 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmage: Non-Autoregressive Text-to-Image Generation
Dec 22, 2023Autoregressive and diffusion models drive the recent breakthroughs on text-to-image generation. Despite their huge success of generating high-realistic images, a common shortcoming of these models is their high inference latency - autoregressive models run more than a thousand times successively to produce image tokens and diffusion models convert Gaussian noise into images with many hundreds of denoising steps. In this work, we explore non-autoregressive text-to-image models that efficiently generate hundreds of image tokens in parallel. We develop many model variations with different learning and inference strategies, initialized text encoders, etc. Compared with autoregressive baselines that needs to run one thousand times, our model only runs 16 times to generate images of competitive quality with an order of magnitude lower inference latency. Our non-autoregressive model with 346M parameters generates an image of 256$\times$256 with about one second on one V100 GPU.
Trends in Integration of Knowledge and Large Language Models: A Survey and Taxonomy of Methods, Benchmarks, and Applications
Nov 10, 2023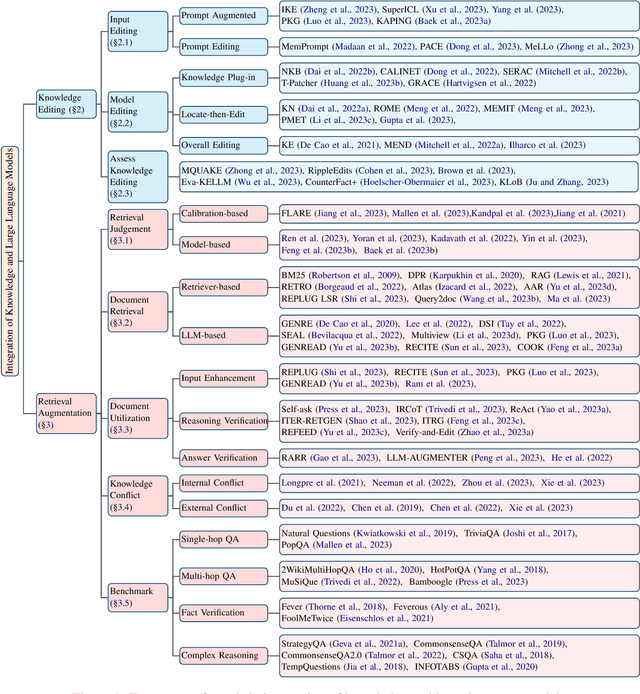
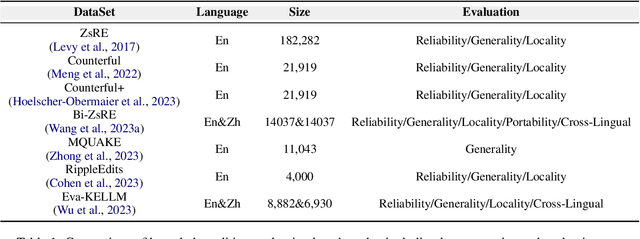
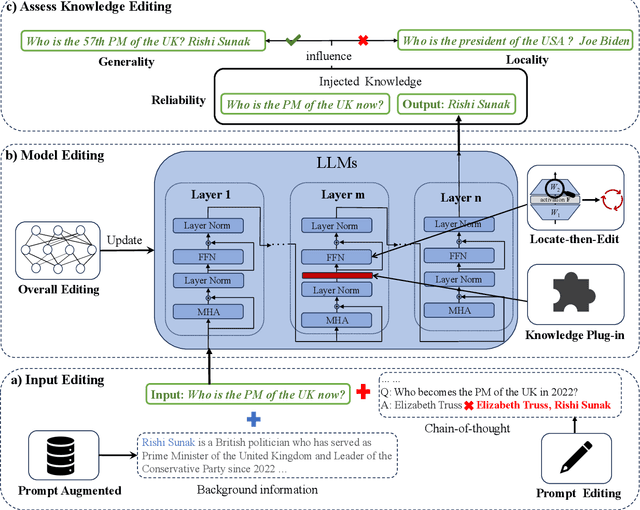
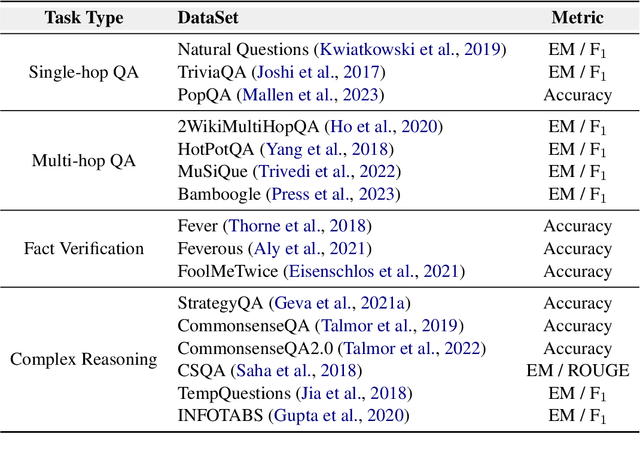
Large language models (LLMs) exhibit superior performance on various natural language tasks, but they are susceptible to issues stemming from outdated data and domain-specific limitations. In order to address these challenges, researchers have pursued two primary strategies, knowledge editing and retrieval augmentation, to enhance LLMs by incorporating external information from different aspects. Nevertheless, there is still a notable absence of a comprehensive survey. In this paper, we propose a review to discuss the trends in integration of knowledge and large language models, including taxonomy of methods, benchmarks, and applications. In addition, we conduct an in-depth analysis of different methods and point out potential research directions in the future. We hope this survey offers the community quick access and a comprehensive overview of this research area, with the intention of inspiring future research endeavors.
