 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinityStar: Unified Spacetime AutoRegressive Modeling for Visual Generation
Nov 06, 2025We introduce InfinityStar, a unified spacetime autoregressive framework for high-resolution image and dynamic video synthesis. Building on the recent success of autoregressive modeling in both vision and language, our purely discrete approach jointly captures spatial and temporal dependencies within a single architecture. This unified design naturally supports a variety of generation tasks such as text-to-image, text-to-video, image-to-video, and long interactive video synthesis via straightforward temporal autoregression. Extensive experiments demonstrate that InfinityStar scores 83.74 on VBench, outperforming all autoregressive models by large margins, even surpassing some diffusion competitors like HunyuanVideo. Without extra optimizations, our model generates a 5s, 720p video approximately 10x faster than leading diffusion-based methods. To our knowledge, InfinityStar is the first discrete autoregressive video generator capable of producing industrial level 720p videos. We release all code and models to foster further research in efficient, high-quality video generation.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
Towards Deviation-Robust Agent Navigation via Perturbation-Aware Contrastive Learning
Mar 09, 2024Vision-and-language navigation (VLN) asks an agent to follow a given language instruction to navigate through a real 3D environment. Despite significant advances, conventional VLN agents are trained typically under disturbance-free environments and may easily fail in real-world scenarios, since they are unaware of how to deal with various possible disturbances, such as sudden obstacles or human interruptions, which widely exist and may usually cause an unexpected route deviation. In this paper, we present a model-agnostic training paradigm, called Progressive Perturbation-aware Contrastive Learning (PROPER) to enhance the generalization ability of existing VLN agents, by requiring them to learn towards deviation-robust navigation. Specifically, a simple yet effective path perturbation scheme is introduced to implement the route deviation, with which the agent is required to still navigate successfully following the original instruction. Since directly enforcing the agent to learn perturbed trajectories may lead to inefficient training, a progressively perturbed trajectory augmentation strategy is designed, where the agent can self-adaptively learn to navigate under perturbation with the improvement of its navigation performance for each specific trajectory. For encouraging the agent to well capture the difference brought by perturbation, a perturbation-aware contrastive learning mechanism is further developed by contrasting perturbation-free trajectory encodings and perturbation-based counterparts. Extensive experiments on R2R show that PROPER can benefit multiple VLN baselines in perturbation-free scenarios. We further collect the perturbed path data to construct an introspection subset based on the R2R, called Path-Perturbed R2R (PP-R2R). The results on PP-R2R show unsatisfying robustness of popular VLN agents and the capability of PROPER in improving the navigation robustness.
* Accepted by TPAMI 2023
RM-PRT: Realistic Robotic Manipulation Simulator and Benchmark with Progressive Reasoning Tasks
Jun 21, 2023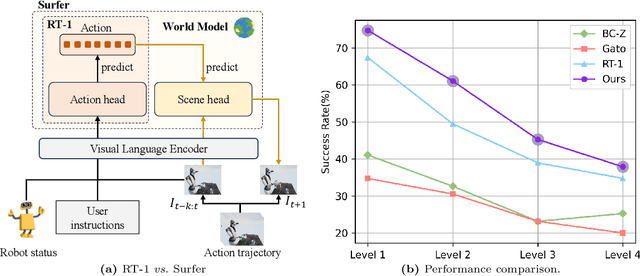

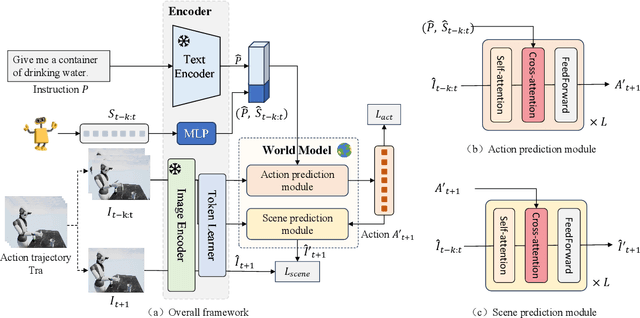
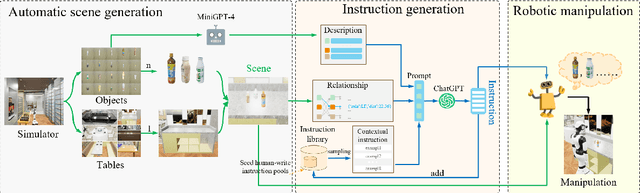
Recently, the advent of pre-trained large-scale language models (LLMs) like ChatGPT and GPT-4 have significantly advanced the machine's natural language understanding capabilities. This breakthrough has allowed us to seamlessly integrate these open-source LLMs into a unified robot simulator environment to help robots accurately understand and execute human natural language instructions. To this end, in this work, we introduce a realistic robotic manipulation simulator and build a Robotic Manipulation with Progressive Reasoning Tasks (RM-PRT) benchmark on this basis. Specifically, the RM-PRT benchmark builds a new high-fidelity digital twin scene based on Unreal Engine 5, which includes 782 categories, 2023 objects, and 15K natural language instructions generated by ChatGPT for a detailed evaluation of robot manipulation. We propose a general pipeline for the RM-PRT benchmark that takes as input multimodal prompts containing natural language instructions and automatically outputs actions containing the movement and position transitions. We set four natural language understanding tasks with progressive reasoning levels and evaluate the robot's ability to understand natural language instructions in two modes of adsorption and grasping. In addition, we also conduct a comprehensive analysis and comparison of the differences and advantages of 10 different LLMs in instruction understanding and generation quality. We hope the new simulator and benchmark will facilitate future research on language-guided robotic manipulation. Project website: https://necolizer.github.io/RM-PRT/ .
