 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey
Jan 15, 2026Issue resolution, a complex Software Engineering (SWE) task integral to real-world development, has emerged as a compelling challenge for artificial intelligence. The establishment of benchmarks like SWE-bench revealed this task as profoundly difficult for large language models, thereby significantly accelerating the evolution of autonomous coding agents. This paper presents a systematic survey of this emerging domain. We begin by examining data construction pipelines, covering automated collection and synthesis approaches. We then provide a comprehensive analysis of methodologies, spanning training-free frameworks with their modular components to training-based techniques, including supervised fine-tuning and reinforcement learning. Subsequently, we discuss critical analyses of data quality and agent behavior, alongside practical applications. Finally, we identify key challenges and outline promising directions for future research. An open-source repository is maintained at https://github.com/DeepSoftwareAnalytics/Awesome-Issue-Resolution to serve as a dynamic resource in this field.
LangGPS: Language Separability Guided Data Pre-Selection for Joint Multilingual Instruction Tuning
Nov 13, 2025Joint multilingual instruction tuning is a widely adopted approach to improve the multilingual instruction-following ability and downstream performance of large language models (LLMs), but the resulting multilingual capability remains highly sensitive to the composition and selection of the training data. Existing selection methods, often based on features like text quality, diversity, or task relevance, typically overlook the intrinsic linguistic structure of multilingual data. In this paper, we propose LangGPS, a lightweight two-stage pre-selection framework guided by language separability which quantifies how well samples in different languages can be distinguished in the model's representation space. LangGPS first filters training data based on separability scores and then refines the subset using existing selection methods. Extensive experiments across six benchmarks and 22 languages demonstrate that applying LangGPS on top of existing selection methods improves their effectiveness and generalizability in multilingual training, especially for understanding tasks and low-resource languages. Further analysis reveals that highly separable samples facilitate the formation of clearer language boundaries and support faster adaptation, while low-separability samples tend to function as bridges for cross-lingual alignment. Besides, we also find that language separability can serve as an effective signal for multilingual curriculum learning, where interleaving samples with diverse separability levels yields stable and generalizable gains. Together, we hope our work offers a new perspective on data utility in multilingual contexts and support the development of more linguistically informed LLMs.
HardcoreLogic: Challenging Large Reasoning Models with Long-tail Logic Puzzle Games
Oct 14, 2025Large Reasoning Models (LRMs) have demonstrated impressive performance on complex tasks, including logical puzzle games that require deriving solutions satisfying all constraints. However, whether they can flexibly apply appropriate rules to varying conditions, particularly when faced with non-canonical game variants, remains an open question. Existing corpora focus on popular puzzles like 9x9 Sudoku, risking overfitting to canonical formats and memorization of solution patterns, which can mask deficiencies in understanding novel rules or adapting strategies to new variants. To address this, we introduce HardcoreLogic, a challenging benchmark of over 5,000 puzzles across 10 games, designed to test the robustness of LRMs on the "long-tail" of logical games. HardcoreLogic systematically transforms canonical puzzles through three dimensions: Increased Complexity (IC), Uncommon Elements (UE), and Unsolvable Puzzles (UP), reducing reliance on shortcut memorization. Evaluations on a diverse set of LRMs reveal significant performance drops, even for models achieving top scores on existing benchmarks, indicating heavy reliance on memorized stereotypes. While increased complexity is the dominant source of difficulty, models also struggle with subtle rule variations that do not necessarily increase puzzle difficulty. Our systematic error analysis on solvable and unsolvable puzzles further highlights gaps in genuine reasoning. Overall, HardcoreLogic exposes the limitations of current LRMs and establishes a benchmark for advancing high-level logical reasoning.
SWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks
Jun 12, 2025Constructing large-scale datasets for the GitHub issue resolution task is crucial for both training and evaluating the software engineering capabilities of Large Language Models (LLMs). However, the traditional process for creating such benchmarks is notoriously challenging and labor-intensive, particularly in the stages of setting up evaluation environments, grading test outcomes, and validating task instances. In this paper, we propose SWE-Factory, an automated pipeline designed to address these challenges. To tackle these issues, our pipeline integrates three core automated components. First, we introduce SWE-Builder, a multi-agent system that automates evaluation environment construction, which employs four specialized agents that work in a collaborative, iterative loop and leverages an environment memory pool to enhance efficiency. Second, we introduce a standardized, exit-code-based grading method that eliminates the need for manually writing custom parsers. Finally, we automate the fail2pass validation process using these reliable exit code signals. Experiments on 671 issues across four programming languages show that our pipeline can effectively construct valid task instances; for example, with GPT-4.1-mini, our SWE-Builder constructs 269 valid instances at $0.045 per instance, while with Gemini-2.5-flash, it achieves comparable performance at the lowest cost of $0.024 per instance. We also demonstrate that our exit-code-based grading achieves 100% accuracy compared to manual inspection, and our automated fail2pass validation reaches a precision of 0.92 and a recall of 1.00. We hope our automated pipeline will accelerate the collection of large-scale, high-quality GitHub issue resolution datasets for both training and evaluation. Our code and datasets are released at https://github.com/DeepSoftwareAnalytics/swe-factory.
Not All Models Suit Expert Offloading: On Local Routing Consistency of Mixture-of-Expert Models
May 21, 2025Mixture-of-Experts (MoE) enables efficient scaling of large language models (LLMs) with sparsely activated experts during inference. To effectively deploy large MoE models on memory-constrained devices, many systems introduce *expert offloading* that caches a subset of experts in fast memory, leaving others on slow memory to run on CPU or load on demand. While some research has exploited the locality of expert activations, where consecutive tokens activate similar experts, the degree of this **local routing consistency** varies across models and remains understudied. In this paper, we propose two metrics to measure local routing consistency of MoE models: (1) **Segment Routing Best Performance (SRP)**, which evaluates how well a fixed group of experts can cover the needs of a segment of tokens, and (2) **Segment Cache Best Hit Rate (SCH)**, which measures the optimal segment-level cache hit rate under a given cache size limit. We analyzed 20 MoE LLMs with diverse sizes and architectures and found that models that apply MoE on every layer and do not use shared experts exhibit the highest local routing consistency. We further showed that domain-specialized experts contribute more to routing consistency than vocabulary-specialized ones, and that most models can balance between cache effectiveness and efficiency with cache sizes approximately 2x the active experts. These findings pave the way for memory-efficient MoE design and deployment without compromising inference speed. We publish the code for replicating experiments at https://github.com/ljcleo/moe-lrc .
Is PRM Necessary? Problem-Solving RL Implicitly Induces PRM Capability in LLMs
May 16, 2025The development of reasoning capabilities represents a critical frontier in large language models (LLMs) research, where reinforcement learning (RL) and process reward models (PRMs) have emerged as predominant methodological frameworks. Contrary to conventional wisdom, empirical evidence from DeepSeek-R1 demonstrates that pure RL training focused on mathematical problem-solving can progressively enhance reasoning abilities without PRM integration, challenging the perceived necessity of process supervision. In this study, we conduct a systematic investigation of the relationship between RL training and PRM capabilities. Our findings demonstrate that problem-solving proficiency and process supervision capabilities