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions
Nov 09, 2023The emergence of large language models (LLMs) has marked a significant breakthrough in natural language processing (NLP), leading to remarkable advancements in text understanding and generation. Nevertheless, alongside these strides, LLMs exhibit a critical tendency to produce hallucinations, resulting in content that is inconsistent with real-world facts or user inputs. This phenomenon poses substantial challenges to their practical deployment and raises concerns over the reliability of LLMs in real-world scenarios, which attracts increasing attention to detect and mitigate these hallucinations. In this survey, we aim to provide a thorough and in-depth overview of recent advances in the field of LLM hallucinations. We begin with an innovative taxonomy of LLM hallucinations, then delve into the factors contributing to hallucinations. Subsequently, we present a comprehensive overview of hallucination detection methods and benchmarks. Additionally, representative approaches designed to mitigate hallucinations are introduced accordingly. Finally, we analyze the challenges that highlight the current limitations and formulate open questions, aiming to delineate pathways for future research on hallucinations in LLMs.
Retrieval-Generation Synergy Augmented Large Language Models
Oct 08, 2023Large language models augmented with task-relevant documents have demonstrated impressive performance on knowledge-intensive tasks. However, regarding how to obtain effective documents, the existing methods are mainly divided into two categories. One is to retrieve from an external knowledge base, and the other is to utilize large language models to generate documents. We propose an iterative retrieval-generation collaborative framework. It is not only able to leverage both parametric and non-parametric knowledge, but also helps to find the correct reasoning path through retrieval-generation interactions, which is very important for tasks that require multi-step reasoning. We conduct experiments on four question answering datasets, including single-hop QA and multi-hop QA tasks. Empirical results show that our method significantly improves the reasoning ability of large language models and outperforms previous baselines.
