 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular Foundation Models are Strong Graph Anomaly Detectors
Jan 24, 2026Graph anomaly detection (GAD), which aims to identify abnormal nodes that deviate from the majority, has become increasingly important in high-stakes Web domains. However, existing GAD methods follow a "one model per dataset" paradigm, leading to high computational costs, substantial data demands, and poor generalization when transferred to new datasets. This calls for a foundation model that enables a "one-for-all" GAD solution capable of detecting anomalies across diverse graphs without retraining. Yet, achieving this is challenging due to the large structural and feature heterogeneity across domains. In this paper, we propose TFM4GAD, a simple yet effective framework that adapts tabular foundation models (TFMs) for graph anomaly detection. Our key insight is that the core challenges of foundation GAD, handling heterogeneous features, generalizing across domains, and operating with scarce labels, are the exact problems that modern TFMs are designed to solve via synthetic pre-training and powerful in-context learning. The primary challenge thus becomes structural: TFMs are agnostic to graph topology. TFM4GAD bridges this gap by "flattening" the graph, constructing an augmented feature table that enriches raw node features with Laplacian embeddings, local and global structural characteristics, and anomaly-sensitive neighborhood aggregations. This augmented table is processed by a TFM in a fully in-context regime. Extensive experiments on multiple datasets with various TFM backbones reveal that TFM4GAD surprisingly achieves significant performance gains over specialized GAD models trained from scratch. Our work offers a new perspective and a practical paradigm for leveraging TFMs as powerful, generalist graph anomaly detectors.
GraphGen+: Advancing Distributed Subgraph Generation and Graph Learning On Industrial Graphs
Mar 08, 2025Graph-based computations are crucial in a wide range of applications, where graphs can scale to trillions of edges. To enable efficient training on such large graphs, mini-batch subgraph sampling is commonly used, which allows training without loading the entire graph into memory. However, existing solutions face significant trade-offs: online subgraph generation, as seen in frameworks like DGL and PyG, is limited to a single machine, resulting in severe performance bottlenecks, while offline precomputed subgraphs, as in GraphGen, improve sampling efficiency but introduce large storage overhead and high I/O costs during training. To address these challenges, we propose \textbf{GraphGen+}, an integrated framework that synchronizes distributed subgraph generation with in-memory graph learning, eliminating the need for external storage while significantly improving efficiency. GraphGen+ achieves a \textbf{27$\times$} speedup in subgraph generation compared to conventional SQL-like methods and a \textbf{1.3$\times$} speedup over GraphGen, supporting training on 1 million nodes per iteration and removing the overhead associated with precomputed subgraphs, making it a scalable and practical solution for industry-scale graph learning.
Distributed Graph Neural Network Inference With Just-In-Time Compilation For Industry-Scale Graphs
Mar 08, 2025Graph neural networks (GNNs) have delivered remarkable results in various fields. However, the rapid increase in the scale of graph data has introduced significant performance bottlenecks for GNN inference. Both computational complexity and memory usage have risen dramatically, with memory becoming a critical limitation. Although graph sampling-based subgraph learning methods can help mitigate computational and memory demands, they come with drawbacks such as information loss and high redundant computation among subgraphs. This paper introduces an innovative processing paradgim for distributed graph learning that abstracts GNNs with a new set of programming interfaces and leverages Just-In-Time (JIT) compilation technology to its full potential. This paradigm enables GNNs to highly exploit the computational resources of distributed clusters by eliminating the drawbacks of subgraph learning methods, leading to a more efficient inference process. Our experimental results demonstrate that on industry-scale graphs of up to \textbf{500 million nodes and 22.4 billion edges}, our method can produce a performance boost of up to \textbf{27.4 times}.
Transferable and Forecastable User Targeting Foundation Model
Dec 17, 2024



User targeting, the process of selecting targeted users from a pool of candidates for non-expert marketers, has garnered substantial attention with the advancements in digital marketing. However, existing user targeting methods encounter two significant challenges: (i) Poor cross-domain and cross-scenario transferability and generalization, and (ii) Insufficient forecastability in real-world applications. These limitations hinder their applicability across diverse industrial scenarios. In this work, we propose FIND, an industrial-grade, transferable, and forecastable user targeting foundation model. To enhance cross-domain transferability, our framework integrates heterogeneous multi-scenario user data, aligning them with one-sentence targeting demand inputs through contrastive pre-training. For improved forecastability, the text description of each user is derived based on anticipated future behaviors, while user representations are constructed from historical information. Experimental results demonstrate that our approach significantly outperforms existing baselines in cross-domain, real-world user targeting scenarios, showcasing the superior capabilities of FIND. Moreover, our method has been successfully deployed on the Alipay platform and is widely utilized across various scenarios.
