 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Non-English Capabilities of English-Centric Large Language Models through Deep Supervision Fine-Tuning
Mar 05, 2025Large language models (LLMs) have demonstrated significant progress in multilingual language understanding and generation. However, due to the imbalance in training data, their capabilities in non-English languages are limited. Recent studies revealed the English-pivot multilingual mechanism of LLMs, where LLMs implicitly convert non-English queries into English ones at the bottom layers and adopt English for thinking at the middle layers. However, due to the absence of explicit supervision for cross-lingual alignment in the intermediate layers of LLMs, the internal representations during these stages may become inaccurate. In this work, we introduce a deep supervision fine-tuning method (DFT) that incorporates additional supervision in the internal layers of the model to guide its workflow. Specifically, we introduce two training objectives on different layers of LLMs: one at the bottom layers to constrain the conversion of the target language into English, and another at the middle layers to constrain reasoning in English. To effectively achieve the guiding purpose, we designed two types of supervision signals: logits and feature, which represent a stricter constraint and a relatively more relaxed guidance. Our method guides the model to not only consider the final generated result when processing non-English inputs but also ensure the accuracy of internal representations. We conducted extensive experiments on typical English-centric large models, LLaMA-2 and Gemma-2, and the results on multiple multilingual datasets show that our method significantly outperforms traditional fine-tuning methods.
Ensuring Consistency for In-Image Translation
Dec 24, 2024The in-image machine translation task involves translating text embedded within images, with the translated results presented in image format. While this task has numerous applications in various scenarios such as film poster translation and everyday scene image translation, existing methods frequently neglect the aspect of consistency throughout this process. We propose the need to uphold two types of consistency in this task: translation consistency and image generation consistency. The former entails incorporating image information during translation, while the latter involves maintaining consistency between the style of the text-image and the original image, ensuring background integrity. To address these consistency requirements, we introduce a novel two-stage framework named HCIIT (High-Consistency In-Image Translation) which involves text-image translation using a multimodal multilingual large language model in the first stage and image backfilling with a diffusion model in the second stage. Chain of thought learning is utilized in the first stage to enhance the model's ability to leverage image information during translation. Subsequently, a diffusion model trained for style-consistent text-image generation ensures uniformity in text style within images and preserves background details. A dataset comprising 400,000 style-consistent pseudo text-image pairs is curated for model training. Results obtained on both curated test sets and authentic image test sets validate the effectiveness of our framework in ensuring consistency and producing high-quality translated images.
Relay Decoding: Concatenating Large Language Models for Machine Translation
May 05, 2024Leveraging large language models for machine translation has demonstrated promising results. However, it does require the large language models to possess the capability of handling both the source and target languages in machine translation. When it is challenging to find large models that support the desired languages, resorting to continuous learning methods becomes a costly endeavor. To mitigate these expenses, we propose an innovative approach called RD (Relay Decoding), which entails concatenating two distinct large models that individually support the source and target languages. By incorporating a simple mapping layer to facilitate the connection between these two models and utilizing a limited amount of parallel data for training, we successfully achieve superior results in the machine translation task. Experimental results conducted on the Multi30k and WikiMatrix datasets validate the effectiveness of our proposed method.
Enabling Ensemble Learning for Heterogeneous Large Language Models with Deep Parallel Collaboration
Apr 19, 2024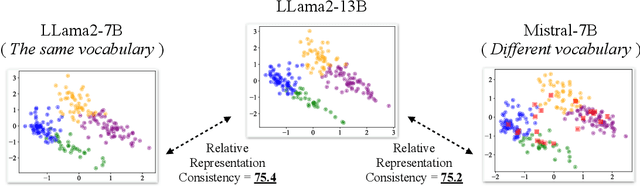
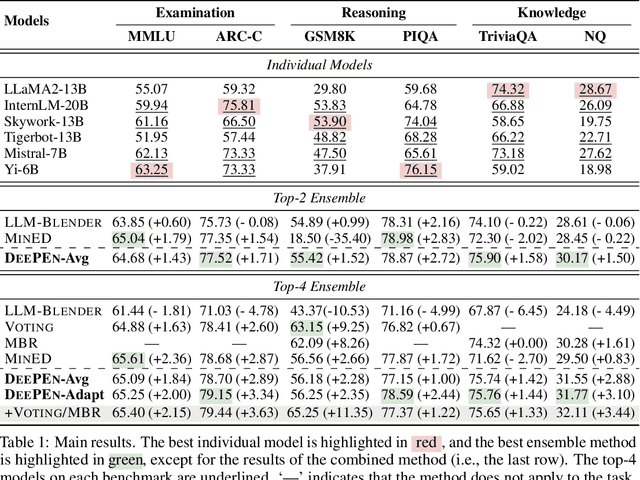
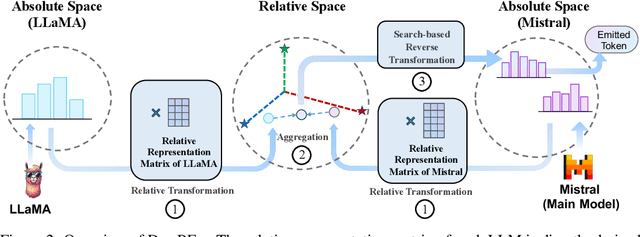