SkillNet-X: A Multilingual Multitask Model with Sparsely Activated Skills
Jun 28, 2023Traditional multitask learning methods basically can only exploit common knowledge in task- or language-wise, which lose either cross-language or cross-task knowledge. This paper proposes a general multilingual multitask model, named SkillNet-X, which enables a single model to tackle many different tasks from different languages. To this end, we define several language-specific skills and task-specific skills, each of which corresponds to a skill module. SkillNet-X sparsely activates parts of the skill modules which are relevant either to the target task or the target language. Acting as knowledge transit hubs, skill modules are capable of absorbing task-related knowledge and language-related knowledge consecutively. Based on Transformer, we modify the multi-head attention layer and the feed forward network layer to accommodate skill modules. We evaluate SkillNet-X on eleven natural language understanding datasets in four languages. Results show that SkillNet-X performs better than task-specific baselines and two multitask learning baselines (i.e., dense joint model and Mixture-of-Experts model). Furthermore, skill pre-training further improves the performance of SkillNet-X on almost all datasets. To investigate the generalization of our model, we conduct experiments on two new tasks and find that SkillNet-X significantly outperforms baselines.
Improved Visual Story Generation with Adaptive Context Modeling
May 26, 2023
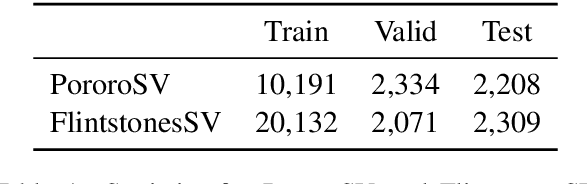
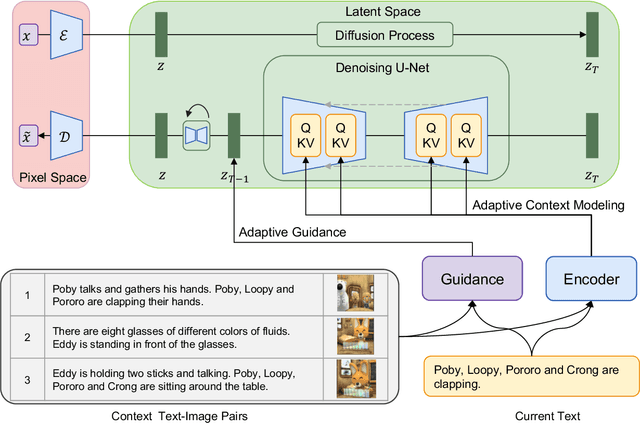
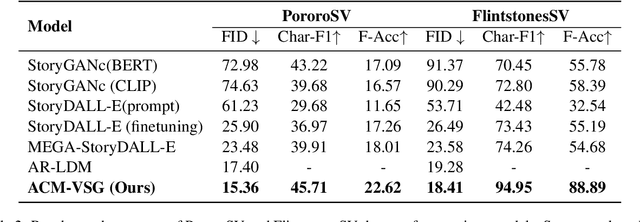
Diffusion models developed on top of powerful text-to-image generation models like Stable Diffusion achieve remarkable success in visual story generation. However, the best-performing approach considers historically generated results as flattened memory cells, ignoring the fact that not all preceding images contribute equally to the generation of the characters and scenes at the current stage. To address this, we present a simple method that improves the leading system with adaptive context modeling, which is not only incorporated in the encoder but also adopted as additional guidance in the sampling stage to boost the global consistency of the generated story. We evaluate our model on PororoSV and FlintstonesSV datasets and show that our approach achieves state-of-the-art FID scores on both story visualization and continuation scenarios. We conduct detailed model analysis and show that our model excels at generating semantically consistent images for stories.
