 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphCLIP: Enhancing Transferability in Graph Foundation Models for Text-Attributed Graphs
Oct 15, 2024



Recently, research on Text-Attributed Graphs (TAGs) has gained significant attention due to the prevalence of free-text node features in real-world applications and the advancements in Large Language Models (LLMs) that bolster TAG methodologies. However, current TAG approaches face two primary challenges: (i) Heavy reliance on label information and (ii) Limited cross-domain zero/few-shot transferability. These issues constrain the scaling of both data and model size, owing to high labor costs and scaling laws, complicating the development of graph foundation models with strong transferability. In this work, we propose the GraphCLIP framework to address these challenges by learning graph foundation models with strong cross-domain zero/few-shot transferability through a self-supervised contrastive graph-summary pretraining method. Specifically, we generate and curate large-scale graph-summary pair data with the assistance of LLMs, and introduce a novel graph-summary pretraining method, combined with invariant learning, to enhance graph foundation models with strong cross-domain zero-shot transferability. For few-shot learning, we propose a novel graph prompt tuning technique aligned with our pretraining objective to mitigate catastrophic forgetting and minimize learning costs. Extensive experiments show the superiority of GraphCLIP in both zero-shot and few-shot settings, while evaluations across various downstream tasks confirm the versatility of GraphCLIP. Our code is available at: https://github.com/ZhuYun97/GraphCLIP
Graph Triple Attention Network: A Decoupled Perspective
Aug 14, 2024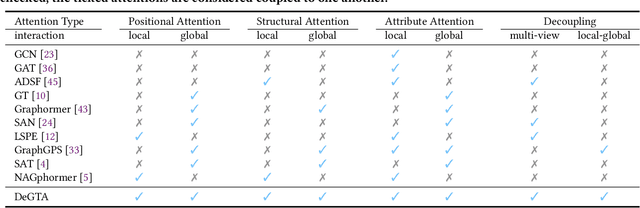
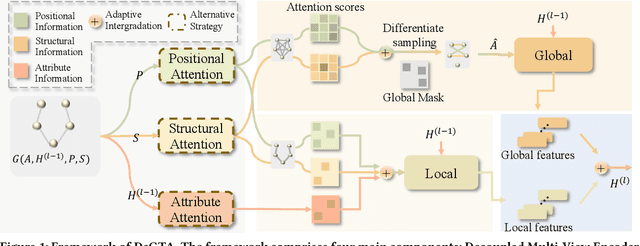
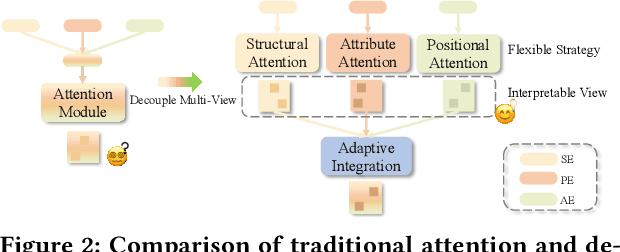
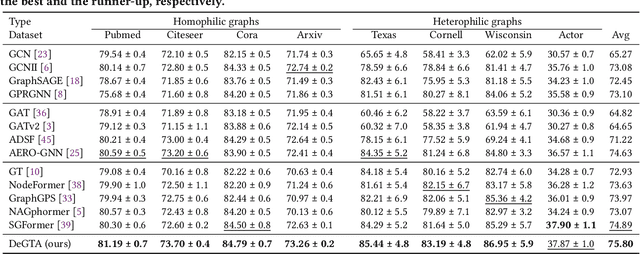
Graph Transformers (GTs) have recently achieved significant success in the graph domain by effectively capturing both long-range dependencies and graph inductive biases. However, these methods face two primary challenges: (1) multi-view chaos, which results from coupling multi-view information (positional, structural, attribute), thereby impeding flexible usage and the interpretability of the propagation process. (2) local-global chaos, which arises from coupling local message passing with global attention, leading to issues of overfitting and over-globalizing. To address these challenges, we propose a high-level decoupled perspective of GTs, breaking them down into three components and two interaction levels: positional attention, structural attention, and attribute attention, alongside local and global interaction. Based on this decoupled perspective, we design a decoupled graph triple attention network named DeGTA, which separately computes multi-view attentions and adaptively integrates multi-view local and global information. This approach offers three key advantages: enhanced interpretability, flexible design, and adaptive integration of local and global information. Through extensive experiments, DeGTA achieves state-of-the-art performance across various datasets and tasks, including node classification and graph classification. Comprehensive ablation studies demonstrate that decoupling is essential for improving performance and enhancing interpretability. Our code is available at: https://github.com/wangxiaotang0906/DeGTA
UniGAP: A Universal and Adaptive Graph Upsampling Approach to Mitigate Over-Smoothing in Node Classification Tasks
Jul 28, 2024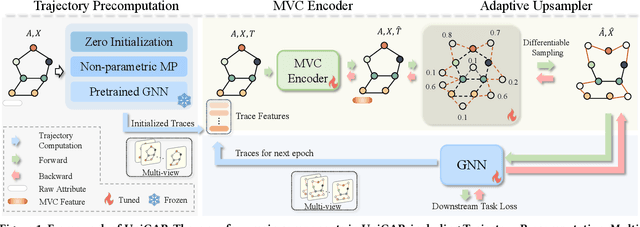


In the graph domain, deep graph networks based on Message Passing Neural Networks (MPNNs) or Graph Transformers often cause over-smoothing of node features, limiting their expressive capacity. Many upsampling techniques involving node and edge manipulation have been proposed to mitigate this issue. However, these methods often require extensive manual labor, resulting in suboptimal performance and lacking a universal integration strategy. In this study, we introduce UniGAP, a universal and adaptive graph upsampling technique for graph data. It provides a universal framework for graph upsampling, encompassing most current methods as variants. Moreover, UniGAP serves as a plug-in component that can be seamlessly and adaptively integrated with existing GNNs to enhance performance and mitigate the over-smoothing problem. Through extensive experiments, UniGAP demonstrates significant improvements over heuristic data augmentation methods across various datasets and metrics. We analyze how graph structure evolves with UniGAP, identifying key bottlenecks where over-smoothing occurs, and providing insights into how UniGAP addresses this issue. Lastly, we show the potential of combining UniGAP with large language models (LLMs) to further improve downstream performance. Our code is available at: https://github.com/wangxiaotang0906/UniGAP
Learning to Rank for Maps at Airbnb
Jun 25, 2024



As a two-sided marketplace, Airbnb brings together hosts who own listings for rent with prospective guests from around the globe. Results from a guest's search for listings are displayed primarily through two interfaces: (1) as a list of rectangular cards that contain on them the listing image, price, rating, and other details, referred to as list-results (2) as oval pins on a map showing the listing price, called map-results. Both these interfaces, since their inception, have used the same ranking algorithm that orders listings by their booking probabilities and selects the top listings for display. But some of the basic assumptions underlying ranking, built for a world where search results are presented as lists, simply break down for maps. This paper describes how we rebuilt ranking for maps by revising the mathematical foundations of how users interact with search results. Our iterative and experiment-driven approach led us through a path full of twists and turns, ending in a unified theory for the two interfaces. Our journey shows how assumptions taken for granted when designing machine learning algorithms may not apply equally across all user interfaces, and how they can be adapted. The net impact was one of the largest improvements in user experience for Airbnb which we discuss as a series of experimental validations.