 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Reflection: A Feedback-Free Reflection Learning Framework
Dec 18, 2024



Despite the remarkable capabilities of large language models (LLMs) in natural language understanding and reasoning, they often display undesirable behaviors, such as generating hallucinations and unfaithful reasoning. A prevalent strategy to mitigate these issues is the use of reflection, which refines responses through an iterative process. However, while promising, reflection heavily relies on high-quality external feedback and requires iterative multi-agent inference processes, thus hindering its practical application. In this paper, we propose Meta-Reflection, a novel feedback-free reflection mechanism that necessitates only a single inference pass without external feedback. Motivated by the human ability to remember and retrieve reflections from past experiences when encountering similar problems, Meta-Reflection integrates reflective insights into a codebook, allowing the historical insights to be stored, retrieved, and used to guide LLMs in problem-solving. To thoroughly investigate and evaluate the practicality of Meta-Reflection in real-world scenarios, we introduce an industrial e-commerce benchmark named E-commerce Customer Intent Detection (ECID). Extensive experiments conducted on both public datasets and the ECID benchmark highlight the effectiveness and efficiency of our proposed approach.
GraphCLIP: Enhancing Transferability in Graph Foundation Models for Text-Attributed Graphs
Oct 15, 2024



Recently, research on Text-Attributed Graphs (TAGs) has gained significant attention due to the prevalence of free-text node features in real-world applications and the advancements in Large Language Models (LLMs) that bolster TAG methodologies. However, current TAG approaches face two primary challenges: (i) Heavy reliance on label information and (ii) Limited cross-domain zero/few-shot transferability. These issues constrain the scaling of both data and model size, owing to high labor costs and scaling laws, complicating the development of graph foundation models with strong transferability. In this work, we propose the GraphCLIP framework to address these challenges by learning graph foundation models with strong cross-domain zero/few-shot transferability through a self-supervised contrastive graph-summary pretraining method. Specifically, we generate and curate large-scale graph-summary pair data with the assistance of LLMs, and introduce a novel graph-summary pretraining method, combined with invariant learning, to enhance graph foundation models with strong cross-domain zero-shot transferability. For few-shot learning, we propose a novel graph prompt tuning technique aligned with our pretraining objective to mitigate catastrophic forgetting and minimize learning costs. Extensive experiments show the superiority of GraphCLIP in both zero-shot and few-shot settings, while evaluations across various downstream tasks confirm the versatility of GraphCLIP. Our code is available at: https://github.com/ZhuYun97/GraphCLIP
Bridging Local Details and Global Context in Text-Attributed Graphs
Jun 18, 2024Representation learning on text-attributed graphs (TAGs) is vital for real-world applications, as they combine semantic textual and contextual structural information. Research in this field generally consist of two main perspectives: local-level encoding and global-level aggregating, respectively refer to textual node information unification (e.g., using Language Models) and structure-augmented modeling (e.g., using Graph Neural Networks). Most existing works focus on combining different information levels but overlook the interconnections, i.e., the contextual textual information among nodes, which provides semantic insights to bridge local and global levels. In this paper, we propose GraphBridge, a multi-granularity integration framework that bridges local and global perspectives by leveraging contextual textual information, enhancing fine-grained understanding of TAGs. Besides, to tackle scalability and efficiency challenges, we introduce a graphaware token reduction module. Extensive experiments across various models and datasets show that our method achieves state-of-theart performance, while our graph-aware token reduction module significantly enhances efficiency and solves scalability issues.
LASER: Tuning-Free LLM-Driven Attention Control for Efficient Text-conditioned Image-to-Animation
Apr 23, 2024Revolutionary advancements in text-to-image models have unlocked new dimensions for sophisticated content creation, e.g., text-conditioned image editing, allowing us to edit the diverse images that convey highly complex visual concepts according to the textual guidance. Despite being promising, existing methods focus on texture- or non-rigid-based visual manipulation, which struggles to produce the fine-grained animation of smooth text-conditioned image morphing without fine-tuning, i.e., due to their highly unstructured latent space. In this paper, we introduce a tuning-free LLM-driven attention control framework, encapsulated by the progressive process of LLM planning, prompt-Aware editing, StablE animation geneRation, abbreviated as LASER. LASER employs a large language model (LLM) to refine coarse descriptions into detailed prompts, guiding pre-trained text-to-image models for subsequent image generation. We manipulate the model's spatial features and self-attention mechanisms to maintain animation integrity and enable seamless morphing directly from text prompts, eliminating the need for additional fine-tuning or annotations. Our meticulous control over spatial features and self-attention ensures structural consistency in the images. This paper presents a novel framework integrating LLMs with text-to-image models to create high-quality animations from a single text input. We also propose a Text-conditioned Image-to-Animation Benchmark to validate the effectiveness and efficacy of LASER. Extensive experiments demonstrate that LASER produces impressive, consistent, and efficient results in animation generation, positioning it as a powerful tool for advanced digital content creation.
Efficient Tuning and Inference for Large Language Models on Textual Graphs
Jan 28, 2024


