 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexRubric: A Rubric-Guided Diagnostic Benchmark for Open-Ended Legal Tasks
Jun 08, 2026As large language models (LLMs) are increasingly applied to real-world legal tasks, evaluating the reliability of their open-ended legal responses has become essential. These tasks require context-sensitive answers and allow little room for error, motivating fine-grained and diagnostic evaluation that can identify specific sources of response quality failures. We introduce LexRubric, a rubric-based benchmark for evaluating open-ended Chinese legal tasks. LexRubric contains 649 instances from legal consultation and judicial examination, which reflect both everyday legal needs and professional legal reasoning and cover 14 legal scenarios. It further includes 12,337 expert-written atomic scoring criteria organized under a unified six-dimensional framework, enabling accurate evaluation and diagnostic analysis across tasks and evaluation dimensions. To validate the reliability of the evaluation, we test multiple judge models and compare model-based judgments with human judgments. We further evaluate 18 recent general and legal-domain LLMs on LexRubric. Results show that different models exhibit distinct capability profiles, and that open-ended legal question remains challenging for current LLMs. Data is available at: https://github.com/foggpoy/LexRubric.
Search-Time Contamination in Deep Research Agents: Measuring Performance Inflation in Public Benchmark Evaluation
Jun 03, 2026Public benchmarks enable fair and reproducible evaluation of LLM reasoning, but they become fragile for deep research agents that actively search the web during inference. Such agents may retrieve public benchmark metadata, question context, or even ground-truth answers via web search. This gives rise to Search-Time Contamination (STC), where external retrieval bypasses intended reasoning and inflates measured performance. We systematically study STC in deep research agent evaluation. We define three contamination types with increasing severity, namely Benchmark Metadata Leakage, Question-Context Leakage, and Explicit Answer Leakage, and develop detection algorithms to identify them and quantify their impact on agent performance. Evaluating modern deep research agents on six public benchmarks, we find that STC is widespread and can inflate performance by up to 4%. Our findings show that existing evaluations may overestimate true reasoning ability. We therefore advocate contamination-aware practices, including isolated sandboxes, transparent search trajectories, and controlled benchmark access.
GridCodex: A RAG-Driven AI Framework for Power Grid Code Reasoning and Compliance
Aug 18, 2025



The global shift towards renewable energy presents unprecedented challenges for the electricity industry, making regulatory reasoning and compliance increasingly vital. Grid codes, the regulations governing grid operations, are complex and often lack automated interpretation solutions, which hinders industry expansion and undermines profitability for electricity companies. We introduce GridCodex, an end to end framework for grid code reasoning and compliance that leverages large language models and retrieval-augmented generation (RAG). Our framework advances conventional RAG workflows through multi stage query refinement and enhanced retrieval with RAPTOR. We validate the effectiveness of GridCodex with comprehensive benchmarks, including automated answer assessment across multiple dimensions and regulatory agencies. Experimental results showcase a 26.4% improvement in answer quality and more than a 10 fold increase in recall rate. An ablation study further examines the impact of base model selection.
