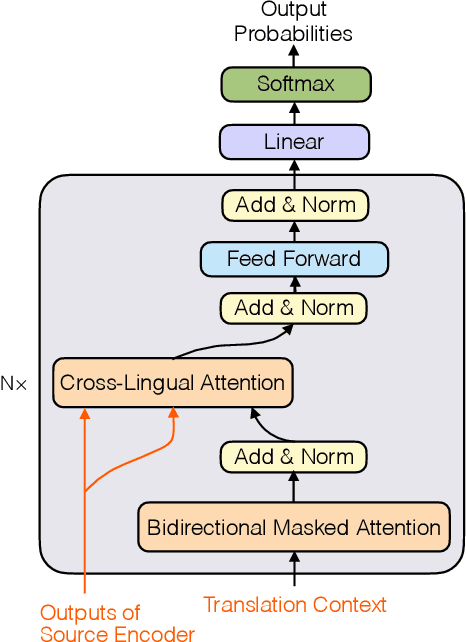
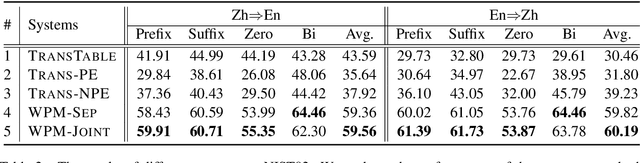
Computer-aided translation (CAT), the use of software to assist a human translator in the translation process, has been proven to be useful in enhancing the productivity of human translators. Autocompletion, which suggests translation results according to the text pieces provided by human translators, is a core function of CAT. There are two limitations in previous research in this line. First, most research works on this topic focus on sentence-level autocompletion (i.e., generating the whole translation as a sentence based on human input), but word-level autocompletion is under-explored so far. Second, almost no public benchmarks are available for the autocompletion task of CAT. This might be among the reasons why research progress in CAT is much slower compared to automatic MT. In this paper, we propose the task of general word-level autocompletion (GWLAN) from a real-world CAT scenario, and construct the first public benchmark to facilitate research in this topic. In addition, we propose an effective method for GWLAN and compare it with several strong baselines. Experiments demonstrate that our proposed method can give significantly more accurate predictions than the baseline methods on our benchmark datasets.