 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Error-Guided Under-sampling Optimization for Multi-Contrast MRI Reconstruction
Jan 14, 2026Magnetic resonance imaging (MRI) plays a vital role in clinical diagnostics, yet it remains hindered by long acquisition times and motion artifacts. Multi-contrast MRI reconstruction has emerged as a promising direction by leveraging complementary information from fully-sampled reference scans. However, existing approaches suffer from three major limitations: (1) superficial reference fusion strategies, such as simple concatenation, (2) insufficient utilization of the complementary information provided by the reference contrast, and (3) fixed under-sampling patterns. We propose an efficient and interpretable frequency error-guided reconstruction framework to tackle these issues. We first employ a conditional diffusion model to learn a Frequency Error Prior (FEP), which is then incorporated into a unified framework for jointly optimizing both the under-sampling pattern and the reconstruction network. The proposed reconstruction model employs a model-driven deep unfolding framework that jointly exploits frequency- and image-domain information. In addition, a spatial alignment module and a reference feature decomposition strategy are incorporated to improve reconstruction quality and bridge model-based optimization with data-driven learning for improved physical interpretability. Comprehensive validation across multiple imaging modalities, acceleration rates (4-30x), and sampling schemes demonstrates consistent superiority over state-of-the-art methods in both quantitative metrics and visual quality. All codes are available at https://github.com/fangxinming/JUF-MRI.
CORE: Code-based Inverse Self-Training Framework with Graph Expansion for Virtual Agents
Jan 05, 2026The development of Multimodal Virtual Agents has made significant progress through the integration of Multimodal Large Language Models. However, mainstream training paradigms face key challenges: Behavior Cloning is simple and effective through imitation but suffers from low behavioral diversity, while Reinforcement Learning is capable of discovering novel strategies through exploration but heavily relies on manually designed reward functions. To address the conflict between these two methods, we present CORE, a Code-based Inverse Self-Training Framework with Graph Expansion that bridges imitation and exploration, offering a novel training framework that promotes behavioral diversity while eliminating the reliance on manually reward design. Specifically, we introduce Semantic Code Abstraction to automatically infers reward functions from expert demonstrations without manual design. The inferred reward function, referred to as the Label Function, is executable code that verifies one key step within a task. Building on this, we propose Strategy Graph Expansion to enhance in-domain behavioral diversity, which constructs a multi-path graph called Strategy Graph that captures diverse valid solutions beyond expert demonstrations. Furthermore, we introduce Trajectory-Guided Extrapolation, which enriches out-of-domain behavioral diversity by utilizing both successful and failed trajectories to expand the task space. Experiments on Web and Android platforms demonstrate that CORE significantly improves both overall performance and generalization, highlighting its potential as a robust and generalizable training paradigm for building powerful virtual agents.
OpenRT: An Open-Source Red Teaming Framework for Multimodal LLMs
Jan 04, 2026The rapid integration of Multimodal Large Language Models (MLLMs) into critical applications is increasingly hindered by persistent safety vulnerabilities. However, existing red-teaming benchmarks are often fragmented, limited to single-turn text interactions, and lack the scalability required for systematic evaluation. To address this, we introduce OpenRT, a unified, modular, and high-throughput red-teaming framework designed for comprehensive MLLM safety evaluation. At its core, OpenRT architects a paradigm shift in automated red-teaming by introducing an adversarial kernel that enables modular separation across five critical dimensions: model integration, dataset management, attack strategies, judging methods, and evaluation metrics. By standardizing attack interfaces, it decouples adversarial logic from a high-throughput asynchronous runtime, enabling systematic scaling across diverse models. Our framework integrates 37 diverse attack methodologies, spanning white-box gradients, multi-modal perturbations, and sophisticated multi-agent evolutionary strategies. Through an extensive empirical study on 20 advanced models (including GPT-5.2, Claude 4.5, and Gemini 3 Pro), we expose critical safety gaps: even frontier models fail to generalize across attack paradigms, with leading models exhibiting average Attack Success Rates as high as 49.14%. Notably, our findings reveal that reasoning models do not inherently possess superior robustness against complex, multi-turn jailbreaks. By open-sourcing OpenRT, we provide a sustainable, extensible, and continuously maintained infrastructure that accelerates the development and standardization of AI safety.