LeCoDe: A Benchmark Dataset for Interactive Legal Consultation Dialogue Evaluation
May 26, 2025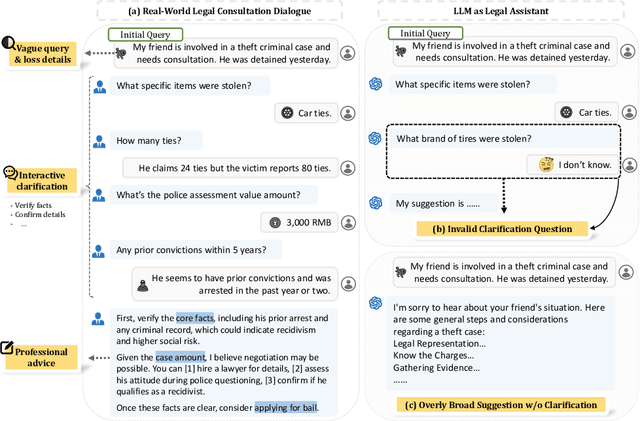


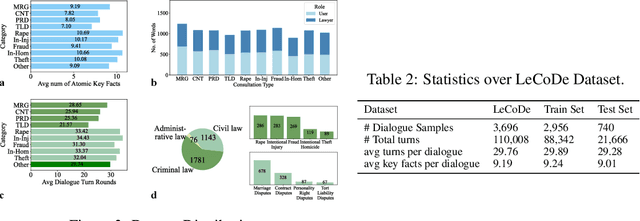
Legal consultation is essential for safeguarding individual rights and ensuring access to justice, yet remains costly and inaccessible to many individuals due to the shortage of professionals. While recent advances in Large Language Models (LLMs) offer a promising path toward scalable, low-cost legal assistance, current systems fall short in handling the interactive and knowledge-intensive nature of real-world consultations. To address these challenges, we introduce LeCoDe, a real-world multi-turn benchmark dataset comprising 3,696 legal consultation dialogues with 110,008 dialogue turns, designed to evaluate and improve LLMs' legal consultation capability. With LeCoDe, we innovatively collect live-streamed consultations from short-video platforms, providing authentic multi-turn legal consultation dialogues. The rigorous annotation by legal experts further enhances the dataset with professional insights and expertise. Furthermore, we propose a comprehensive evaluation framework that assesses LLMs' consultation capabilities in terms of (1) clarification capability and (2) professional advice quality. This unified framework incorporates 12 metrics across two dimensions. Through extensive experiments on various general and domain-specific LLMs, our results reveal significant challenges in this task, with even state-of-the-art models like GPT-4 achieving only 39.8% recall for clarification and 59% overall score for advice quality, highlighting the complexity of professional consultation scenarios. Based on these findings, we further explore several strategies to enhance LLMs' legal consultation abilities. Our benchmark contributes to advancing research in legal domain dialogue systems, particularly in simulating more real-world user-expert interactions.
Enable Lightweight and Precision-Scalable Posit/IEEE-754 Arithmetic in RISC-V Cores for Transprecision Computing
May 25, 2025While posit format offers superior dynamic range and accuracy for transprecision computing, its adoption in RISC-V processors is hindered by the lack of a unified solution for lightweight, precision-scalable, and IEEE-754 arithmetic compatible hardware implementation. To address these challenges, we enhance RISC-V processors by 1) integrating dedicated posit codecs into the original FPU for lightweight implementation, 2) incorporating multi/mixed-precision support with dynamic exponent size for precision-scalability, and 3) reusing and customizing ISA extensions for IEEE-754 compatible posit operations. Our comprehensive evaluation spans the modified FPU, RISC-V core, and SoC levels. It demonstrates that our implementation achieves 47.9% LUTs and 57.4% FFs reduction compared to state-of-the-art posit-enabled RISC-V processors, while achieving up to 2.54$\times$ throughput improvement in various GEMM kernels.
