 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicAgent: Towards Generalized Agent Planning
Feb 22, 2026The evolution of Large Language Models (LLMs) from passive text processors to autonomous agents has established planning as a core component of modern intelligence. However, achieving generalized planning remains elusive, not only by the scarcity of high-quality interaction data but also by inherent conflicts across heterogeneous planning tasks. These challenges result in models that excel at isolated tasks yet struggle to generalize, while existing multi-task training attempts suffer from gradient interference. In this paper, we present \textbf{MagicAgent}, a series of foundation models specifically designed for generalized agent planning. We introduce a lightweight and scalable synthetic data framework that generates high-quality trajectories across diverse planning tasks, including hierarchical task decomposition, tool-augmented planning, multi-constraint scheduling, procedural logic orchestration, and long-horizon tool execution. To mitigate training conflicts, we propose a two-stage training paradigm comprising supervised fine-tuning followed by multi-objective reinforcement learning over both static datasets and dynamic environments. Empirical results demonstrate that MagicAgent-32B and MagicAgent-30B-A3B deliver superior performance, achieving accuracies of $75.1\%$ on Worfbench, $55.9\%$ on NaturalPlan, $57.5\%$ on $τ^2$-Bench, $86.9\%$ on BFCL-v3, and $81.2\%$ on ACEBench, as well as strong results on our in-house MagicEval benchmarks. These results substantially outperform existing sub-100B models and even surpass leading closed-source models.
Towards Higher Pareto Frontier in Multilingual Machine Translation
May 25, 2023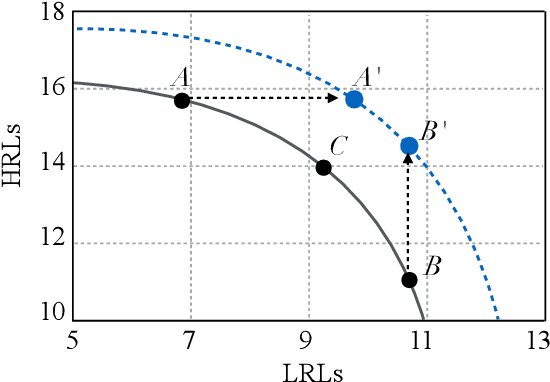
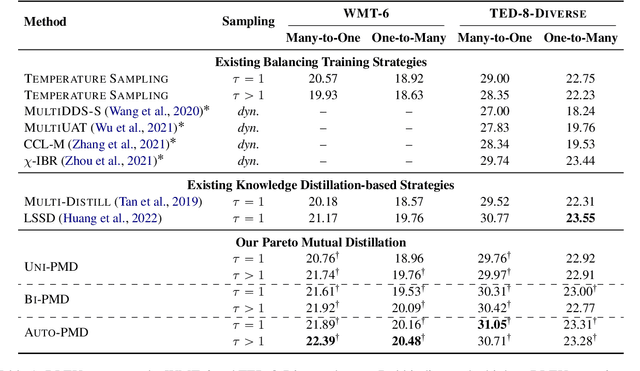
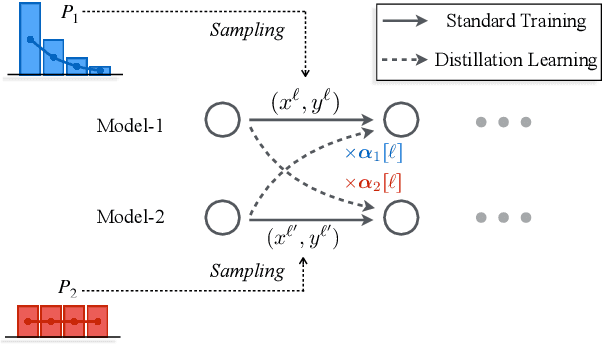

Multilingual neural machine translation has witnessed remarkable progress in recent years. However, the long-tailed distribution of multilingual corpora poses a challenge of Pareto optimization, i.e., optimizing for some languages may come at the cost of degrading the performance of others. Existing balancing training strategies are equivalent to a series of Pareto optimal solutions, which trade off on a Pareto frontier. In this work, we propose a new training framework, Pareto Mutual Distillation (Pareto-MD), towards pushing the Pareto frontier outwards rather than making trade-offs. Specifically, Pareto-MD collaboratively trains two Pareto optimal solutions that favor different languages and allows them to learn from the strengths of each other via knowledge distillation. Furthermore, we introduce a novel strategy to enable stronger communication between Pareto optimal solutions and broaden the applicability of our approach. Experimental results on the widely-used WMT and TED datasets show that our method significantly pushes the Pareto frontier and outperforms baselines by up to +2.46 BLEU.