Multi-Grained Preference Enhanced Transformer for Multi-Behavior Sequential Recommendation
Nov 19, 2024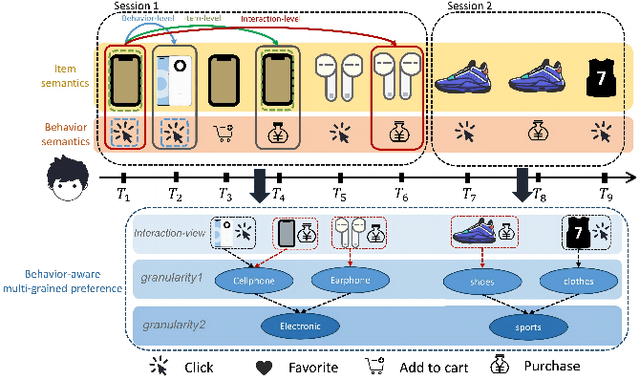
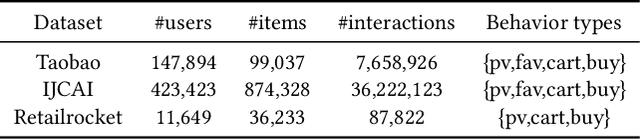
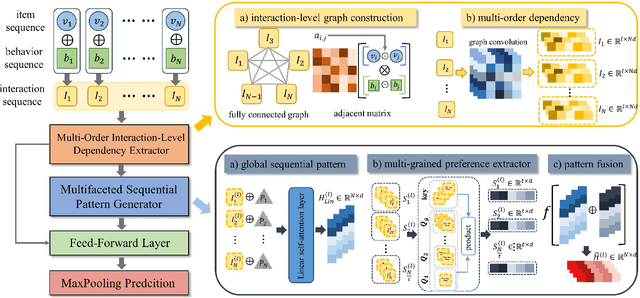
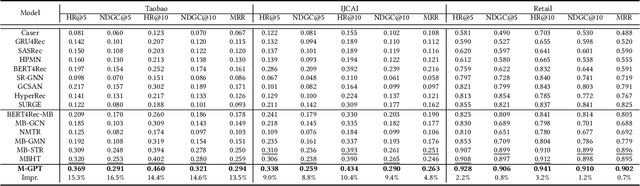
Sequential recommendation (SR) aims to predict the next purchasing item according to users' dynamic preference learned from their historical user-item interactions. To improve the performance of recommendation, learning dynamic heterogeneous cross-type behavior dependencies is indispensable for recommender system. However, there still exists some challenges in Multi-Behavior Sequential Recommendation (MBSR). On the one hand, existing methods only model heterogeneous multi-behavior dependencies at behavior-level or item-level, and modelling interaction-level dependencies is still a challenge. On the other hand, the dynamic multi-grained behavior-aware preference is hard to capture in interaction sequences, which reflects interaction-aware sequential pattern. To tackle these challenges, we propose a Multi-Grained Preference enhanced Transformer framework (M-GPT). First, M-GPT constructs a interaction-level graph of historical cross-typed interactions in a sequence. Then graph convolution is performed to derive interaction-level multi-behavior dependency representation repeatedly, in which the complex correlation between historical cross-typed interactions at specific orders can be well learned. Secondly, a novel multi-scale transformer architecture equipped with multi-grained user preference extraction is proposed to encode the interaction-aware sequential pattern enhanced by capturing temporal behavior-aware multi-grained preference . Experiments on the real-world datasets indicate that our method M-GPT consistently outperforms various state-of-the-art recommendation methods.