One Model, Multiple Modalities: A Sparsely Activated Approach for Text, Sound, Image, Video and Code
May 12, 2022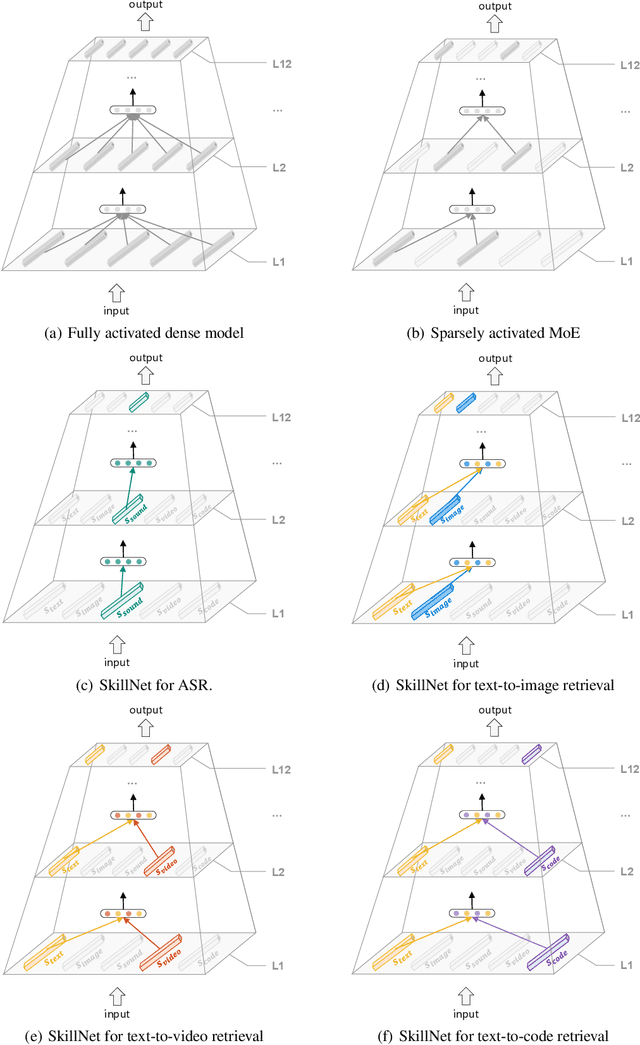

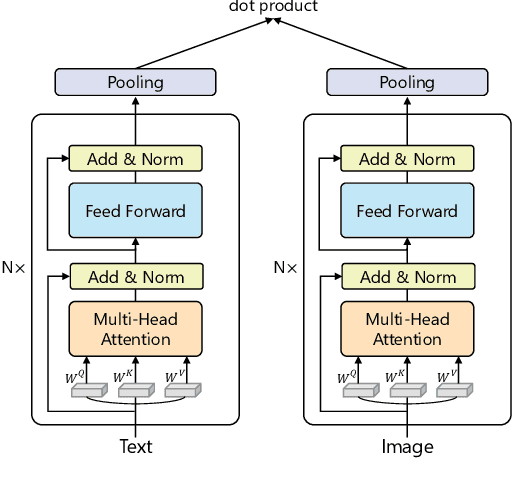
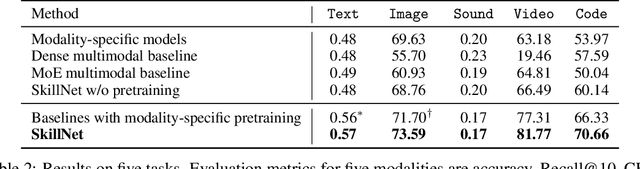
People perceive the world with multiple senses (e.g., through hearing sounds, reading words and seeing objects). However, most existing AI systems only process an individual modality. This paper presents an approach that excels at handling multiple modalities of information with a single model. In our "{SkillNet}" model, different parts of the parameters are specialized for processing different modalities. Unlike traditional dense models that always activate all the model parameters, our model sparsely activates parts of the parameters whose skills are relevant to the task. Such model design enables SkillNet to learn skills in a more interpretable way. We develop our model for five modalities including text, image, sound, video and code. Results show that, SkillNet performs comparably to five modality-specific fine-tuned models. Moreover, our model supports self-supervised pretraining with the same sparsely activated way, resulting in better initialized parameters for different modalities. We find that pretraining significantly improves the performance of SkillNet on five modalities, on par with or even better than baselines with modality-specific pretraining. On the task of Chinese text-to-image retrieval, our final system achieves higher accuracy than existing leading systems including Wukong{ViT-B} and Wenlan 2.0 while using less number of activated parameters.
