 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkBERT: Marking Word Boundaries Improves Chinese BERT
Paper and Code
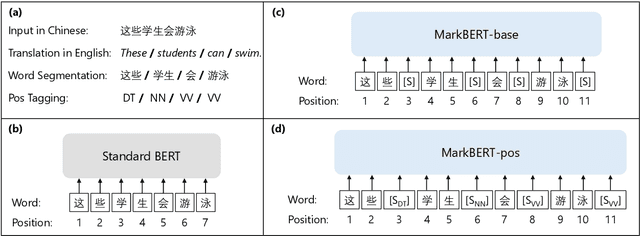
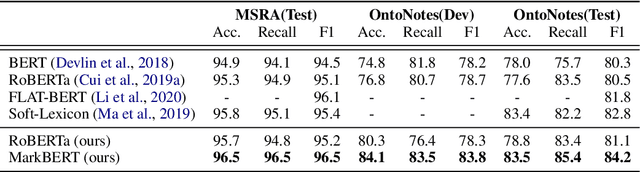
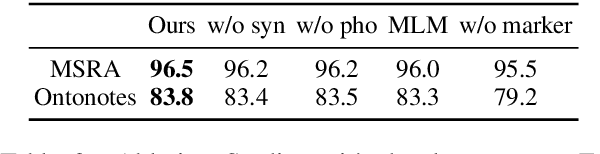
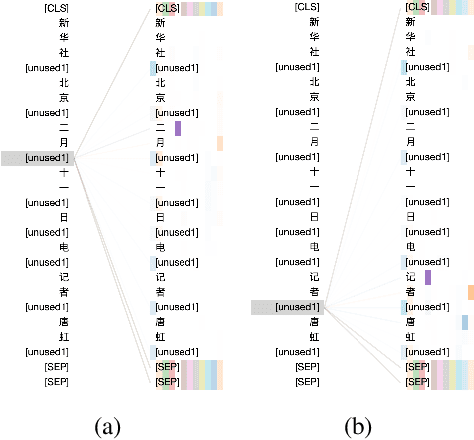
We present a Chinese BERT model dubbed MarkBERT that uses word information. Existing word-based BERT models regard words as basic units, however, due to the vocabulary limit of BERT, they only cover high-frequency words and fall back to character level when encountering out-of-vocabulary (OOV) words. Different from existing works, MarkBERT keeps the vocabulary being Chinese characters and inserts boundary markers between contiguous words. Such design enables the model to handle any words in the same way, no matter they are OOV words or not. Besides, our model has two additional benefits: first, it is convenient to add word-level learning objectives over markers, which is complementary to traditional character and sentence-level pre-training tasks; second, it can easily incorporate richer semantics such as POS tags of words by replacing generic markers with POS tag-specific markers. MarkBERT pushes the state-of-the-art of Chinese named entity recognition from 95.4\% to 96.5\% on the MSRA dataset and from 82.8\% to 84.2\% on the OntoNotes dataset, respectively. Compared to previous word-based BERT models, MarkBERT achieves better accuracy on text classification, keyword recognition, and semantic similarity tasks.