GraphRPM: Risk Pattern Mining on Industrial Large Attributed Graphs
Nov 11, 2024Graph-based patterns are extensively employed and favored by practitioners within industrial companies due to their capacity to represent the behavioral attributes and topological relationships among users, thereby offering enhanced interpretability in comparison to black-box models commonly utilized for classification and recognition tasks. For instance, within the scenario of transaction risk management, a graph pattern that is characteristic of a particular risk category can be readily employed to discern transactions fraught with risk, delineate networks of criminal activity, or investigate the methodologies employed by fraudsters. Nonetheless, graph data in industrial settings is often characterized by its massive scale, encompassing data sets with millions or even billions of nodes, making the manual extraction of graph patterns not only labor-intensive but also necessitating specialized knowledge in particular domains of risk. Moreover, existing methodologies for mining graph patterns encounter significant obstacles when tasked with analyzing large-scale attributed graphs. In this work, we introduce GraphRPM, an industry-purpose parallel and distributed risk pattern mining framework on large attributed graphs. The framework incorporates a novel edge-involved graph isomorphism network alongside optimized operations for parallel graph computation, which collectively contribute to a considerable reduction in computational complexity and resource expenditure. Moreover, the intelligent filtration of efficacious risky graph patterns is facilitated by the proposed evaluation metrics. Comprehensive experimental evaluations conducted on real-world datasets of varying sizes substantiate the capability of GraphRPM to adeptly address the challenges inherent in mining patterns from large-scale industrial attributed graphs, thereby underscoring its substantial value for industrial deployment.
Subgraph Retrieval Enhanced by Graph-Text Alignment for Commonsense Question Answering
Nov 11, 2024Commonsense question answering is a crucial task that requires machines to employ reasoning according to commonsense. Previous studies predominantly employ an extracting-and-modeling paradigm to harness the information in KG, which first extracts relevant subgraphs based on pre-defined rules and then proceeds to design various strategies aiming to improve the representations and fusion of the extracted structural knowledge. Despite their effectiveness, there are still two challenges. On one hand, subgraphs extracted by rule-based methods may have the potential to overlook critical nodes and result in uncontrollable subgraph size. On the other hand, the misalignment between graph and text modalities undermines the effectiveness of knowledge fusion, ultimately impacting the task performance. To deal with the problems above, we propose a novel framework: \textbf{S}ubgraph R\textbf{E}trieval Enhanced by Gra\textbf{P}h-\textbf{T}ext \textbf{A}lignment, named \textbf{SEPTA}. Firstly, we transform the knowledge graph into a database of subgraph vectors and propose a BFS-style subgraph sampling strategy to avoid information loss, leveraging the analogy between BFS and the message-passing mechanism. In addition, we propose a bidirectional contrastive learning approach for graph-text alignment, which effectively enhances both subgraph retrieval and knowledge fusion. Finally, all the retrieved information is combined for reasoning in the prediction module. Extensive experiments on five datasets demonstrate the effectiveness and robustness of our framework.
GraphCLIP: Enhancing Transferability in Graph Foundation Models for Text-Attributed Graphs
Oct 15, 2024



Recently, research on Text-Attributed Graphs (TAGs) has gained significant attention due to the prevalence of free-text node features in real-world applications and the advancements in Large Language Models (LLMs) that bolster TAG methodologies. However, current TAG approaches face two primary challenges: (i) Heavy reliance on label information and (ii) Limited cross-domain zero/few-shot transferability. These issues constrain the scaling of both data and model size, owing to high labor costs and scaling laws, complicating the development of graph foundation models with strong transferability. In this work, we propose the GraphCLIP framework to address these challenges by learning graph foundation models with strong cross-domain zero/few-shot transferability through a self-supervised contrastive graph-summary pretraining method. Specifically, we generate and curate large-scale graph-summary pair data with the assistance of LLMs, and introduce a novel graph-summary pretraining method, combined with invariant learning, to enhance graph foundation models with strong cross-domain zero-shot transferability. For few-shot learning, we propose a novel graph prompt tuning technique aligned with our pretraining objective to mitigate catastrophic forgetting and minimize learning costs. Extensive experiments show the superiority of GraphCLIP in both zero-shot and few-shot settings, while evaluations across various downstream tasks confirm the versatility of GraphCLIP. Our code is available at: https://github.com/ZhuYun97/GraphCLIP
Graph Retrieval-Augmented Generation: A Survey
Aug 15, 2024



Recently, Retrieval-Augmented Generation (RAG) has achieved remarkable success in addressing the challenges of Large Language Models (LLMs) without necessitating retraining. By referencing an external knowledge base, RAG refines LLM outputs, effectively mitigating issues such as ``hallucination'', lack of domain-specific knowledge, and outdated information. However, the complex structure of relationships among different entities in databases presents challenges for RAG systems. In response, GraphRAG leverages structural information across entities to enable more precise and comprehensive retrieval, capturing relational knowledge and facilitating more accurate, context-aware responses. Given the novelty and potential of GraphRAG, a systematic review of current technologies is imperative. This paper provides the first comprehensive overview of GraphRAG methodologies. We formalize the GraphRAG workflow, encompassing Graph-Based Indexing, Graph-Guided Retrieval, and Graph-Enhanced Generation. We then outline the core technologies and training methods at each stage. Additionally, we examine downstream tasks, application domains, evaluation methodologies, and industrial use cases of GraphRAG. Finally, we explore future research directions to inspire further inquiries and advance progress in the field.