Pretraining Chinese BERT for Detecting Word Insertion and Deletion Errors
Apr 26, 2022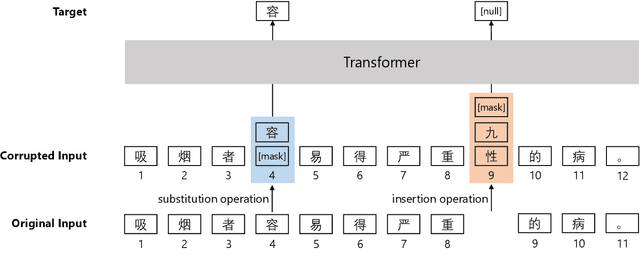

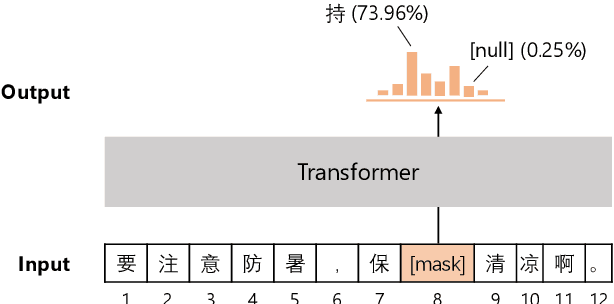

Chinese BERT models achieve remarkable progress in dealing with grammatical errors of word substitution. However, they fail to handle word insertion and deletion because BERT assumes the existence of a word at each position. To address this, we present a simple and effective Chinese pretrained model. The basic idea is to enable the model to determine whether a word exists at a particular position. We achieve this by introducing a special token \texttt{[null]}, the prediction of which stands for the non-existence of a word. In the training stage, we design pretraining tasks such that the model learns to predict \texttt{[null]} and real words jointly given the surrounding context. In the inference stage, the model readily detects whether a word should be inserted or deleted with the standard masked language modeling function. We further create an evaluation dataset to foster research on word insertion and deletion. It includes human-annotated corrections for 7,726 erroneous sentences. Results show that existing Chinese BERT performs poorly on detecting insertion and deletion errors. Our approach significantly improves the F1 scores from 24.1\% to 78.1\% for word insertion and from 26.5\% to 68.5\% for word deletion, respectively.
MarkBERT: Marking Word Boundaries Improves Chinese BERT
Mar 12, 2022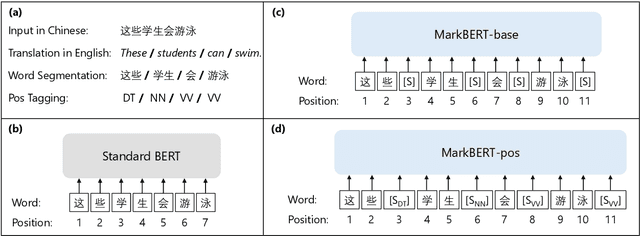
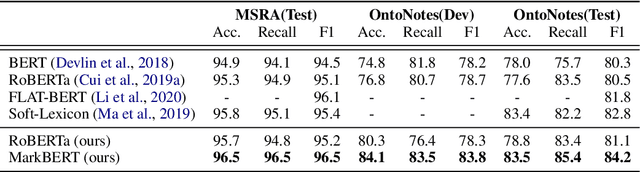
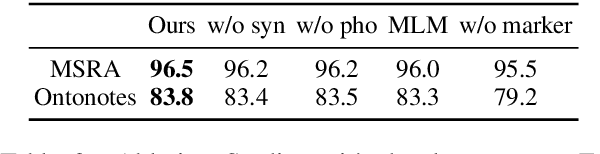
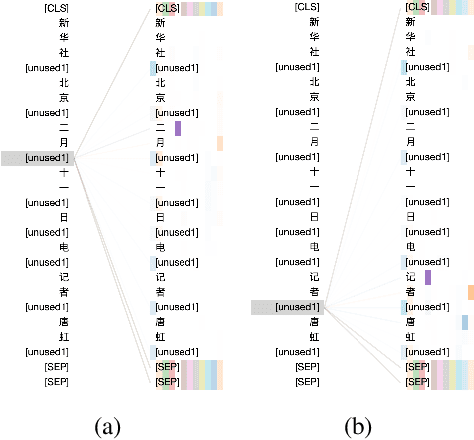
We present a Chinese BERT model dubbed MarkBERT that uses word information. Existing word-based BERT models regard words as basic units, however, due to the vocabulary limit of BERT, they only cover high-frequency words and fall back to character level when encountering out-of-vocabulary (OOV) words. Different from existing works, MarkBERT keeps the vocabulary being Chinese characters and inserts boundary markers between contiguous words. Such design enables the model to handle any words in the