represent complementary dimensions of reasoning that co-evolve synergistically during pure RL training. In particular, current PRMs underperform simple baselines like majority voting when applied to state-of-the-art models such as DeepSeek-R1 and QwQ-32B. To address this limitation, we propose Self-PRM, an introspective framework in which models autonomously evaluate and rerank their generated solutions through self-reward mechanisms. Although Self-PRM consistently improves the accuracy of the benchmark (particularly with larger sample sizes), analysis exposes persistent challenges: The approach exhibits low precision (<10\%) on difficult problems, frequently misclassifying flawed solutions as valid. These analyses underscore the need for continued RL scaling to improve reward alignment and introspective accuracy. Overall, our findings suggest that PRM may not be essential for enhancing complex reasoning, as pure RL not only improves problem-solving skills but also inherently fosters robust PRM capabilities. We hope these findings provide actionable insights for building more reliable and self-aware complex reasoning models.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Mixture of Lookup Experts
Mar 20, 2025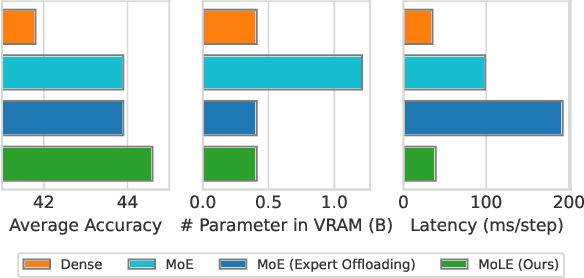

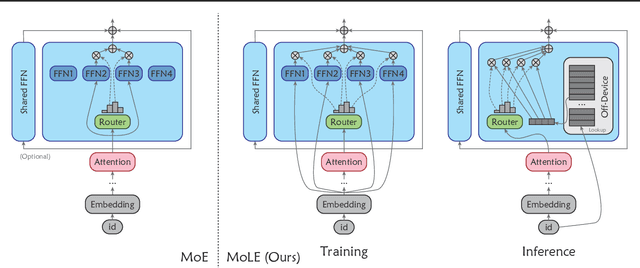
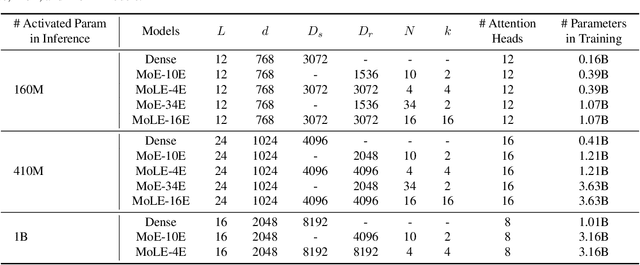
Mixture-of-Experts (MoE) activates only a subset of experts during inference, allowing the model to maintain low inference FLOPs and latency even as the parameter count scales up. However, since MoE dynamically selects the experts, all the experts need to be loaded into VRAM. Their large parameter size still limits deployment, and offloading, which load experts into VRAM only when needed, significantly increase inference latency. To address this, we propose Mixture of Lookup Experts (MoLE), a new MoE architecture that is efficient in both communication and VRAM usage. In MoLE, the experts are Feed-Forward Networks (FFNs) during training, taking the output of the embedding layer as input. Before inference, these experts can be re-parameterized as lookup tables (LUTs) that retrieves expert outputs based on input ids, and offloaded to storage devices. Therefore, we do not need to perform expert computations during inference. Instead, we directly retrieve the expert's computation results based on input ids and load them into VRAM, and thus the resulting communication overhead is negligible. Experiments show that, with the same FLOPs and VRAM usage, MoLE achieves inference speeds comparable to dense models and significantly faster than MoE with experts offloading, while maintaining performance on par with MoE.
Enhancing Non-English Capabilities of English-Centric Large Language Models through Deep Supervision Fine-Tuning
Mar 05, 2025Large language models (LLMs) have demonstrated significant progress in multilingual language understanding and generation. However, due to the imbalance in training data, their capabilities in non-English languages are limited. Recent studies revealed the English-pivot multilingual mechanism of LLMs, where LLMs implicitly convert non-English queries into English ones at the bottom layers and adopt English for thinking at the middle layers. However, due to the absence of explicit supervision for cross-lingual alignment in the intermediate layers of LLMs, the internal representations during these stages may become inaccurate. In this work, we introduce a deep supervision fine-tuning method (DFT) that incorporates additional supervision in the internal layers of the model to guide its workflow. Specifically, we introduce two training objectives on different layers of LLMs: one at the bottom layers to constrain the conversion of the target language into English, and another at the middle layers to constrain reasoning in English. To effectively achieve the guiding purpose, we designed two types of supervision signals: logits and feature, which represent a stricter constraint and a relatively more relaxed guidance. Our method guides the model to not only consider the final generated result when processing non-English inputs but also ensure the accuracy of internal representations. We conducted extensive experiments on typical English-centric large models, LLaMA-2 and Gemma-2, and the results on multiple multilingual datasets show that our method significantly outperforms traditional fine-tuning methods.
