 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Video Intelligence: A Flexible Framework for Advanced Video Exploration and Understanding
Nov 18, 2025
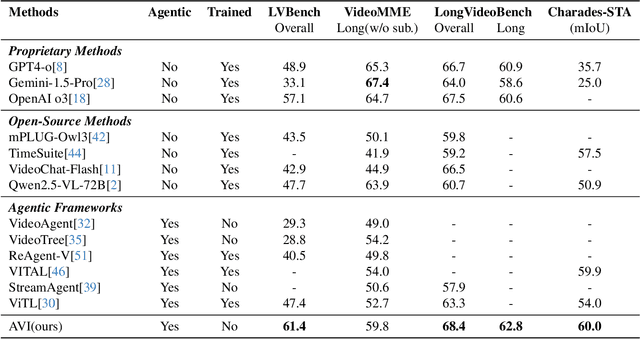
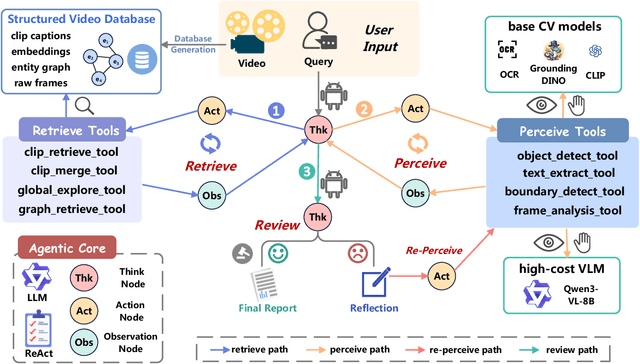
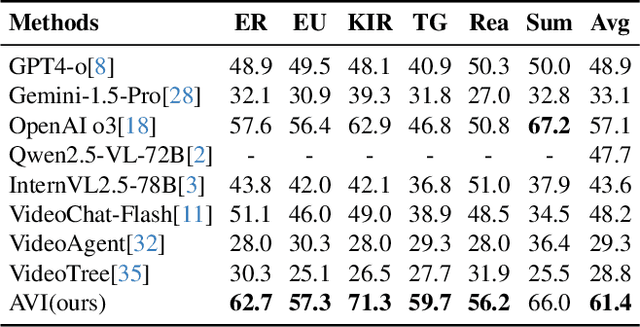
Video understanding requires not only visual recognition but also complex reasoning. While Vision-Language Models (VLMs) demonstrate impressive capabilities, they typically process videos largely in a single-pass manner with limited support for evidence revisit and iterative refinement. While recently emerging agent-based methods enable long-horizon reasoning, they either depend heavily on expensive proprietary models or require extensive agentic RL training. To overcome these limitations, we propose Agentic Video Intelligence (AVI), a flexible and training-free framework that can mirror human video comprehension through system-level design and optimization. AVI introduces three key innovations: (1) a human-inspired three-phase reasoning process (Retrieve-Perceive-Review) that ensures both sufficient global exploration and focused local analysis, (2) a structured video knowledge base organized through entity graphs, along with multi-granularity integrated tools, constituting the agent's interaction environment, and (3) an open-source model ensemble combining reasoning LLMs with lightweight base CV models and VLM, eliminating dependence on proprietary APIs or RL training. Experiments on LVBench, VideoMME-Long, LongVideoBench, and Charades-STA demonstrate that AVI achieves competitive performance while offering superior interpretability.
Partial Action Replacement: Tackling Distribution Shift in Offline MARL
Nov 10, 2025Offline multi-agent reinforcement learning (MARL) is severely hampered by the challenge of evaluating out-of-distribution (OOD) joint actions. Our core finding is that when the behavior policy is factorized - a common scenario where agents act fully or partially independently during data collection - a strategy of partial action replacement (PAR) can significantly mitigate this challenge. PAR updates a single or part of agents' actions while the others remain fixed to the behavioral data, reducing distribution shift compared to full joint-action updates. Based on this insight, we develop Soft-Partial Conservative Q-Learning (SPaCQL), using PAR to mitigate OOD issue and dynamically weighting different PAR strategies based on the uncertainty of value estimation. We provide a rigorous theoretical foundation for this approach, proving that under factorized behavior policies, the induced distribution shift scales linearly with the number of deviating agents rather than exponentially with the joint-action space. This yields a provably tighter value error bound for this important class of offline MARL problems. Our theoretical results also indicate that SPaCQL adaptively addresses distribution shift using uncertainty-informed weights. Our empirical results demonstrate SPaCQL enables more effective policy learning, and manifest its remarkable superiority over baseline algorithms when the offline dataset exhibits the independence structure.