Graph Triple Attention Network: A Decoupled Perspective
Aug 14, 2024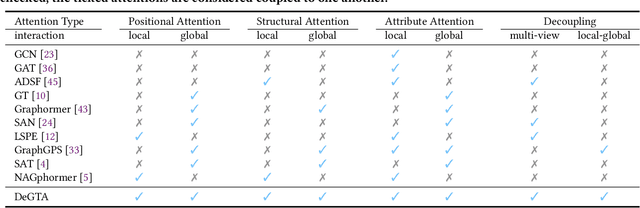
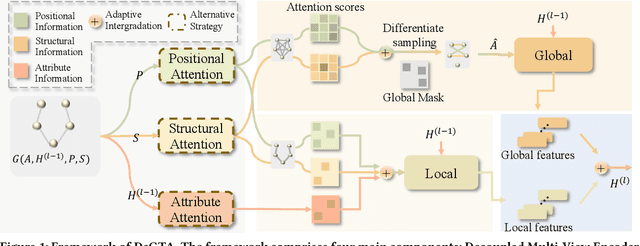
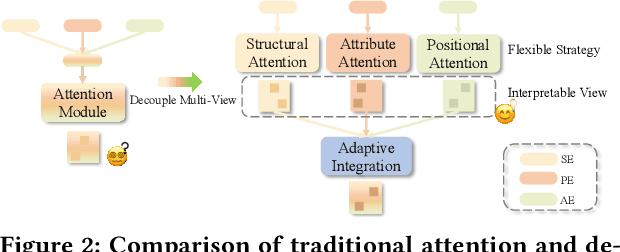
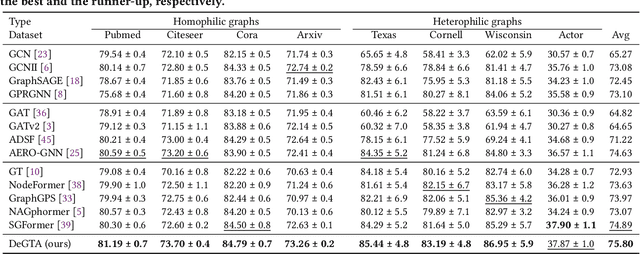
Graph Transformers (GTs) have recently achieved significant success in the graph domain by effectively capturing both long-range dependencies and graph inductive biases. However, these methods face two primary challenges: (1) multi-view chaos, which results from coupling multi-view information (positional, structural, attribute), thereby impeding flexible usage and the interpretability of the propagation process. (2) local-global chaos, which arises from coupling local message passing with global attention, leading to issues of overfitting and over-globalizing. To address these challenges, we propose a high-level decoupled perspective of GTs, breaking them down into three components and two interaction levels: positional attention, structural attention, and attribute attention, alongside local and global interaction. Based on this decoupled perspective, we design a decoupled graph triple attention network named DeGTA, which separately computes multi-view attentions and adaptively integrates multi-view local and global information. This approach offers three key advantages: enhanced interpretability, flexible design, and adaptive integration of local and global information. Through extensive experiments, DeGTA achieves state-of-the-art performance across various datasets and tasks, including node classification and graph classification. Comprehensive ablation studies demonstrate that decoupling is essential for improving performance and enhancing interpretability. Our code is available at: https://github.com/wangxiaotang0906/DeGTA