OmniKnight: Multilingual Neural Machine Translation with Language-Specific Self-Distillation
May 03, 2022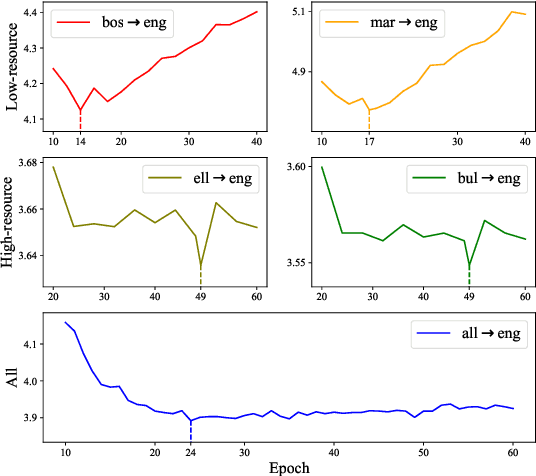
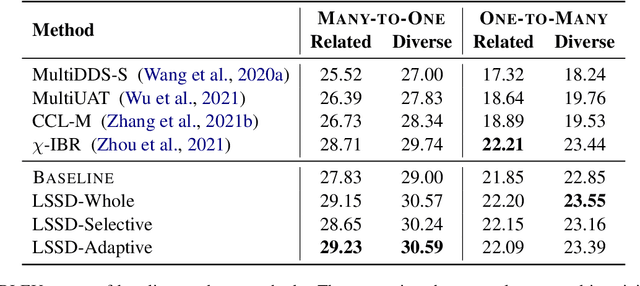
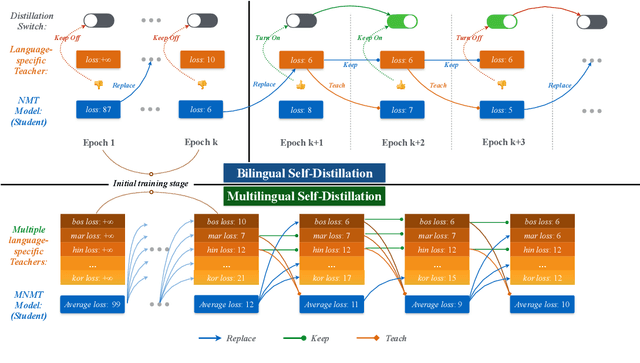
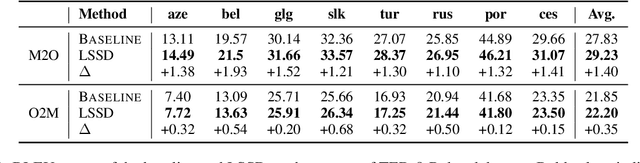
Although all-in-one-model multilingual neural machine translation (MNMT) has achieved remarkable progress in recent years, its selected best overall checkpoint fails to achieve the best performance simultaneously in all language pairs. It is because that the best checkpoints for each individual language pair (i.e., language-specific best checkpoints) scatter in different epochs. In this paper, we present a novel training strategy dubbed Language-Specific Self-Distillation (LSSD) for bridging the gap between language-specific best checkpoints and the overall best checkpoint. In detail, we regard each language-specific best checkpoint as a teacher to distill the overall best checkpoint. Moreover, we systematically explore three variants of our LSSD, which perform distillation statically, selectively, and adaptively. Experimental results on two widely-used benchmarks show that LSSD obtains consistent improvements towards all language pairs and achieves the state-of-the-art
Dialogue Discourse-Aware Graph Convolutional Networks for Abstractive Meeting Summarization