Visual-Language Navigation Pretraining via Prompt-based Environmental Self-exploration
Mar 08, 2022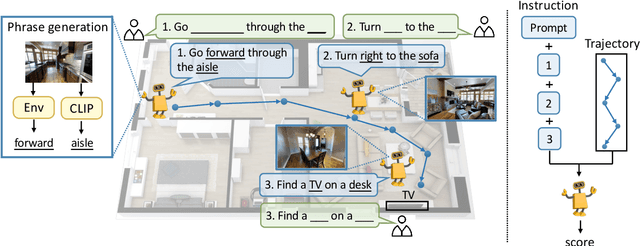

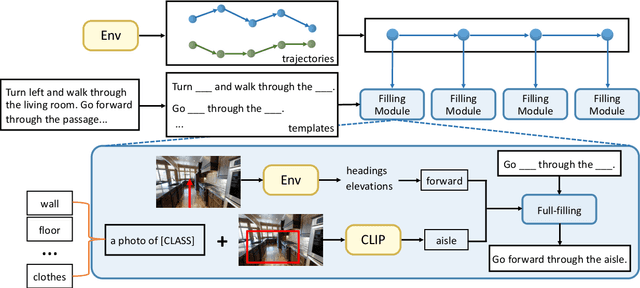
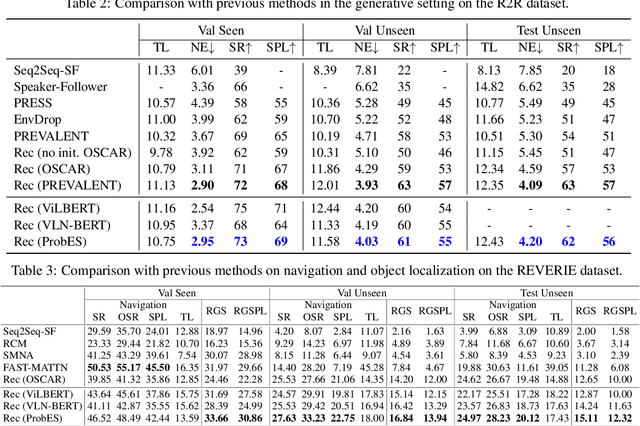
Vision-language navigation (VLN) is a challenging task due to its large searching space in the environment. To address this problem, previous works have proposed some methods of fine-tuning a large model that pretrained on large-scale datasets. However, the conventional fine-tuning methods require extra human-labeled navigation data and lack self-exploration capabilities in environments, which hinders their generalization of unseen scenes. To improve the ability of fast cross-domain adaptation, we propose Prompt-based Environmental Self-exploration (ProbES), which can self-explore the environments by sampling trajectories and automatically generates structured instructions via a large-scale cross-modal pretrained model (CLIP). Our method fully utilizes the knowledge learned from CLIP to build an in-domain dataset by self-exploration without human labeling. Unlike the conventional approach of fine-tuning, we introduce prompt-based learning to achieve fast adaptation for language embeddings, which substantially improves the learning efficiency by leveraging prior knowledge. By automatically synthesizing trajectory-instruction pairs in any environment without human supervision and efficient prompt-based learning, our model can adapt to diverse vision-language navigation tasks, including VLN and REVERIE. Both qualitative and quantitative results show that our ProbES significantly improves the generalization ability of the navigation model.
