 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Aware Caching for Efficient Autoregressive Video Generation
May 03, 2026Autoregressive video generation paradigms offer theoretical promise for long video synthesis, yet their practical deployment is hindered by the computational burden of sequential iterative denoising. While cache reuse strategies can accelerate generation by skipping redundant denoising steps, existing methods rely on coarse-grained chunk-level skipping that fails to capture fine-grained pixel dynamics. This oversight is critical: pixels with high motion require more denoising steps to prevent error accumulation, while static pixels tolerate aggressive skipping. We formalize this insight theoretically by linking cache errors to residual instability, and propose MotionCache, a motion-aware cache framework that exploits inter-frame differences as a lightweight proxy for pixel-level motion characteristics. MotionCache employs a coarse-to-fine strategy: an initial warm-up phase establishes semantic coherence, followed by motion-weighted cache reuse that dynamically adjusts update frequencies per token. Extensive experiments on state-of-the-art models like SkyReels-V2 and MAGI-1 demonstrate that MotionCache achieves significant speedups of $\textbf{6.28}\times$ and $\textbf{1.64}\times$ respectively, while effectively preserving generation quality (VBench: $1\%\downarrow$ and $0.01\%\downarrow$ respectively). The code is available at https://github.com/ywlq/MotionCache.
Multi-output Extreme Spatial Model for Complex Aircraft Production Systems
Apr 24, 2026Problem definition: Data-driven models in machine learning have enabled efficient management of production systems. However, a majority of machine learning models are devoted to modeling the mean response or average pattern, which is inappropriate for studying abnormal extreme events that are often of primary interest in aircraft manufacturing. Since extreme events from heavy-tailed distributions give rise to prohibitive expenditures in system management, sophisticated extreme models are urgently needed to analyze complex extreme risks. Engineering applications of extreme models usually focus on individual extreme events, which is insufficient for complex systems with correlations. Methodology/results: We introduce an extreme spatial model for multi-output response control systems that efficiently captures the dynamics using a bilinear function on two spatial domains for control variables and measurement locations. Marginal parameter modeling and extremal dependence have been investigated. In addition, an efficient graph-assisted composite likelihood estimation and corresponding computational algorithms are developed to cope with high-dimensional outputs. The application to composite aircraft production shows that the proposed model enables comprehensive analyses with superior predictive performance on extreme events compared to canonical methods. Managerial implications: Our method shows how to use an extreme spatial model for predicting extreme events and managing extreme risks in complex production systems such as aircraft. This can help achieve better quality management and operation safety in aircraft production systems and beyond.
TAP: A Token-Adaptive Predictor Framework for Training-Free Diffusion Acceleration
Mar 04, 2026Diffusion models achieve strong generative performance but remain slow at inference due to the need for repeated full-model denoising passes. We present Token-Adaptive Predictor (TAP), a training-free, probe-driven framework that adaptively selects a predictor for each token at every sampling step. TAP uses a single full evaluation of the model's first layer as a low-cost probe to compute proxy losses for a compact family of candidate predictors (instantiated primarily with Taylor expansions of varying order and horizon), then assigns each token the predictor with the smallest proxy error. This per-token "probe-then-select" strategy exploits heterogeneous temporal dynamics, requires no additional training, and is compatible with various predictor designs. TAP incurs negligible overhead while enabling large speedups with little or no perceptual quality loss. Extensive experiments across multiple diffusion architectures and generation tasks show that TAP substantially improves the accuracy-efficiency frontier compared to fixed global predictors and caching-only baselines.
S2O: Early Stopping for Sparse Attention via Online Permutation
Feb 26, 2026Attention scales quadratically with sequence length, fundamentally limiting long-context inference. Existing block-granularity sparsification can reduce latency, but coarse blocks impose an intrinsic sparsity ceiling, making further improvements difficult even with carefully engineered designs. We present S2O, which performs early stopping for sparse attention via online permutation. Inspired by virtual-to-physical address mapping in memory systems, S2O revisits and factorizes FlashAttention execution, enabling inference to load non-contiguous tokens rather than a contiguous span in the original order. Motivated by fine-grained structures in attention heatmaps, we transform explicit permutation into an online, index-guided, discrete loading policy; with extremely lightweight preprocessing and index-remapping overhead, it concentrates importance on a small set of high-priority blocks. Building on this importance-guided online permutation for loading, S2O further introduces an early-stopping rule: computation proceeds from high to low importance; once the current block score falls below a threshold, S2O terminates early and skips the remaining low-contribution blocks, thereby increasing effective sparsity and reducing computation under a controlled error budget. As a result, S2O substantially raises the practical sparsity ceiling. On Llama-3.1-8B under a 128K context, S2O reduces single-operator MSE by 3.82$\times$ at matched sparsity, and reduces prefill compute density by 3.31$\times$ at matched MSE; meanwhile, it preserves end-to-end accuracy and achieves 7.51$\times$ attention and 3.81$\times$ end-to-end speedups.