Dec 07, 2020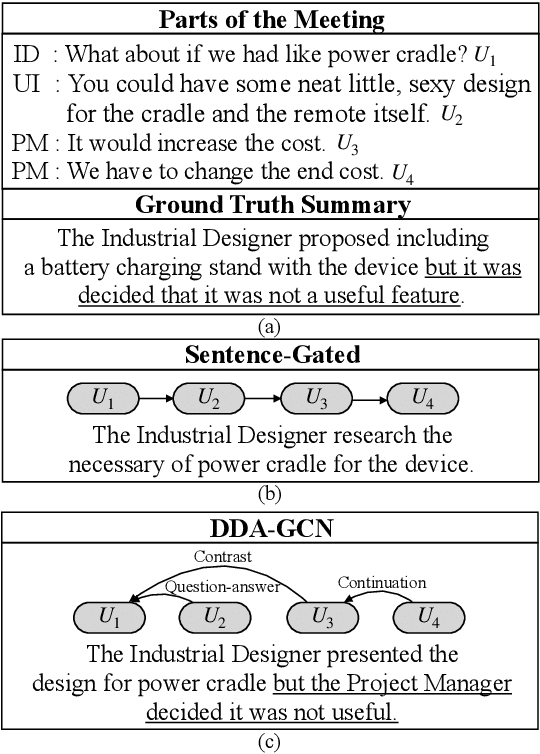
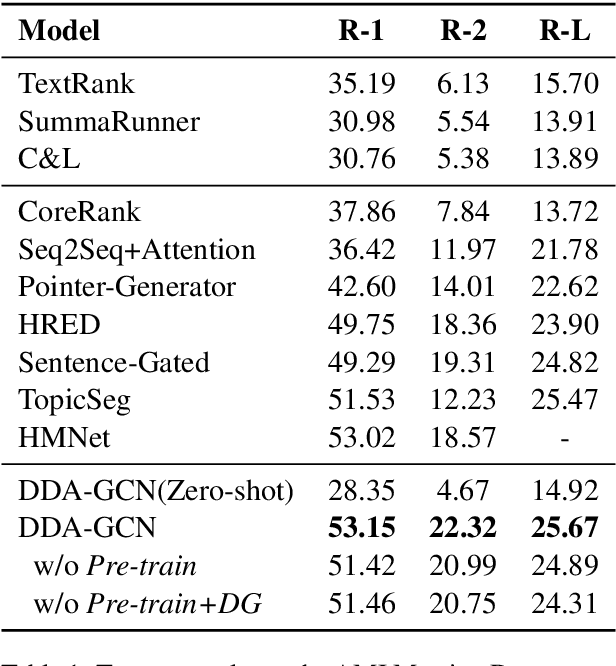
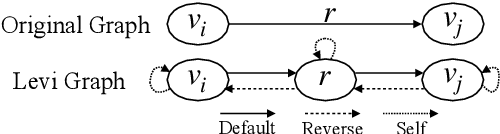
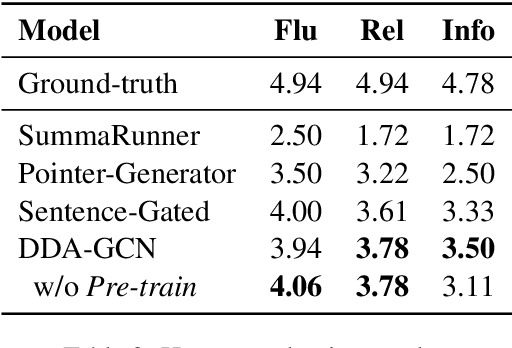
Sequence-to-sequence methods have achieved promising results for textual abstractive meeting summarization. Different from documents like news and scientific papers, a meeting is naturally full of dialogue-specific structural information. However, previous works model a meeting in a sequential manner, while ignoring the rich structural information. In this paper, we develop a Dialogue Discourse-Aware Graph Convolutional Networks (DDA-GCN) for meeting summarization by utilizing dialogue discourse, which is a dialogue-specific structure that can provide pre-defined semantic relationships between each utterance. We first transform the entire meeting text with dialogue discourse relations into a discourse graph and then use DDA-GCN to encode the semantic representation of the graph. Finally, we employ a Recurrent Neural Network to generate the summary. In addition, we utilize the question-answer discourse relation to construct a pseudo-summarization corpus, which can be used to pre-train our model. Experimental results on the AMI dataset show that our model outperforms various baselines and can achieve state-of-the-art performance.