Contrastive Instruction-Trajectory Learning for Vision-Language Navigation
Dec 09, 2021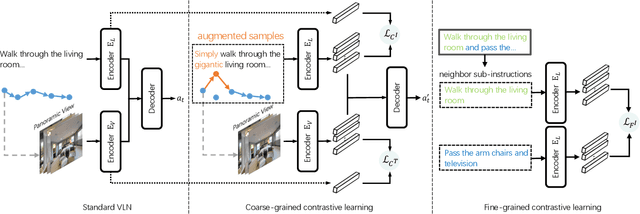
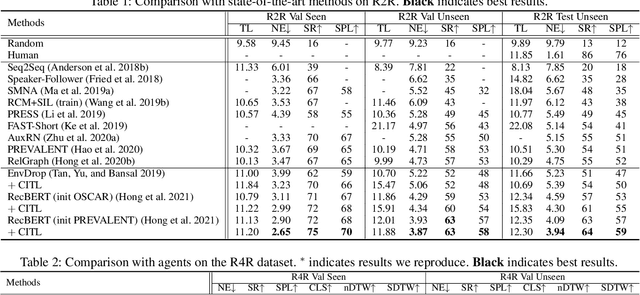
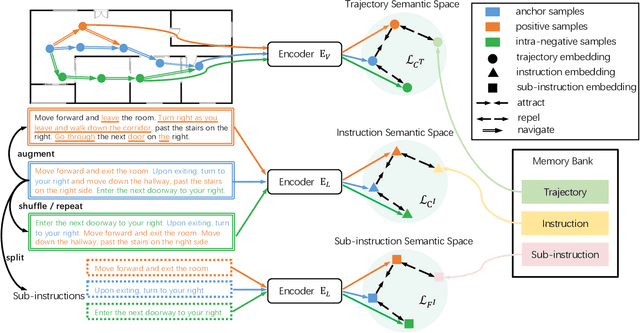
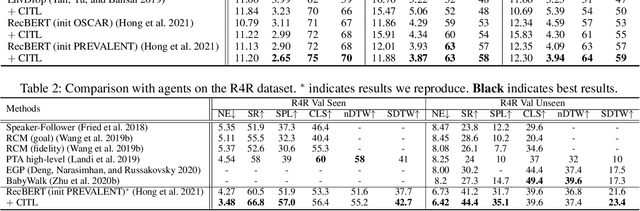
The vision-language navigation (VLN) task requires an agent to reach a target with the guidance of natural language instruction. Previous works learn to navigate step-by-step following an instruction. However, these works may fail to discriminate the similarities and discrepancies across instruction-trajectory pairs and ignore the temporal continuity of sub-instructions. These problems hinder agents from learning distinctive vision-and-language representations, harming the robustness and generalizability of the navigation policy. In this paper, we propose a Contrastive Instruction-Trajectory Learning (CITL) framework that explores invariance across similar data samples and variance across different ones to learn distinctive representations for robust navigation. Specifically, we propose: (1) a coarse-grained contrastive learning objective to enhance vision-and-language representations by contrasting semantics of full trajectory observations and instructions, respectively; (2) a fine-grained contrastive learning objective to perceive instructions by leveraging the temporal information of the sub-instructions; (3) a pairwise sample-reweighting mechanism for contrastive learning to mine hard samples and hence mitigate the influence of data sampling bias in contrastive learning. Our CITL can be easily integrated with VLN backbones to form a new learning paradigm and achieve better generalizability in unseen environments. Extensive experiments show that the model with CITL surpasses the previous state-of-the-art methods on R2R, R4R, and RxR.