AnyMS: Bottom-up Attention Decoupling for Layout-guided and Training-free Multi-subject Customization
Dec 29, 2025Multi-subject customization aims to synthesize multiple user-specified subjects into a coherent image. To address issues such as subjects missing or conflicts, recent works incorporate layout guidance to provide explicit spatial constraints. However, existing methods still struggle to balance three critical objectives: text alignment, subject identity preservation, and layout control, while the reliance on additional training further limits their scalability and efficiency. In this paper, we present AnyMS, a novel training-free framework for layout-guided multi-subject customization. AnyMS leverages three input conditions: text prompt, subject images, and layout constraints, and introduces a bottom-up dual-level attention decoupling mechanism to harmonize their integration during generation. Specifically, global decoupling separates cross-attention between textual and visual conditions to ensure text alignment. Local decoupling confines each subject's attention to its designated area, which prevents subject conflicts and thus guarantees identity preservation and layout control. Moreover, AnyMS employs pre-trained image adapters to extract subject-specific features aligned with the diffusion model, removing the need for subject learning or adapter tuning. Extensive experiments demonstrate that AnyMS achieves state-of-the-art performance, supporting complex compositions and scaling to a larger number of subjects.
OmniMoGen: Unifying Human Motion Generation via Learning from Interleaved Text-Motion Instructions
Dec 22, 2025Large language models (LLMs) have unified diverse linguistic tasks within a single framework, yet such unification remains unexplored in human motion generation. Existing methods are confined to isolated tasks, limiting flexibility for free-form and omni-objective generation. To address this, we propose OmniMoGen, a unified framework that enables versatile motion generation through interleaved text-motion instructions. Built upon a concise RVQ-VAE and transformer architecture, OmniMoGen supports end-to-end instruction-driven motion generation. We construct X2Mo, a large-scale dataset of over 137K interleaved text-motion instructions, and introduce AnyContext, a benchmark for evaluating interleaved motion generation. Experiments show that OmniMoGen achieves state-of-the-art performance on text-to-motion, motion editing, and AnyContext, exhibiting emerging capabilities such as compositional editing, self-reflective generation, and knowledge-informed generation. These results mark a step toward the next intelligent motion generation. Project Page: https://OmniMoGen.github.io/.
Mamba-Based Modality Disentanglement Network for Multi-Contrast MRI Reconstruction
Dec 22, 2025Magnetic resonance imaging (MRI) is a cornerstone of modern clinical diagnosis, offering unparalleled soft-tissue contrast without ionizing radiation. However, prolonged scan times remain a major barrier to patient throughput and comfort. Existing accelerated MRI techniques often struggle with two key challenges: (1) failure to effectively utilize inherent K-space prior information, leading to persistent aliasing artifacts from zero-filled inputs; and (2) contamination of target reconstruction quality by irrelevant information when employing multi-contrast fusion strategies. To overcome these challenges, we present MambaMDN, a dual-domain framework for multi-contrast MRI reconstruction. Our approach first employs fully-sampled reference K-space data to complete the undersampled target data, generating structurally aligned but modality-mixed inputs. Subsequently, we develop a Mamba-based modality disentanglement network to extract and remove reference-specific features from the mixed representation. Furthermore, we introduce an iterative refinement mechanism to progressively enhance reconstruction accuracy through repeated feature purification. Extensive experiments demonstrate that MambaMDN can significantly outperform existing multi-contrast reconstruction methods.