How Does Selective Mechanism Improve Self-Attention Networks?
May 03, 2020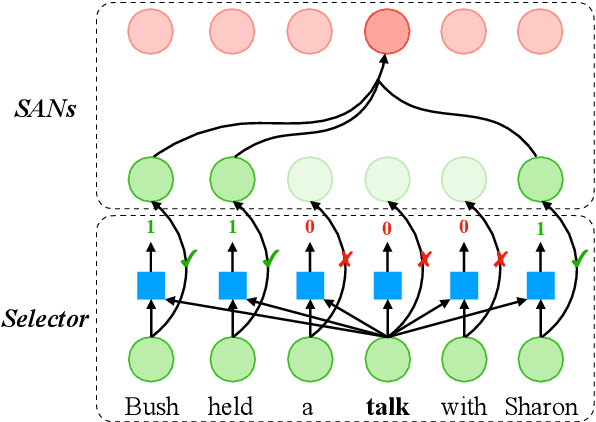
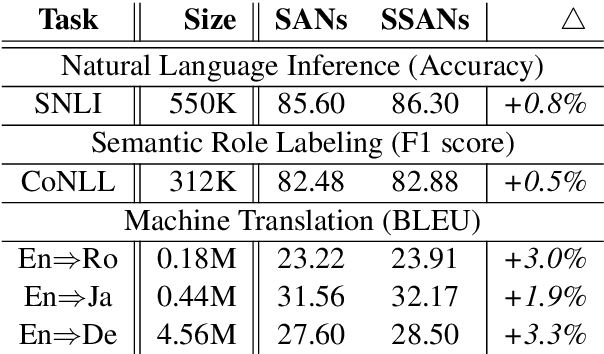
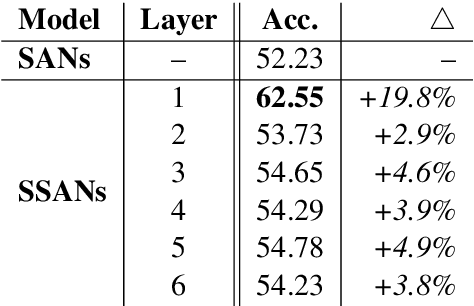
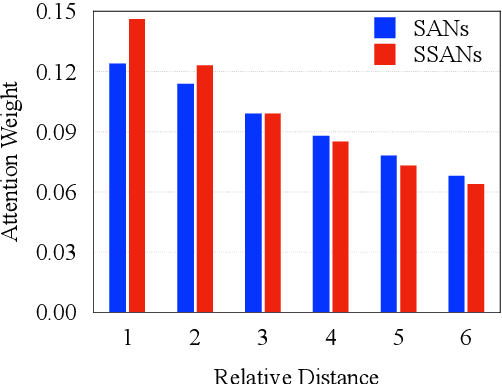
Self-attention networks (SANs) with selective mechanism has produced substantial improvements in various NLP tasks by concentrating on a subset of input words. However, the underlying reasons for their strong performance have not been well explained. In this paper, we bridge the gap by assessing the strengths of selective SANs (SSANs), which are implemented with a flexible and universal Gumbel-Softmax. Experimental results on several representative NLP tasks, including natural language inference, semantic role labelling, and machine translation, show that SSANs consistently outperform the standard SANs. Through well-designed probing experiments, we empirically validate that the improvement of SSANs can be attributed in part to mitigating two commonly-cited weaknesses of SANs: word order encoding and structure modeling. Specifically, the selective mechanism improves SANs by paying more attention to content words that contribute to the meaning of the sentence. The code and data are released at https://github.com/xwgeng/SSAN.
