 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneReason Technical Report
Jun 04, 2026Generative recommendation models in the OneRec family have been widely deployed in many real-world services, such as short-video, live-streaming, advertising, and e-commerce. However, these generative models can only benefit from the scaling advantage, while their reasoning ability is hard to activate, since we cannot construct meaningful Chain-of-Thought (CoT) sequences consisting of itemic tokens only. Inspired by the success of the reasoning-style ``think before answer'' paradigm in the LLM field, we conduct preliminary studies (i.e., OneRec-Think, OpenOneRec) to explore reasoning capability in generative recommendation. Nevertheless, we notice an unexpected phenomenon: the thinking mode does not show advantages over the non-thinking mode. Drawing insights from recent findings on CoT robustness in multi-modal language models, we argue that effective reasoning in recommendation rests on two factors: perception, the ability to ground itemic tokens in their underlying language semantics, and cognition, the ability to reorganize a user's behavior sequence into coherent latent interest points. We therefore propose OneReason, which includes: (1) strong itemic token perception in pre-training, (2) a three-level cognition-enhanced CoT format for recommendation tasks in SFT, and (3) a specialize-then-unify training recipe in RL to enhance the thinking ability.
Towards Real-world Human Behavior Simulation: Benchmarking Large Language Models on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces
Apr 09, 2026The emergence of Large Language Models (LLMs) has illuminated the potential for a general-purpose user simulator. However, existing benchmarks remain constrained to isolated scenarios, narrow action spaces, or synthetic data, failing to capture the holistic nature of authentic human behavior. To bridge this gap, we introduce OmniBehavior, the first user simulation benchmark constructed entirely from real-world data, integrating long-horizon, cross-scenario, and heterogeneous behavioral patterns into a unified framework. Based on this benchmark, we first provide empirical evidence that previous datasets with isolated scenarios suffer from tunnel vision, whereas real-world decision-making relies on long-term, cross-scenario causal chains. Extensive evaluations of state-of-the-art LLMs reveal that current models struggle to accurately simulate these complex behaviors, with performance plateauing even as context windows expand. Crucially, a systematic comparison between simulated and authentic behaviors uncovers a fundamental structural bias: LLMs tend to converge toward a positive average person, exhibiting hyper-activity, persona homogenization, and a Utopian bias. This results in the loss of individual differences and long-tail behaviors, highlighting critical directions for future high-fidelity simulation research.
ALIVE: Animate Your World with Lifelike Audio-Video Generation
Feb 09, 2026Video generation is rapidly evolving towards unified audio-video generation. In this paper, we present ALIVE, a generation model that adapts a pretrained Text-to-Video (T2V) model to Sora-style audio-video generation and animation. In particular, the model unlocks the Text-to-Video&Audio (T2VA) and Reference-to-Video&Audio (animation) capabilities compared to the T2V foundation models. To support the audio-visual synchronization and reference animation, we augment the popular MMDiT architecture with a joint audio-video branch which includes TA-CrossAttn for temporally-aligned cross-modal fusion and UniTemp-RoPE for precise audio-visual alignment. Meanwhile, a comprehensive data pipeline consisting of audio-video captioning, quality control, etc., is carefully designed to collect high-quality finetuning data. Additionally, we introduce a new benchmark to perform a comprehensive model test and comparison. After continue pretraining and finetuning on million-level high-quality data, ALIVE demonstrates outstanding performance, consistently outperforming open-source models and matching or surpassing state-of-the-art commercial solutions. With detailed recipes and benchmarks, we hope ALIVE helps the community develop audio-video generation models more efficiently. Official page: https://github.com/FoundationVision/Alive.
ALPBench: A Benchmark for Attribution-level Long-term Personal Behavior Understanding
