 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDI-Bench: A Benchmark for General Document Intelligence with Vision and Reasoning Decoupling
Apr 30, 2025The rapid advancement of multimodal large language models (MLLMs) has profoundly impacted the document domain, creating a wide array of application scenarios. This progress highlights the need for a comprehensive benchmark to evaluate these models' capabilities across various document-specific tasks. However, existing benchmarks often fail to locate specific model weaknesses or guide systematic improvements. To bridge this gap, we introduce a General Document Intelligence Benchmark (GDI-Bench), featuring 1.9k images across 9 key scenarios and 19 document-specific tasks. By decoupling visual complexity and reasoning complexity, the GDI-Bench structures graded tasks that allow performance assessment by difficulty, aiding in model weakness identification and optimization guidance. We evaluate the GDI-Bench on various open-source and closed-source models, conducting decoupled analyses in the visual and reasoning domains. For instance, the GPT-4o model excels in reasoning tasks but exhibits limitations in visual capabilities. To address the diverse tasks and domains in the GDI-Bench, we propose a GDI Model that mitigates the issue of catastrophic forgetting during the supervised fine-tuning (SFT) process through a intelligence-preserving training strategy. Our model achieves state-of-the-art performance on previous benchmarks and the GDI-Bench. Both our benchmark and model will be open source.
Chart-HQA: A Benchmark for Hypothetical Question Answering in Charts
Mar 07, 2025Multimodal Large Language Models (MLLMs) have garnered significant attention for their strong visual-semantic understanding. Most existing chart benchmarks evaluate MLLMs' ability to parse information from charts to answer questions. However, they overlook the inherent output biases of MLLMs, where models rely on their parametric memory to answer questions rather than genuinely understanding the chart content. To address this limitation, we introduce a novel Chart Hypothetical Question Answering (HQA) task, which imposes assumptions on the same question to compel models to engage in counterfactual reasoning based on the chart content. Furthermore, we introduce HAI, a human-AI interactive data synthesis approach that leverages the efficient text-editing capabilities of LLMs alongside human expert knowledge to generate diverse and high-quality HQA data at a low cost. Using HAI, we construct Chart-HQA, a challenging benchmark synthesized from publicly available data sources. Evaluation results on 18 MLLMs of varying model sizes reveal that current models face significant generalization challenges and exhibit imbalanced reasoning performance on the HQA task.
Negative Sampling with Adaptive Denoising Mixup for Knowledge Graph Embedding
Oct 15, 2023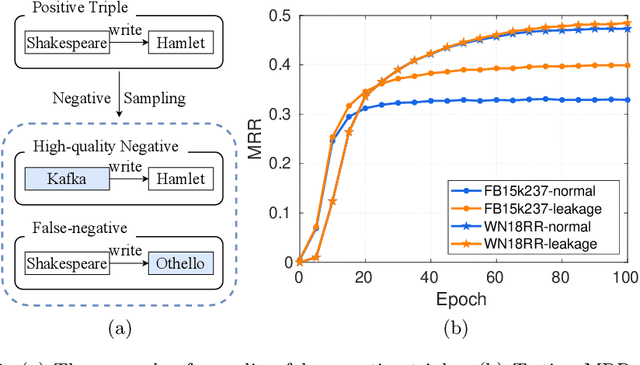

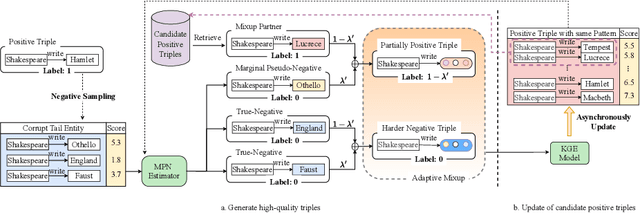
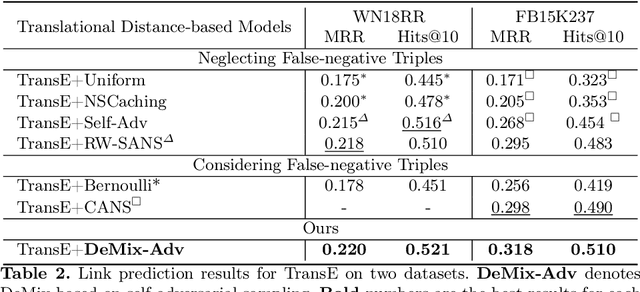
Knowledge graph embedding (KGE) aims to map entities and relations of a knowledge graph (KG) into a low-dimensional and dense vector space via contrasting the positive and negative triples. In the training process of KGEs, negative sampling is essential to find high-quality negative triples since KGs only contain positive triples. Most existing negative sampling methods assume that non-existent triples with high scores are high-quality negative triples. However, negative triples sampled by these methods are likely to contain noise. Specifically, they ignore that non-existent triples with high scores might also be true facts due to the incompleteness of KGs, which are usually called false negative triples. To alleviate the above issue, we propose an easily pluggable denoising mixup method called DeMix, which generates high-quality triples by refining sampled negative triples in a self-supervised manner. Given a sampled unlabeled triple, DeMix firstly classifies it into a marginal pseudo-negative triple or a negative triple based on the judgment of the KGE model itself. Secondly, it selects an appropriate mixup partner for the current triple to synthesize a partially positive or a harder negative triple. Experimental results on the knowledge graph completion task show that the proposed DeMix is superior to other negative sampling techniques, ensuring corresponding KGEs a faster convergence and better link prediction results.