Learning to Refine Source Representations for Neural Machine Translation
Dec 26, 2018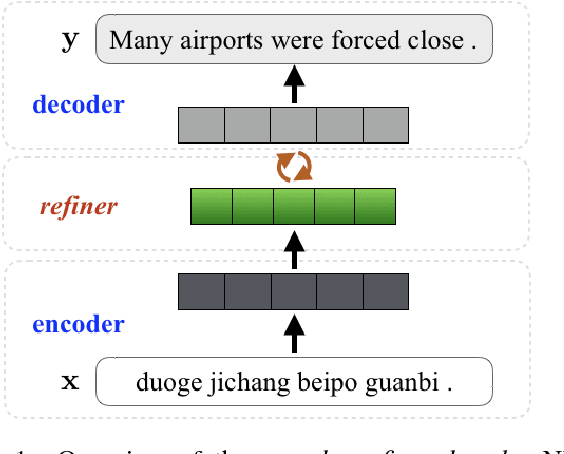
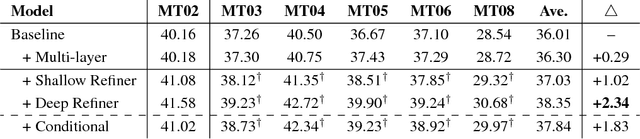
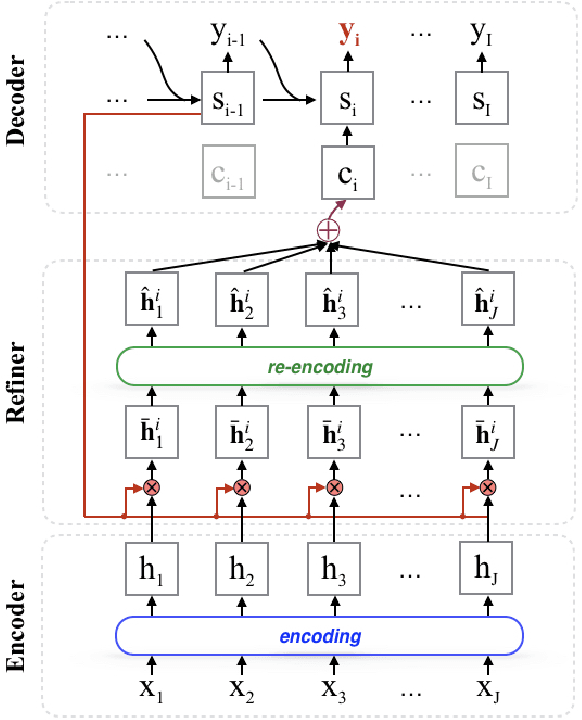
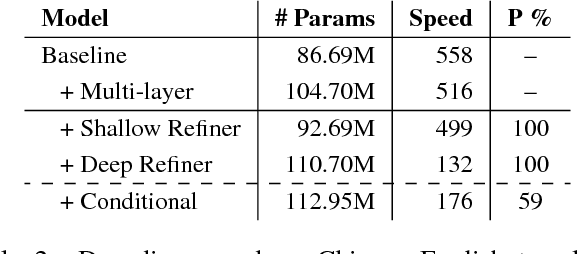
Neural machine translation (NMT) models generally adopt an encoder-decoder architecture for modeling the entire translation process. The encoder summarizes the representation of input sentence from scratch, which is potentially a problem if the sentence is ambiguous. When translating a text, humans often create an initial understanding of the source sentence and then incrementally refine it along the translation on the target side. Starting from this intuition, we propose a novel encoder-refiner-decoder framework, which dynamically refines the source representations based on the generated target-side information at each decoding step. Since the refining operations are time-consuming, we propose a strategy, leveraging the power of reinforcement learning models, to decide when to refine at specific decoding steps. Experimental results on both Chinese-English and English-German translation tasks show that the proposed approach significantly and consistently improves translation performance over the standard encoder-decoder framework. Furthermore, when refining strategy is applied, results still show reasonable improvement over the baseline without much decrease in decoding speed.