Feb 03, 2026Recent advances in large language models have highlighted their potential for personalized recommendation, where accurately capturing user preferences remains a key challenge. Leveraging their strong reasoning and generalization capabilities, LLMs offer new opportunities for modeling long-term user behavior. To systematically evaluate this, we introduce ALPBench, a Benchmark for Attribution-level Long-term Personal Behavior Understanding. Unlike item-focused benchmarks, ALPBench predicts user-interested attribute combinations, enabling ground-truth evaluation even for newly introduced items. It models preferences from long-term historical behaviors rather than users' explicitly expressed requests, better reflecting enduring interests. User histories are represented as natural language sequences, allowing interpretable, reasoning-based personalization. ALPBench enables fine-grained evaluation of personalization by focusing on the prediction of attribute combinations task that remains highly challenging for current LLMs due to the need to capture complex interactions among multiple attributes and reason over long-term user behavior sequences.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
CLAMP: Crowdsourcing a LArge-scale in-the-wild haptic dataset with an open-source device for Multimodal robot Perception
May 27, 2025


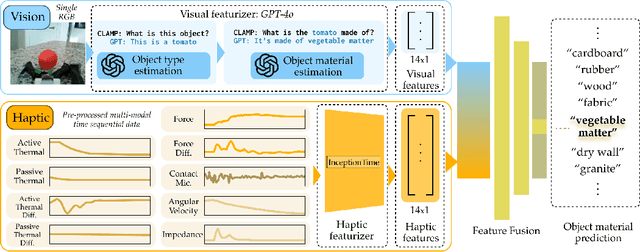
Robust robot manipulation in unstructured environments often requires understanding object properties that extend beyond geometry, such as material or compliance-properties that can be challenging to infer using vision alone. Multimodal haptic sensing provides a promising avenue for inferring such properties, yet progress has been constrained by the lack of large, diverse, and realistic haptic datasets. In this work, we introduce the CLAMP device, a low-cost (<\$200) sensorized reacher-grabber designed to collect large-scale, in-the-wild multimodal haptic data from non-expert users in everyday settings. We deployed 16 CLAMP devices to 41 participants, resulting in the CLAMP dataset, the largest open-source multimodal haptic dataset to date, comprising 12.3 million datapoints across 5357 household objects. Using this dataset, we train a haptic encoder that can infer material and compliance object properties from multimodal haptic data. We leverage this encoder to create the CLAMP model, a visuo-haptic perception model for material recognition that generalizes to novel objects and three robot embodiments with minimal finetuning. We also demonstrate the effectiveness of our model in three real-world robot manipulation tasks: sorting recyclable and non-recyclable waste, retrieving objects from a cluttered bag, and distinguishing overripe from ripe bananas. Our results show that large-scale, in-the-wild haptic data collection can unlock new capabilities for generalizable robot manipulation. Website: https://emprise.cs.cornell.edu/clamp/
AgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
GraphRPM: Risk Pattern Mining on Industrial Large Attributed Graphs
Nov 11, 2024Graph-based patterns are extensively employed and favored by practitioners within industrial companies due to their capacity to represent the behavioral attributes and topological relationships among users, thereby offering enhanced interpretability in comparison to black-box models commonly utilized for classification and recognition tasks. For instance, within the scenario of transaction risk management, a graph pattern that is characteristic of a particular risk category can be readily employed to discern transactions fraught with risk, delineate networks of criminal activity, or investigate the methodologies employed by fraudsters. Nonetheless, graph data in industrial settings is often characterized by its massive scale, encompassing data sets with millions or even billions of nodes, making the manual extraction of graph patterns not only labor-intensive but also necessitating specialized knowledge in particular domains of risk. Moreover, existing methodologies for mining graph patterns encounter significant obstacles when tasked with analyzing large-scale attributed graphs. In this work, we introduce GraphRPM, an industry-purpose parallel and distributed risk pattern mining framework on large attributed graphs. The framework incorporates a novel edge-involved graph isomorphism network alongside optimized operations for parallel graph computation, which collectively contribute to a considerable reduction in computational complexity and resource expenditure. Moreover, the intelligent filtration of efficacious risky graph patterns is facilitated by the proposed evaluation metrics. Comprehensive experimental evaluations conducted on real-world datasets of varying sizes substantiate the capability of GraphRPM to adeptly address the challenges inherent in mining patterns from large-scale industrial attributed graphs, thereby underscoring its substantial value for industrial deployment.
EVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024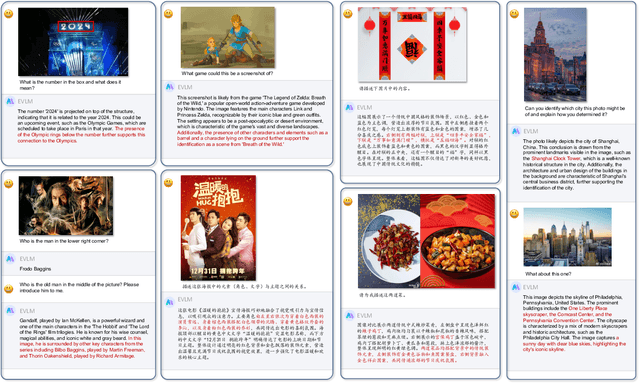
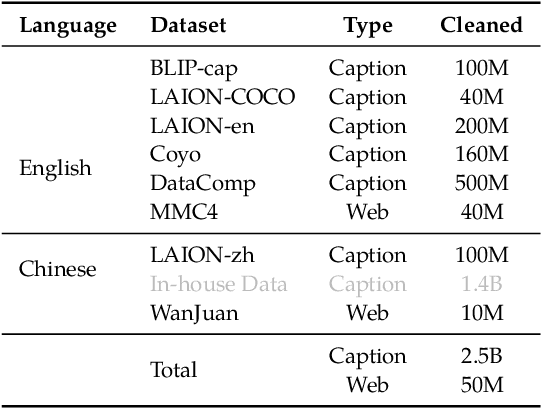
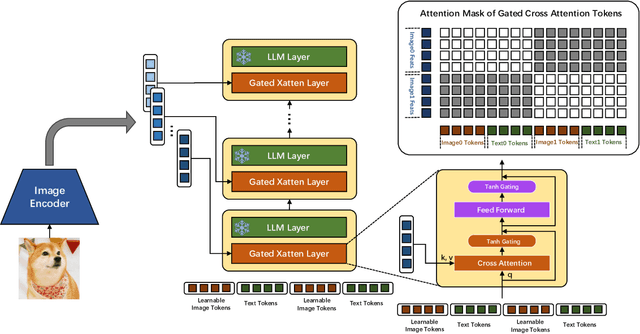

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.