Train Short, Inference Long: Training-free Horizon Extension for Autoregressive Video Generation
Feb 17, 2026Autoregressive video diffusion models have emerged as a scalable paradigm for long video generation. However, they often suffer from severe extrapolation failure, where rapid error accumulation leads to significant temporal degradation when extending beyond training horizons. We identify that this failure primarily stems from the spectral bias of 3D positional embeddings and the lack of dynamic priors in noise sampling. To address these issues, we propose FLEX (Frequency-aware Length EXtension), a training-free inference-time framework that bridges the gap between short-term training and long-term inference. FLEX introduces Frequency-aware RoPE Modulation to adaptively interpolate under-trained low-frequency components while extrapolating high-frequency ones to preserve multi-scale temporal discriminability. This is integrated with Antiphase Noise Sampling (ANS) to inject high-frequency dynamic priors and Inference-only Attention Sink to anchor global structure. Extensive evaluations on VBench demonstrate that FLEX significantly outperforms state-of-the-art models at 6x extrapolation (30s duration) and matches the performance of long-video fine-tuned baselines at 12x scale (60s duration). As a plug-and-play augmentation, FLEX seamlessly integrates into existing inference pipelines for horizon extension. It effectively pushes the generation limits of models such as LongLive, supporting consistent and dynamic video synthesis at a 4-minute scale. Project page is available at https://ga-lee.github.io/FLEX_demo.
Flow caching for autoregressive video generation
Feb 11, 2026Autoregressive models, often built on Transformer architectures, represent a powerful paradigm for generating ultra-long videos by synthesizing content in sequential chunks. However, this sequential generation process is notoriously slow. While caching strategies have proven effective for accelerating traditional video diffusion models, existing methods assume uniform denoising across all frames-an assumption that breaks down in autoregressive models where different video chunks exhibit varying similarity patterns at identical timesteps. In this paper, we present FlowCache, the first caching framework specifically designed for autoregressive video generation. Our key insight is that each video chunk should maintain independent caching policies, allowing fine-grained control over which chunks require recomputation at each timestep. We introduce a chunkwise caching strategy that dynamically adapts to the unique denoising characteristics of each chunk, complemented by a joint importance-redundancy optimized KV cache compression mechanism that maintains fixed memory bounds while preserving generation quality. Our method achieves remarkable speedups of 2.38 times on MAGI-1 and 6.7 times on SkyReels-V2, with negligible quality degradation (VBench: 0.87 increase and 0.79 decrease respectively). These results demonstrate that FlowCache successfully unlocks the potential of autoregressive models for real-time, ultra-long video generation-establishing a new benchmark for efficient video synthesis at scale. The code is available at https://github.com/mikeallen39/FlowCache.
FlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
High Dimensional Data Decomposition for Anomaly Detection of Textured Images
Dec 23, 2025In the realm of diverse high-dimensional data, images play a significant role across various processes of manufacturing systems where efficient image anomaly detection has emerged as a core technology of utmost importance. However, when applied to textured defect images, conventional anomaly detection methods have limitations including non-negligible misidentification, low robustness, and excessive reliance on large-scale and structured datasets. This paper proposes a texture basis integrated smooth decomposition (TBSD) approach, which is targeted at efficient anomaly detection in textured images with smooth backgrounds and sparse anomalies. Mathematical formulation of quasi-periodicity and its theoretical properties are investigated for image texture estimation. TBSD method consists of two principal processes: the first process learns the texture basis functions to effectively extract quasi-periodic texture patterns; the subsequent anomaly detection process utilizes that texture basis as prior knowledge to prevent texture misidentification and capture potential anomalies with high accuracy.The proposed method surpasses benchmarks with less misidentification, smaller training dataset requirement, and superior anomaly detection performance on both simulation and real-world datasets.