Deep Learning for Embodied Vision Navigation: A Survey
Jul 07, 2021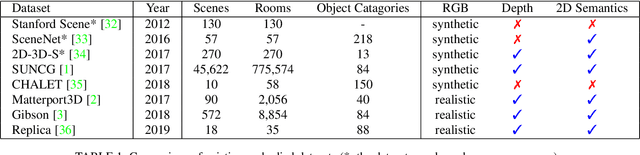

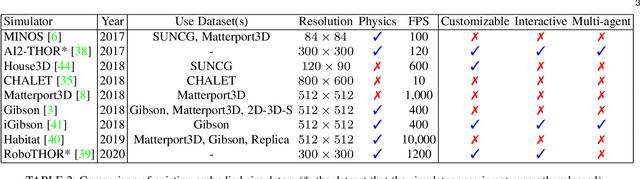
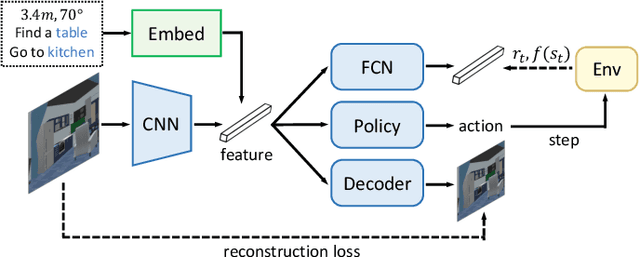
Navigation is one of the fundamental features of a autonomous robot. And the ability of long-term navigation with semantic instruction is a `holy grail` goals of intelligent robots. The development of 3D simulation technology provide a large scale of data to simulate the real-world environment. The deep learning proves its ability to robustly learn various embodied navigation tasks. However, deep learning on embodied navigation is still in its infancy due to the unique challenges faced by the navigation exploration and learning from partial observed visual input. Recently, deep learning in embodied navigation has become even thriving, with numerous methods have been proposed to tackle different challenges in this area. To give a promising direction for future research, in this paper, we present a comprehensive review of embodied navigation tasks and the recent progress in deep learning based methods. It includes two major tasks: target-oriented navigation and the instruction-oriented navigation.
Vision-Language Navigation with Random Environmental Mixup
Jun 15, 2021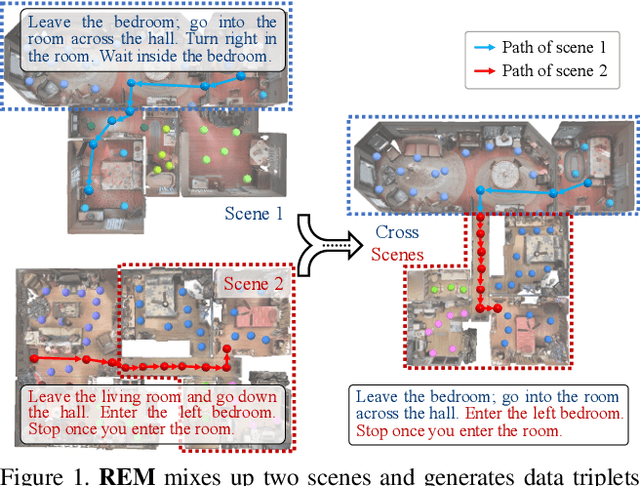
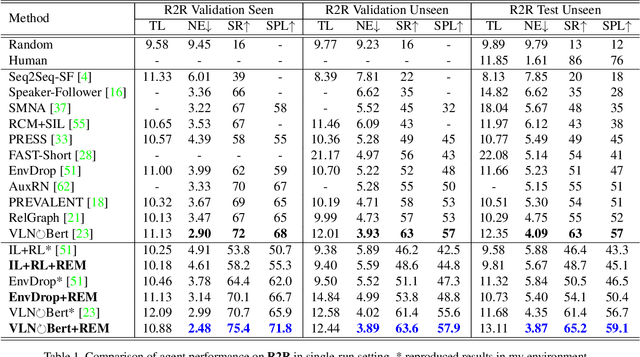
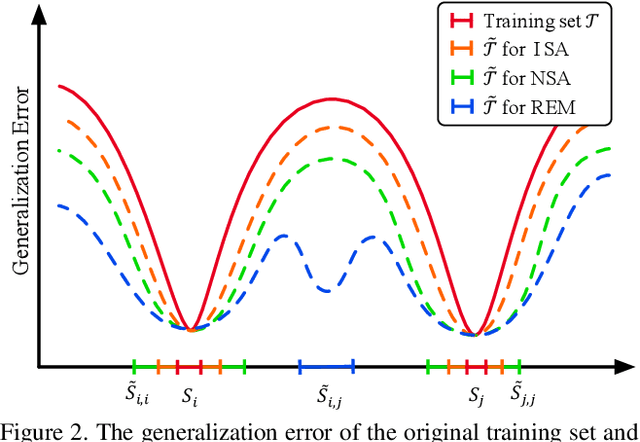
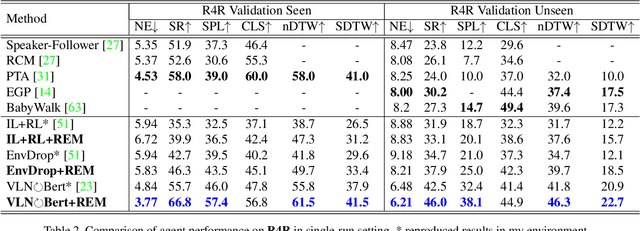
Vision-language Navigation (VLN) tasks require an agent to navigate step-by-step while perceiving the visual observations and comprehending a natural language instruction. Large data bias, which is caused by the disparity ratio between the small data scale and large navigation space, makes the VLN task challenging. Previous works have proposed various data augmentation methods to reduce data bias. However, these works do not explicitly reduce the data bias across different house scenes. Therefore, the agent would overfit to the seen scenes and achieve poor navigation performance in the unseen scenes. To tackle this problem, we propose the Random Environmental Mixup (REM) method, which generates cross-connected house scenes as augmented data via mixuping environment. Specifically, we first select key viewpoints according to the room