same way, no matter they are OOV words or not. Besides, our model has two additional benefits: first, it is convenient to add word-level learning objectives over markers, which is complementary to traditional character and sentence-level pre-training tasks; second, it can easily incorporate richer semantics such as POS tags of words by replacing generic markers with POS tag-specific markers. MarkBERT pushes the state-of-the-art of Chinese named entity recognition from 95.4\% to 96.5\% on the MSRA dataset and from 82.8\% to 84.2\% on the OntoNotes dataset, respectively. Compared to previous word-based BERT models, MarkBERT achieves better accuracy on text classification, keyword recognition, and semantic similarity tasks.
"Is Whole Word Masking Always Better for Chinese BERT?": Probing on Chinese Grammatical Error Correction
Mar 02, 2022
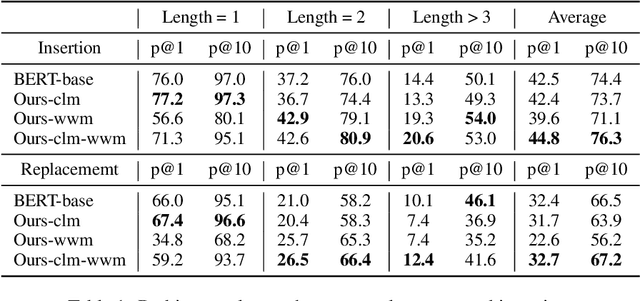

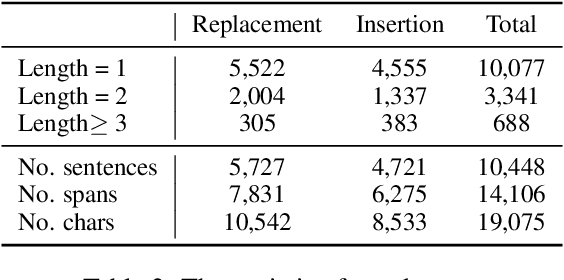
Whole word masking (WWM), which masks all subwords corresponding to a word at once, makes a better English BERT model. For the Chinese language, however, there is no subword because each token is an atomic character. The meaning of a word in Chinese is different in that a word is a compositional unit consisting of multiple characters. Such difference motivates us to investigate whether WWM leads to better context understanding ability for Chinese BERT. To achieve this, we introduce two probing tasks related to grammatical error correction and ask pretrained models to revise or insert tokens in a masked language modeling manner. We construct a dataset including labels for 19,075 tokens in 10,448 sentences. We train three Chinese BERT models with standard character-level masking (CLM), WWM, and a combination of CLM and WWM, respectively. Our major findings are as follows: First, when one character needs to be inserted or replaced, the model trained with CLM performs the best. Second, when more than one character needs to be handled, WWM is the key to better performance. Finally, when being fine-tuned on sentence-level downstream tasks, models trained with different masking strategies perform comparably.