Towards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
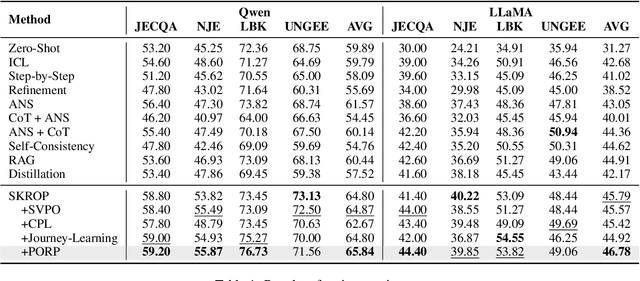
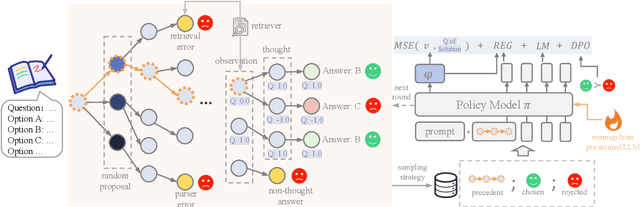
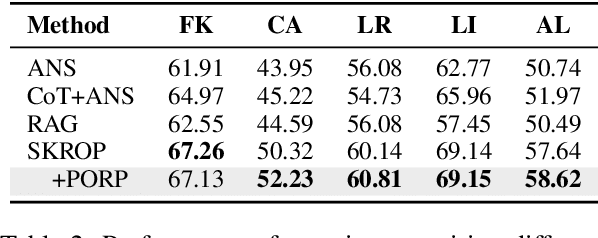
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
QuartDepth: Post-Training Quantization for Real-Time Depth Estimation on the Edge
Mar 20, 2025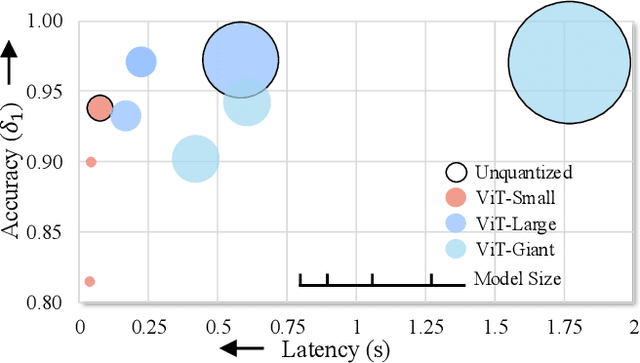
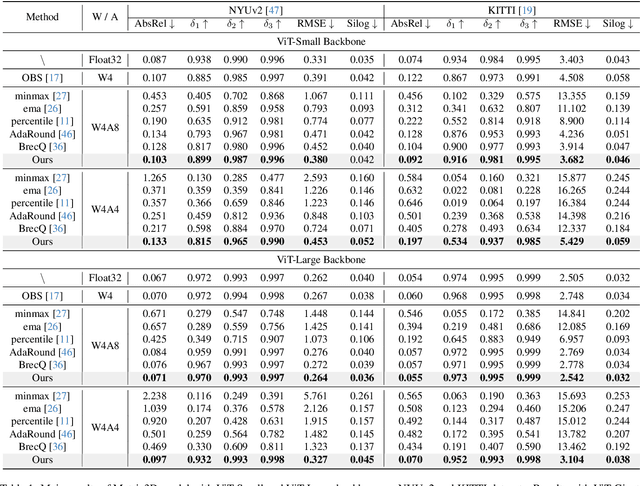
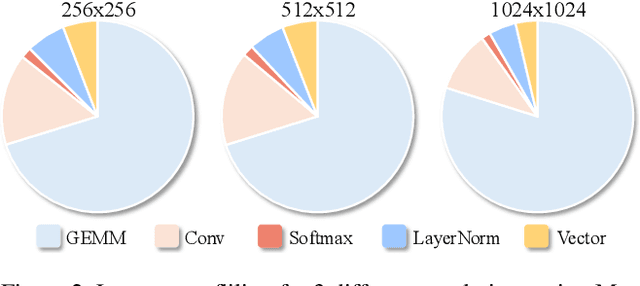
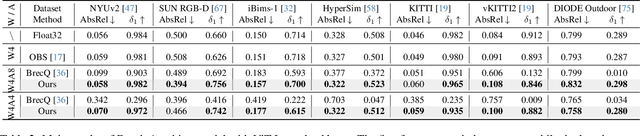
Monocular Depth Estimation (MDE) has emerged as a pivotal task in computer vision, supporting numerous real-world applications. However, deploying accurate depth estimation models on resource-limited edge devices, especially Application-Specific Integrated Circuits (ASICs), is challenging due to the high computational and memory demands. Recent advancements in foundational depth estimation deliver impressive results but further amplify the difficulty of deployment on ASICs. To address this, we propose QuartDepth which adopts post-training quantization to quantize MDE models with hardware accelerations for ASICs. Our approach involves quantizing both weights and activations to 4-bit precision, reducing the model size and computation cost. To mitigate the performance degradation, we introduce activation polishing and compensation algorithm applied before and after activation quantization, as well as a weight reconstruction method for minimizing errors in weight quantization. Furthermore, we design a flexible and programmable hardware accelerator by supporting kernel fusion and customized instruction programmability, enhancing throughput and efficiency. Experimental results demonstrate that our framework achieves competitive accuracy while enabling fast inference and higher energy efficiency on ASICs, bridging the gap between high-performance depth estimation and practical edge-device applicability. Code: https://github.com/shawnricecake/quart-depth
Chart-HQA: A Benchmark for Hypothetical Question Answering in Charts
Mar 07, 2025Multimodal Large Language Models (MLLMs) have garnered significant attention for their strong visual-semantic understanding. Most existing chart benchmarks evaluate MLLMs' ability to parse information from charts to answer questions. However, they overlook the inherent output biases of MLLMs, where models rely on their parametric memory to answer questions rather than genuinely understanding the chart content. To address this limitation, we introduce a novel Chart Hypothetical Question Answering (HQA) task, which imposes assumptions on the same question to compel models to engage in counterfactual reasoning based on the chart content. Furthermore, we introduce HAI, a human-AI interactive data synthesis approach that leverages the efficient text-editing capabilities of LLMs alongside human expert knowledge to generate diverse and high-quality HQA data at a low cost. Using HAI, we construct Chart-HQA, a challenging benchmark synthesized from publicly available data sources. Evaluation results on 18 MLLMs of varying model sizes reveal that current models face significant generalization challenges and exhibit imbalanced reasoning performance on the HQA task.