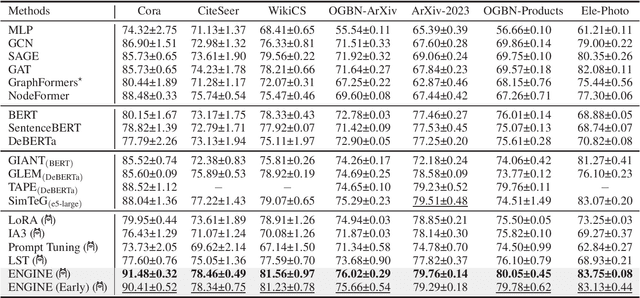
Rich textual and topological information of textual graphs need to be modeled in real-world applications such as webpages, e-commerce, and academic articles. Practitioners have been long following the path of adopting a shallow text encoder and a subsequent graph neural network (GNN) to solve this problem. In light of recent advancements in large language models (LLMs), it is apparent that integrating LLMs for enhanced textual encoding can substantially improve the performance of textual graphs. Nevertheless, the efficiency of these methods poses a significant challenge. In this paper, we propose ENGINE, a parameter- and memory-efficient fine-tuning method for textual graphs with an LLM encoder. The key insight is to combine the LLMs and GNNs through a tunable side structure, which significantly reduces the training complexity without impairing the joint model's capacity. Extensive experiments on textual graphs demonstrate our method's effectiveness by achieving the best model performance, meanwhile having the lowest training cost compared to previous methods. Moreover, we introduce two variants with caching and dynamic early exit to further enhance training and inference speed. Specifically, caching accelerates ENGINE's training by 12x, and dynamic early exit achieves up to 5x faster inference with a negligible performance drop (at maximum 1.17% relevant drop across 7 datasets).
GraphControl: Adding Conditional Control to Universal Graph Pre-trained Models for Graph Domain Transfer Learning
Oct 12, 2023


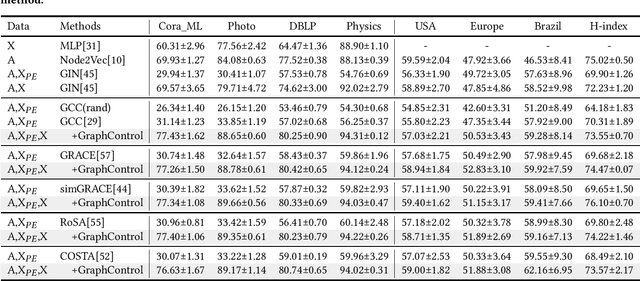
Graph-structured data is ubiquitous in the world which models complex relationships between objects, enabling various Web applications. Daily influxes of unlabeled graph data on the Web offer immense potential for these applications. Graph self-supervised algorithms have achieved significant success in acquiring generic knowledge from abundant unlabeled graph data. These pre-trained models can be applied to various downstream Web applications, saving training time and improving downstream (target) performance. However, different graphs, even across seemingly similar domains, can differ significantly in terms of attribute semantics, posing difficulties, if not infeasibility, for transferring the pre-trained models to downstream tasks. Concretely speaking, for example, the additional task-specific node information in downstream tasks (specificity) is usually deliberately omitted so that the pre-trained representation (transferability) can be leveraged. The trade-off as such is termed as "transferability-specificity dilemma" in this work. To address this challenge, we introduce an innovative deployment module coined as GraphControl, motivated by ControlNet, to realize better graph domain transfer learning. Specifically, by leveraging universal structural pre-trained models and GraphControl, we align the input space across various graphs and incorporate unique characteristics of target data as conditional inputs. These conditions will be progressively integrated into the model during fine-tuning or prompt tuning through ControlNet, facilitating personalized deployment. Extensive experiments show that our method significantly enhances the adaptability of pre-trained models on target attributed datasets, achieving 1.4-3x performance gain. Furthermore, it outperforms training-from-scratch methods on target data with a comparable margin and exhibits faster convergence.