InfinityStar: Unified Spacetime AutoRegressive Modeling for Visual Generation
Nov 06, 2025We introduce InfinityStar, a unified spacetime autoregressive framework for high-resolution image and dynamic video synthesis. Building on the recent success of autoregressive modeling in both vision and language, our purely discrete approach jointly captures spatial and temporal dependencies within a single architecture. This unified design naturally supports a variety of generation tasks such as text-to-image, text-to-video, image-to-video, and long interactive video synthesis via straightforward temporal autoregression. Extensive experiments demonstrate that InfinityStar scores 83.74 on VBench, outperforming all autoregressive models by large margins, even surpassing some diffusion competitors like HunyuanVideo. Without extra optimizations, our model generates a 5s, 720p video approximately 10x faster than leading diffusion-based methods. To our knowledge, InfinityStar is the first discrete autoregressive video generator capable of producing industrial level 720p videos. We release all code and models to foster further research in efficient, high-quality video generation.
Adversarial Distribution Matching for Diffusion Distillation Towards Efficient Image and Video Synthesis
Jul 24, 2025
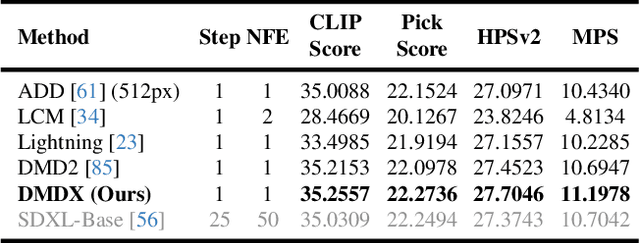
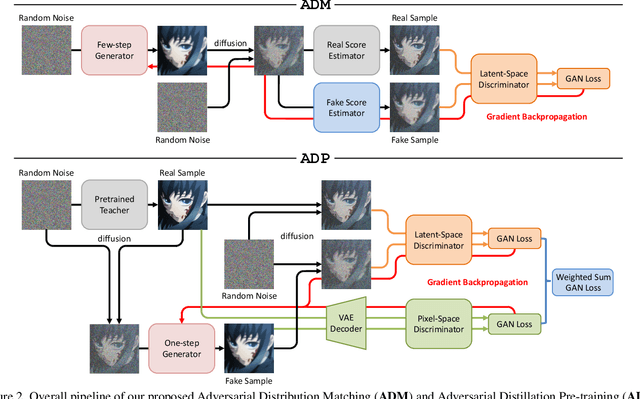
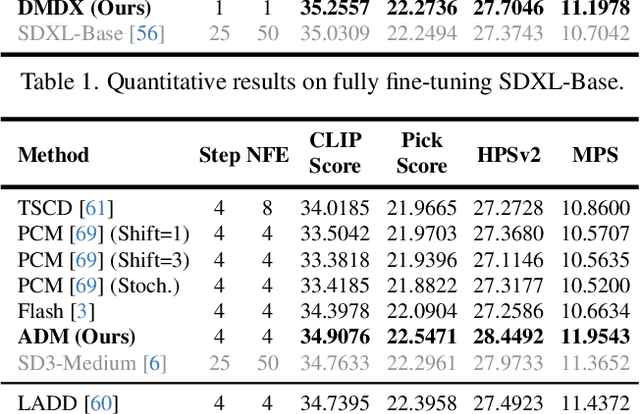
Distribution Matching Distillation (DMD) is a promising score distillation technique that compresses pre-trained teacher diffusion models into efficient one-step or multi-step student generators. Nevertheless, its reliance on the reverse Kullback-Leibler (KL) divergence minimization potentially induces mode collapse (or mode-seeking) in certain applications. To circumvent this inherent drawback, we propose Adversarial Distribution Matching (ADM), a novel framework that leverages diffusion-based discriminators to align the latent predictions between real and fake score estimators for score distillation in an adversarial manner. In the context of extremely challenging one-step distillation, we further improve the pre-trained generator by adversarial distillation with hybrid discriminators in both latent and pixel spaces. Different from the mean squared error used in DMD2 pre-training, our method incorporates the distributional loss on ODE pairs collected from the teacher model, and thus providing a better initialization for score distillation fine-tuning in the next stage. By combining the adversarial distillation pre-training with ADM fine-tuning into a unified pipeline termed DMDX, our proposed method achieves superior one-step performance on SDXL compared to DMD2 while consuming less GPU time. Additional experiments that apply multi-step ADM distillation on SD3-Medium, SD3.5-Large, and CogVideoX set a new benchmark towards efficient image and video synthesis.