GraphGen+: Advancing Distributed Subgraph Generation and Graph Learning On Industrial Graphs
Mar 08, 2025Graph-based computations are crucial in a wide range of applications, where graphs can scale to trillions of edges. To enable efficient training on such large graphs, mini-batch subgraph sampling is commonly used, which allows training without loading the entire graph into memory. However, existing solutions face significant trade-offs: online subgraph generation, as seen in frameworks like DGL and PyG, is limited to a single machine, resulting in severe performance bottlenecks, while offline precomputed subgraphs, as in GraphGen, improve sampling efficiency but introduce large storage overhead and high I/O costs during training. To address these challenges, we propose \textbf{GraphGen+}, an integrated framework that synchronizes distributed subgraph generation with in-memory graph learning, eliminating the need for external storage while significantly improving efficiency. GraphGen+ achieves a \textbf{27$\times$} speedup in subgraph generation compared to conventional SQL-like methods and a \textbf{1.3$\times$} speedup over GraphGen, supporting training on 1 million nodes per iteration and removing the overhead associated with precomputed subgraphs, making it a scalable and practical solution for industry-scale graph learning.
Achieving Collective Welfare in Multi-Agent Reinforcement Learning via Suggestion Sharing
Dec 16, 2024In human society, the conflict between self-interest and collective well-being often obstructs efforts to achieve shared welfare. Related concepts like the Tragedy of the Commons and Social Dilemmas frequently manifest in our daily lives. As artificial agents increasingly serve as autonomous proxies for humans, we propose using multi-agent reinforcement learning (MARL) to address this issue - learning policies to maximise collective returns even when individual agents' interests conflict with the collective one. Traditional MARL solutions involve sharing rewards, values, and policies or designing intrinsic rewards to encourage agents to learn collectively optimal policies. We introduce a novel MARL approach based on Suggestion Sharing (SS), where agents exchange only action suggestions. This method enables effective cooperation without the need to design intrinsic rewards, achieving strong performance while revealing less private information compared to sharing rewards, values, or policies. Our theoretical analysis establishes a bound on the discrepancy between collective and individual objectives, demonstrating how sharing suggestions can align agents' behaviours with the collective objective. Experimental results demonstrate that SS performs competitively with baselines that rely on value or policy sharing or intrinsic rewards.
Learning on One Mode: Addressing Multi-Modality in Offline Reinforcement Learning
Dec 04, 2024Offline reinforcement learning (RL) seeks to learn optimal policies from static datasets without interacting with the environment. A common challenge is handling multi-modal action distributions, where multiple behaviours are represented in the data. Existing methods often assume unimodal behaviour policies, leading to suboptimal performance when this assumption is violated. We propose Weighted Imitation Learning on One Mode (LOM), a novel approach that focuses on learning from a single, promising mode of the behaviour policy. By using a Gaussian mixture model to identify modes and selecting the best mode based on expected returns, LOM avoids the pitfalls of averaging over conflicting actions. Theoretically, we show that LOM improves performance while maintaining simplicity in policy learning. Empirically, LOM outperforms existing methods on standard D4RL benchmarks and demonstrates its effectiveness in complex, multi-modal scenarios.
Mitigating Relative Over-Generalization in Multi-Agent Reinforcement Learning
Nov 17, 2024In decentralized multi-agent reinforcement learning, agents learning in isolation can lead to relative over-generalization (RO), where optimal joint actions are undervalued in favor of suboptimal ones. This hinders effective coordination in cooperative tasks, as agents tend to choose actions that are individually rational but collectively suboptimal. To address this issue, we introduce MaxMax Q-Learning (MMQ), which employs an iterative process of sampling and evaluating potential next states, selecting those with maximal Q-values for learning. This approach refines approximations of ideal state transitions, aligning more closely with the optimal joint policy of collaborating agents. We provide theoretical analysis supporting MMQ's potential and present empirical evaluations across various environments susceptible to RO. Our results demonstrate that MMQ frequently outperforms existing baselines, exhibiting enhanced convergence and sample efficiency.