Unshackling Context Length: An Efficient Selective Attention Approach through Query-Key Compression
Feb 20, 2025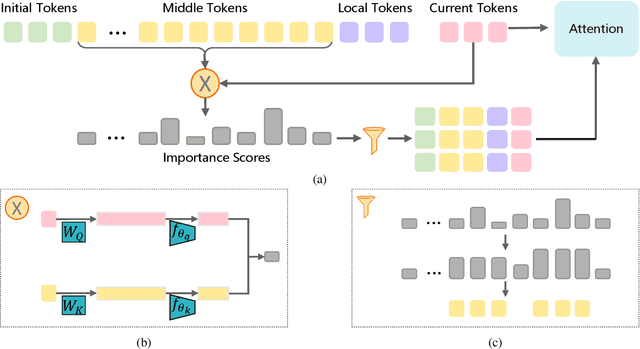
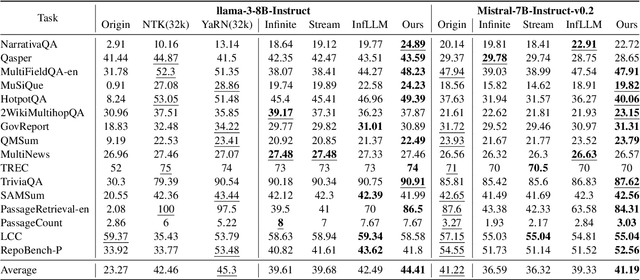
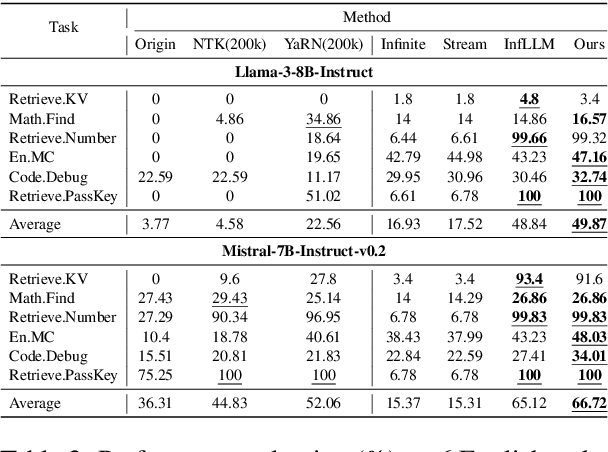
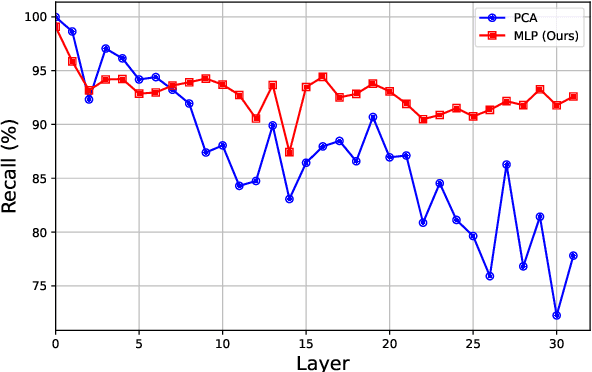
Handling long-context sequences efficiently remains a significant challenge in large language models (LLMs). Existing methods for token selection in sequence extrapolation either employ a permanent eviction strategy or select tokens by chunk, which may lead to the loss of critical information. We propose Efficient Selective Attention (ESA), a novel approach that extends context length by efficiently selecting the most critical tokens at the token level to compute attention. ESA reduces the computational complexity of token selection by compressing query and key vectors into lower-dimensional representations. We evaluate ESA on long sequence benchmarks with maximum lengths up to 256k using open-source LLMs with context lengths of 8k and 32k. ESA outperforms other selective attention methods, especially in tasks requiring the retrieval of multiple pieces of information, achieving comparable performance to full-attention extrapolation methods across various tasks, with superior results in certain tasks.