A Planning based Framework for Essay Generation
Jan 06, 2016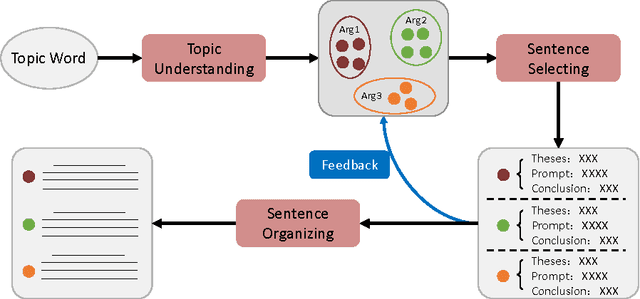
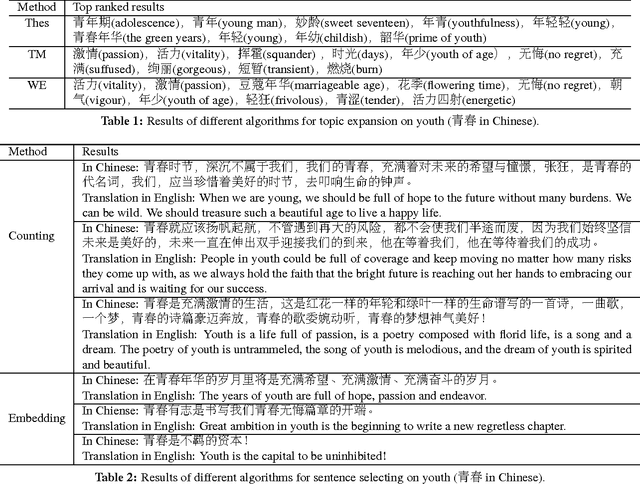
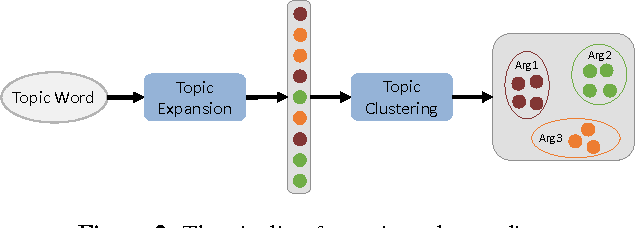
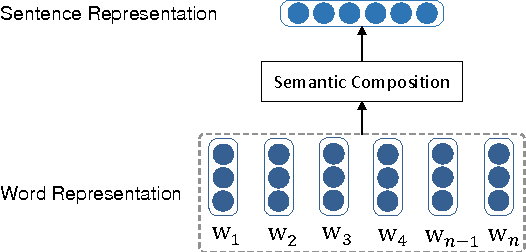
Generating an article automatically with computer program is a challenging task in artificial intelligence and natural language processing. In this paper, we target at essay generation, which takes as input a topic word in mind and generates an organized article under the theme of the topic. We follow the idea of text planning \cite{Reiter1997} and develop an essay generation framework. The framework consists of three components, including topic understanding, sentence extraction and sentence reordering. For each component, we studied several statistical algorithms and empirically compared between them in terms of qualitative or quantitative analysis. Although we run experiments on Chinese corpus, the method is language independent and can be easily adapted to other language. We lay out the remaining challenges and suggest avenues for future research.