connection graph for each scene. Then, we cross-connect the key views of different scenes to construct augmented scenes. Finally, we generate augmented instruction-path pairs in the cross-connected scenes. The experimental results on benchmark datasets demonstrate that our augmentation data via REM help the agent reduce its performance gap between the seen and unseen environment and improve the overall performance, making our model the best existing approach on the standard VLN benchmark.
SOON: Scenario Oriented Object Navigation with Graph-based Exploration
Mar 31, 2021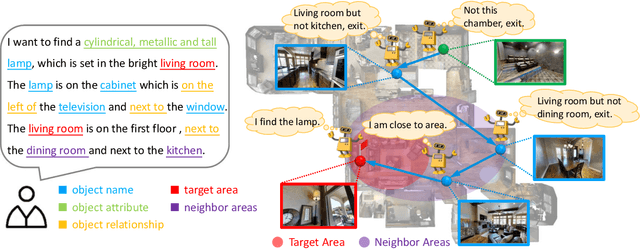
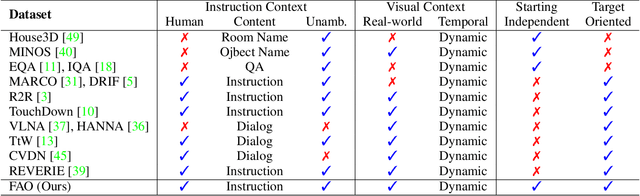
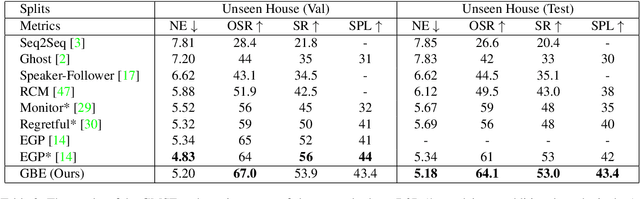
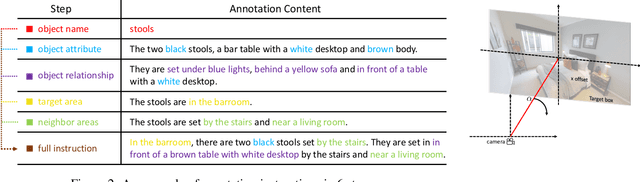
The ability to navigate like a human towards a language-guided target from anywhere in a 3D embodied environment is one of the 'holy grail' goals of intelligent robots. Most visual navigation benchmarks, however, focus on navigating toward a target from a fixed starting point, guided by an elaborate set of instructions that depicts step-by-step. This approach deviates from real-world problems in which human-only describes what the object and its surrounding look like and asks the robot to start navigation from anywhere. Accordingly, in this paper, we introduce a Scenario Oriented Object Navigation (SOON) task. In this task, an agent is required to navigate from an arbitrary position in a 3D embodied environment to localize a target following a scene description. To give a promising direction to solve this task, we propose a novel graph-based exploration (GBE) method, which models the navigation state as a graph and introduces a novel graph-based exploration approach to learn knowledge from the graph and stabilize training by learning sub-optimal trajectories. We also propose a new large-scale benchmark named From Anywhere to Object (FAO) dataset. To avoid target ambiguity, the descriptions in FAO provide rich semantic scene information includes: object attribute, object relationship, region description, and nearby region description. Our experiments reveal that the proposed GBE outperforms various state-of-the-arts on both FAO and R2R datasets. And the ablation studies on FAO validates the quality of the dataset.