VLNVerse: A Benchmark for Vision-Language Navigation with Versatile, Embodied, Realistic Simulation and Evaluation
Dec 22, 2025
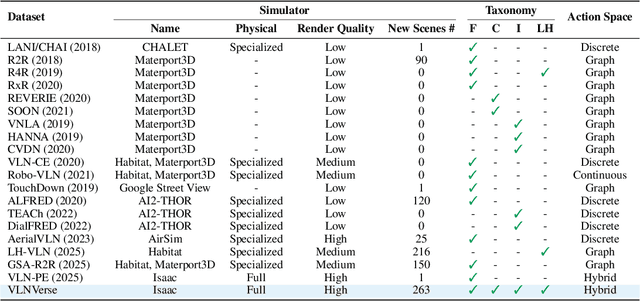
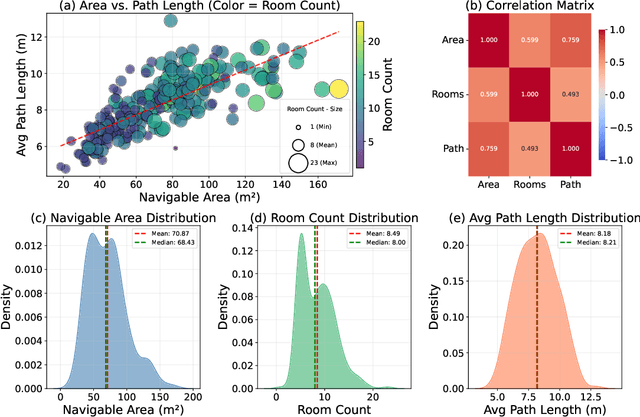

Despite remarkable progress in Vision-Language Navigation (VLN), existing benchmarks remain confined to fixed, small-scale datasets with naive physical simulation. These shortcomings limit the insight that the benchmarks provide into sim-to-real generalization, and create a significant research gap. Furthermore, task fragmentation prevents unified/shared progress in the area, while limited data scales fail to meet the demands of modern LLM-based pretraining. To overcome these limitations, we introduce VLNVerse: a new large-scale, extensible benchmark designed for Versatile, Embodied, Realistic Simulation, and Evaluation. VLNVerse redefines VLN as a scalable, full-stack embodied AI problem. Its Versatile nature unifies previously fragmented tasks into a single framework and provides an extensible toolkit for researchers. Its Embodied design moves beyond intangible and teleporting "ghost" agents that support full-kinematics in a Realistic Simulation powered by a robust physics engine. We leverage the scale and diversity of VLNVerse to conduct a comprehensive Evaluation of existing methods, from classic models to MLLM-based agents. We also propose a novel unified multi-task model capable of addressing all tasks within the benchmark. VLNVerse aims to narrow the gap between simulated navigation and real-world generalization, providing the community with a vital tool to boost research towards scalable, general-purpose embodied locomotion agents.
Evolve the Method, Not the Prompts: Evolutionary Synthesis of Jailbreak Attacks on LLMs
Nov 16, 2025Automated red teaming frameworks for Large Language Models (LLMs) have become increasingly sophisticated, yet they share a fundamental limitation: their jailbreak logic is confined to selecting, combining, or refining pre-existing attack strategies. This binds their creativity and leaves them unable to autonomously invent entirely new attack mechanisms. To overcome this gap, we introduce \textbf{EvoSynth}, an autonomous framework that shifts the paradigm from attack planning to the evolutionary synthesis of jailbreak methods. Instead of refining prompts, EvoSynth employs a multi-agent system to autonomously engineer, evolve, and execute novel, code-based attack algorithms. Crucially, it features a code-level self-correction loop, allowing it to iteratively rewrite its own attack logic in response to failure. Through extensive experiments, we demonstrate that EvoSynth not only establishes a new state-of-the-art by achieving an 85.5\% Attack Success Rate (ASR) against highly robust models like Claude-Sonnet-4.5, but also generates attacks that are significantly more diverse than those from existing methods. We release our framework to facilitate future research in this new direction of evolutionary synthesis of jailbreak methods. Code is available at: https://github.com/dongdongunique/EvoSynth.
WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
Nov 14, 2025
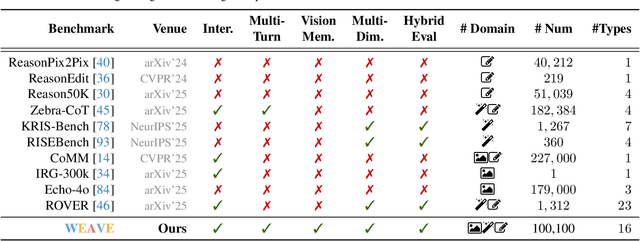
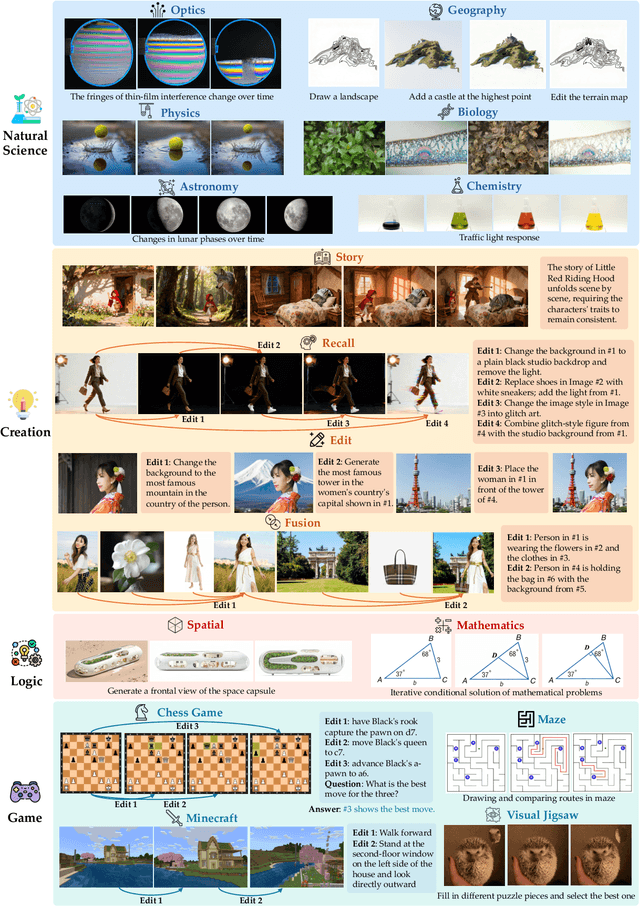

Recent advances in unified multimodal models (UMMs) have enabled impressive progress in visual comprehension and generation. However, existing datasets and benchmarks focus primarily on single-turn interactions, failing to capture the multi-turn, context-dependent nature of real-world image creation and editing. To address this gap, we present WEAVE, the first suite for in-context interleaved cross-modality comprehension and generation. Our suite consists of two complementary parts. WEAVE-100k is a large-scale dataset of 100K interleaved samples spanning over 370K dialogue turns and 500K images, covering comprehension, editing, and generation tasks that require reasoning over historical context. WEAVEBench is a human-annotated benchmark with 100 tasks based on 480 images, featuring a hybrid VLM judger evaluation framework based on both the reference image and the combination of the original image with editing instructions that assesses models' abilities in multi-turn generation, visual memory, and world-knowledge reasoning across diverse domains. Experiments demonstrate that training on WEAVE-100k enables vision comprehension, image editing, and comprehension-generation collaboration capabilities. Furthermore, it facilitates UMMs to develop emergent visual-memory capabilities, while extensive evaluations on WEAVEBench expose the persistent limitations and challenges of current approaches in multi-turn, context-aware image generation and editing. We believe WEAVE provides a view and foundation for studying in-context interleaved comprehension and generation for multi-modal community.
TAlignDiff: Automatic Tooth Alignment assisted by Diffusion-based Transformation Learning
Aug 06, 2025Orthodontic treatment hinges on tooth alignment, which significantly affects occlusal function, facial aesthetics, and patients' quality of life. Current deep learning approaches predominantly concentrate on predicting transformation matrices through imposing point-to-point geometric constraints for tooth alignment. Nevertheless, these matrices are likely associated with the anatomical structure of the human oral cavity and possess particular distribution characteristics that the deterministic point-to-point geometric constraints in prior work fail to capture. To address this, we introduce a new automatic tooth alignment method named TAlignDiff, which is supported by diffusion-based transformation learning. TAlignDiff comprises two main components: a primary point cloud-based regression network (PRN) and a diffusion-based transformation matrix denoising module (DTMD). Geometry-constrained losses supervise PRN learning for point cloud-level alignment. DTMD, as an auxiliary module, learns the latent distribution of transformation matrices from clinical data. We integrate point cloud-based transformation regression and diffusion-based transformation modeling into a unified framework, allowing bidirectional feedback between geometric constraints and diffusion refinement. Extensive ablation and comparative experiments demonstrate the effectiveness and superiority of our method, highlighting its potential in orthodontic treatment.