Large language models (LLMs) have shown complementary strengths in various tasks and instances, motivating the research of ensembling LLMs to push the frontier leveraging the wisdom of the crowd. Existing work achieves this objective via training the extra reward model or fusion model to select or fuse all candidate answers. However, these methods pose a great challenge to the generalizability of the trained models. Besides, existing methods use the textual responses as communication media, ignoring the rich information in the inner representations of neural networks. Therefore, we propose a training-free ensemble framework DEEPEN, averaging the probability distributions outputted by different LLMs. A key challenge in this paradigm is the vocabulary discrepancy between heterogeneous LLMs, which hinders the operation of probability distribution averaging. To address this challenge, DEEPEN maps the probability distribution of each model from the probability space to a universe relative space based on the relative representation theory, and performs aggregation. Then, the result of aggregation is mapped back to the probability space of one LLM via a search-based inverse transformation to determine the generated token. We conduct experiments on the ensemble of various LLMs of 6B to 70B. Experimental results show that DEEPEN achieves consistent improvements across six popular benchmarks involving subject examination, reasoning and knowledge-QA, proving the effectiveness of our approach.
Aligning Translation-Specific Understanding to General Understanding in Large Language Models
Jan 10, 2024



Although large language models (LLMs) have shown surprising language understanding and generation capabilities, they have yet to gain a revolutionary advancement in the field of machine translation. One potential cause of the limited performance is the misalignment between the translation-specific understanding and general understanding inside LLMs. To align the translation-specific understanding to the general one, we propose a novel translation process xIoD (Cross-Lingual Interpretation of Difficult words), explicitly incorporating the general understanding on the content incurring inconsistent understanding to guide the translation. Specifically, xIoD performs the cross-lingual interpretation for the difficult-to-translate words and enhances the translation with the generated interpretations. Furthermore, we reframe the external tools of QE to tackle the challenges of xIoD in the detection of difficult words and the generation of helpful interpretations. We conduct experiments on the self-constructed benchmark ChallengeMT, which includes cases in which multiple SOTA translation systems consistently underperform. Experimental results show the effectiveness of our xIoD, which improves up to +3.85 COMET.
Towards Higher Pareto Frontier in Multilingual Machine Translation
May 25, 2023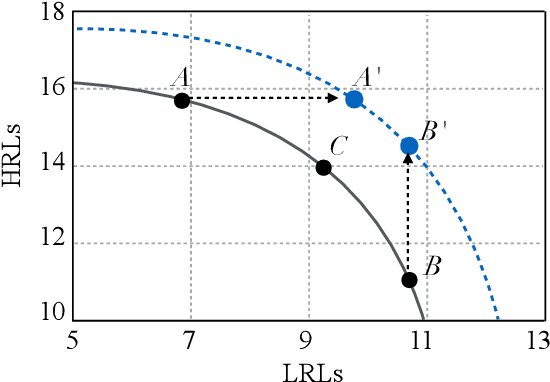
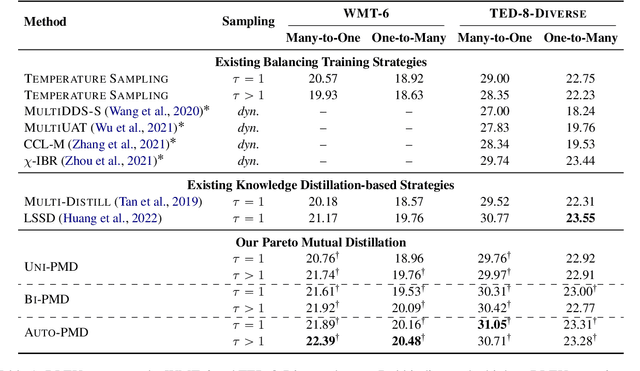
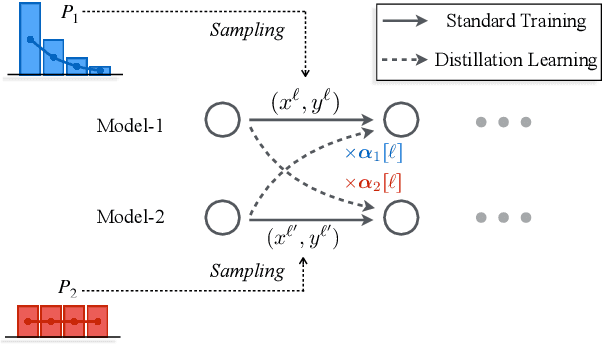

Multilingual neural machine translation has witnessed remarkable progress in recent years. However, the long-tailed distribution of multilingual corpora poses a challenge of Pareto optimization, i.e., optimizing for some languages may come at the cost of degrading the performance of others. Existing balancing training strategies are equivalent to a series of Pareto optimal solutions, which trade off on a Pareto frontier. In this work, we propose a new training framework, Pareto Mutual Distillation (Pareto-MD), towards pushing the Pareto frontier outwards rather than making trade-offs. Specifically, Pareto-MD collaboratively trains two Pareto optimal solutions that favor different languages and allows them to learn from the strengths of each other via knowledge distillation. Furthermore, we introduce a novel strategy to enable stronger communication between Pareto optimal solutions and broaden the applicability of our approach. Experimental results on the widely-used WMT and TED datasets show that our method significantly pushes the Pareto frontier and outperforms baselines by up to +2.46 BLEU.