UPDeT: Universal Multi-agent Reinforcement Learning via Policy Decoupling with Transformers
Feb 07, 2021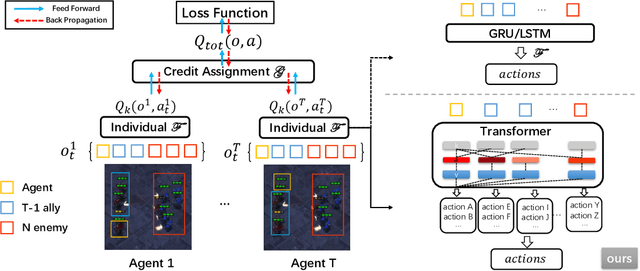
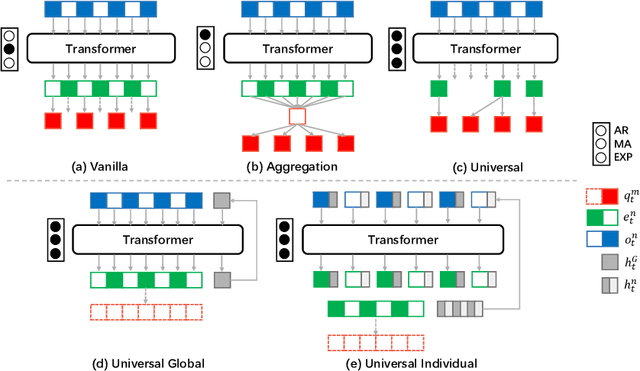
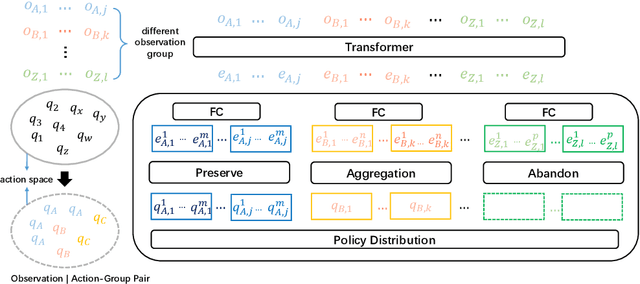
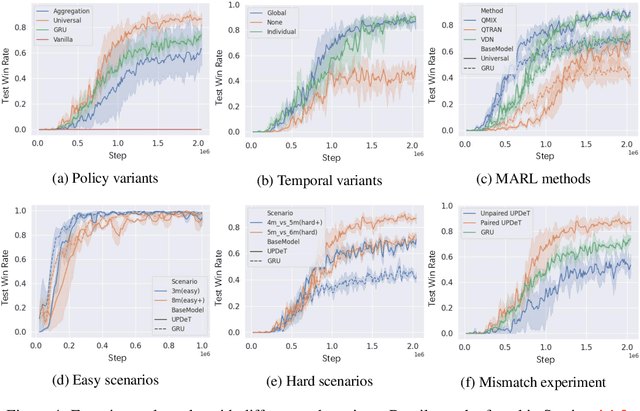
Recent advances in multi-agent reinforcement learning have been largely limited in training one model from scratch for every new task. The limitation is due to the restricted model architecture related to fixed input and output dimensions. This hinders the experience accumulation and transfer of the learned agent over tasks with diverse levels of difficulty (e.g. 3 vs 3 or 5 vs 6 multi-agent games). In this paper, we make the first attempt to explore a universal multi-agent reinforcement learning pipeline, designing one single architecture to fit tasks with the requirement of different observation and action configurations. Unlike previous RNN-based models, we utilize a transformer-based model to generate a flexible policy by decoupling the policy distribution from the intertwined input observation with an importance weight measured by the merits of the self-attention mechanism. Compared to a standard transformer block, the proposed model, named as Universal Policy Decoupling Transformer (UPDeT), further relaxes the action restriction and makes the multi-agent task's decision process more explainable. UPDeT is general enough to be plugged into any multi-agent reinforcement learning pipeline and equip them with strong generalization abilities that enables the handling of multiple tasks at a time. Extensive experiments on large-scale SMAC multi-agent competitive games demonstrate that the proposed UPDeT-based multi-agent reinforcement learning achieves significant results relative to state-of-the-art approaches, demonstrating advantageous transfer capability in terms of both performance and training speed (10 times faster).