GraphRPM: Risk Pattern Mining on Industrial Large Attributed Graphs
Nov 11, 2024Graph-based patterns are extensively employed and favored by practitioners within industrial companies due to their capacity to represent the behavioral attributes and topological relationships among users, thereby offering enhanced interpretability in comparison to black-box models commonly utilized for classification and recognition tasks. For instance, within the scenario of transaction risk management, a graph pattern that is characteristic of a particular risk category can be readily employed to discern transactions fraught with risk, delineate networks of criminal activity, or investigate the methodologies employed by fraudsters. Nonetheless, graph data in industrial settings is often characterized by its massive scale, encompassing data sets with millions or even billions of nodes, making the manual extraction of graph patterns not only labor-intensive but also necessitating specialized knowledge in particular domains of risk. Moreover, existing methodologies for mining graph patterns encounter significant obstacles when tasked with analyzing large-scale attributed graphs. In this work, we introduce GraphRPM, an industry-purpose parallel and distributed risk pattern mining framework on large attributed graphs. The framework incorporates a novel edge-involved graph isomorphism network alongside optimized operations for parallel graph computation, which collectively contribute to a considerable reduction in computational complexity and resource expenditure. Moreover, the intelligent filtration of efficacious risky graph patterns is facilitated by the proposed evaluation metrics. Comprehensive experimental evaluations conducted on real-world datasets of varying sizes substantiate the capability of GraphRPM to adeptly address the challenges inherent in mining patterns from large-scale industrial attributed graphs, thereby underscoring its substantial value for industrial deployment.
State-Constrained Offline Reinforcement Learning
May 23, 2024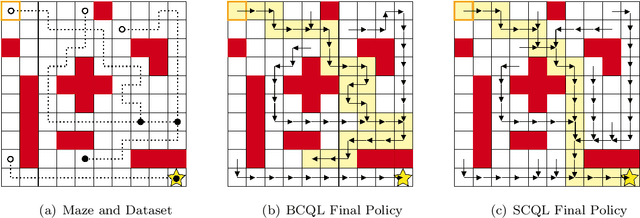

Traditional offline reinforcement learning methods predominantly operate in a batch-constrained setting. This confines the algorithms to a specific state-action distribution present in the dataset, reducing the effects of distributional shift but restricting the algorithm greatly. In this paper, we alleviate this limitation by introducing a novel framework named \emph{state-constrained} offline reinforcement learning. By exclusively focusing on the dataset's state distribution, our framework significantly enhances learning potential and reduces previous limitations. The proposed setting not only broadens the learning horizon but also improves the ability to combine different trajectories from the dataset effectively, a desirable property inherent in offline reinforcement learning. Our research is underpinned by solid theoretical findings that pave the way for subsequent advancements in this domain. Additionally, we introduce StaCQ, a deep learning algorithm that is both performance-driven on the D4RL benchmark datasets and closely aligned with our theoretical propositions. StaCQ establishes a strong baseline for forthcoming explorations in state-constrained offline reinforcement learning.
Goal-conditioned Offline Reinforcement Learning through State Space Partitioning
Mar 16, 2023Offline reinforcement learning (RL) aims to infer sequential decision policies using only offline datasets. This is a particularly difficult setup, especially when learning to achieve multiple different goals or outcomes under a given scenario with only sparse rewards. For offline learning of goal-conditioned policies via supervised learning, previous work has shown that an advantage weighted log-likelihood loss guarantees monotonic policy improvement. In this work we argue that, despite its benefits, this approach is still insufficient to fully address the distribution shift and multi-modality problems. The latter is particularly severe in long-horizon tasks where finding a unique and optimal policy that goes from a state to the desired goal is challenging as there may be multiple and potentially conflicting solutions. To tackle these challenges, we propose a complementary advantage-based weighting scheme that introduces an additional source of inductive bias: given a value-based partitioning of the state space, the contribution of actions expected to lead to target regions that are easier to reach, compared to the final goal, is further increased. Empirically, we demonstrate that the proposed approach, Dual-Advantage Weighted Offline Goal-conditioned RL (DAWOG), outperforms several competing offline algorithms in commonly used benchmarks. Analytically, we offer a guarantee that the learnt policy is never worse than the underlying behaviour policy.
Promoting Cooperation in Multi-Agent Reinforcement Learning via Mutual Help
Feb 18, 2023Multi-agent reinforcement learning (MARL) has achieved great progress in cooperative tasks in recent years. However, in the local reward scheme, where only local rewards for each agent are given without global rewards shared by all the agents, traditional MARL algorithms lack sufficient consideration of agents' mutual influence. In cooperative tasks, agents' mutual influence is especially important since agents are supposed to coordinate to achieve better performance. In this paper, we propose a novel algorithm Mutual-Help-based MARL (MH-MARL) to instruct agents to help each other in order to promote cooperation. MH-MARL utilizes an expected action module to generate expected other agents' actions for each particular agent. Then, the expected actions are delivered to other agents for selective imitation during training. Experimental results show that MH-MARL improves the performance of MARL both in success rate and cumulative reward.