PreAdaptFWI: Pretrained-Based Adaptive Residual Learning for Full-Waveform Inversion Without Dataset Dependency
Feb 17, 2025Full-waveform inversion (FWI) is a method that utilizes seismic data to invert the physical parameters of subsurface media by minimizing the difference between simulated and observed waveforms. Due to its ill-posed nature, FWI is susceptible to getting trapped in local minima. Consequently, various research efforts have attempted to combine neural networks with FWI to stabilize the inversion process. This study presents a simple yet effective training framework that is independent of dataset reliance and requires only moderate pre-training on a simple initial model to stabilize network outputs. During the transfer learning phase, the conventional FWI gradients will simultaneously update both the neural network and the proposed adaptive residual learning module, which learns the residual mapping of large-scale distribution features in the network's output, rather than directly fitting the target mapping. Through this synergistic training paradigm, the proposed algorithm effectively infers the physically-informed prior knowledge into a global representation of stratigraphic distribution, as well as capturing subtle variations in inter-layer velocities within local details, thereby escaping local optima. Evaluating the method on two benchmark models under various conditions, including absent low-frequency data, noise interference, and differing initial models, along with corresponding ablation experiments, consistently demonstrates the superiority of the proposed approach.
Learning to Solve Domain-Specific Calculation Problems with Knowledge-Intensive Programs Generator
Dec 12, 2024Domain Large Language Models (LLMs) are developed for domain-specific tasks based on general LLMs. But it still requires professional knowledge to facilitate the expertise for some domain-specific tasks. In this paper, we investigate into knowledge-intensive calculation problems. We find that the math problems to be challenging for LLMs, when involving complex domain-specific rules and knowledge documents, rather than simple formulations of terminologies. Therefore, we propose a pipeline to solve the domain-specific calculation problems with Knowledge-Intensive Programs Generator more effectively, named as KIPG. It generates knowledge-intensive programs according to the domain-specific documents. For each query, key variables are extracted, then outcomes which are dependent on domain knowledge are calculated with the programs. By iterative preference alignment, the code generator learns to improve the logic consistency with the domain knowledge. Taking legal domain as an example, we have conducted experiments to prove the effectiveness of our pipeline, and extensive analysis on the modules. We also find that the code generator is also adaptable to other domains, without training on the new knowledge.