Global Structure Knowledge-Guided Relation Extraction Method for Visually-Rich Document
May 23, 2023Visual relation extraction (VRE) aims to extract relations between entities from visuallyrich documents. Existing methods usually predict relations for each entity pair independently based on entity features but ignore the global structure information, i.e., dependencies between entity pairs. The absence of global structure information may make the model struggle to learn long-range relations and easily predict conflicted results. To alleviate such limitations, we propose a GlObal Structure knowledgeguided relation Extraction (GOSE) framework, which captures dependencies between entity pairs in an iterative manner. Given a scanned image of the document, GOSE firstly generates preliminary relation predictions on entity pairs. Secondly, it mines global structure knowledge based on prediction results of the previous iteration and further incorporates global structure knowledge into entity representations. This "generate-capture-incorporate" schema is performed multiple times so that entity representations and global structure knowledge can mutually reinforce each other. Extensive experiments show that GOSE not only outperforms previous methods on the standard fine-tuning setting but also shows promising superiority in cross-lingual learning; even yields stronger data-efficient performance in the low-resource setting.
Meta-Learning Based Knowledge Extrapolation for Knowledge Graphs in the Federated Setting
May 10, 2022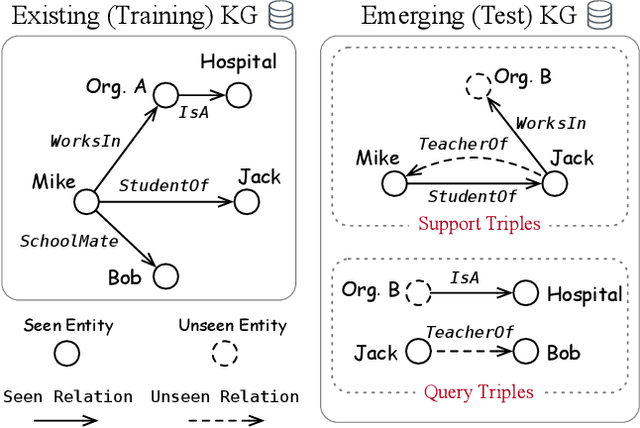
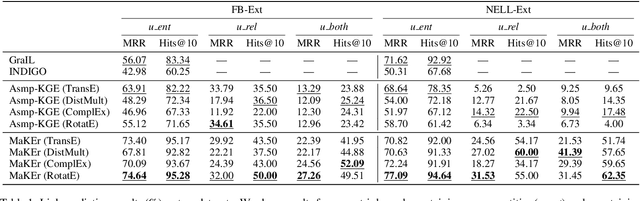
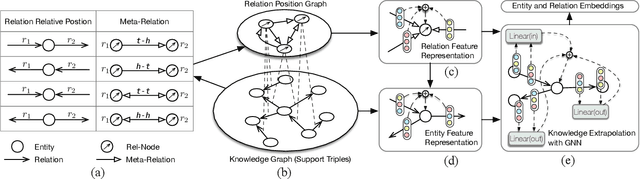

We study the knowledge extrapolation problem to embed new components (i.e., entities and relations) that come with emerging knowledge graphs (KGs) in the federated setting. In this problem, a model trained on an existing KG needs to embed an emerging KG with unseen entities and relations. To solve this problem, we introduce the meta-learning setting, where a set of tasks are sampled on the existing KG to mimic the link prediction task on the emerging KG. Based on sampled tasks, we meta-train a graph neural network framework that can construct features for unseen components based on structural information and output embeddings for them. Experimental results show that our proposed method can effectively embed unseen components and outperforms models that consider inductive settings for KGs and baselines that directly use conventional KG embedding methods.
NeuralKG: An Open Source Library for Diverse Representation Learning of Knowledge Graphs
Feb 25, 2022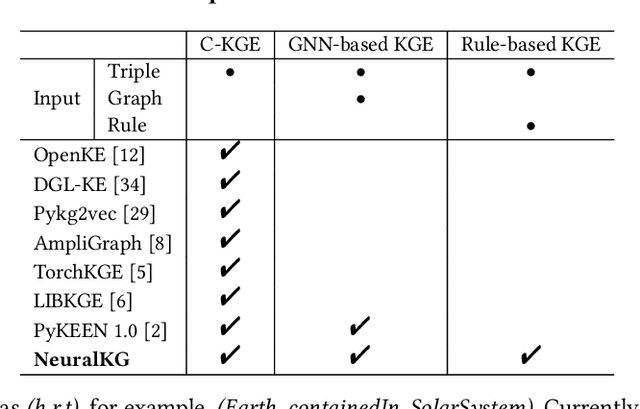
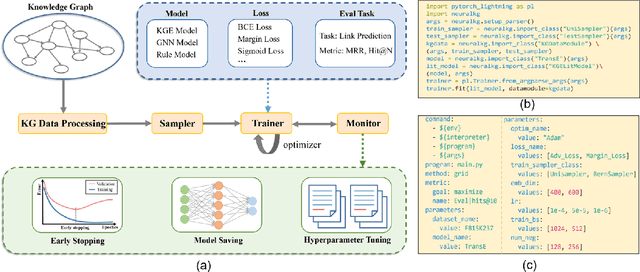
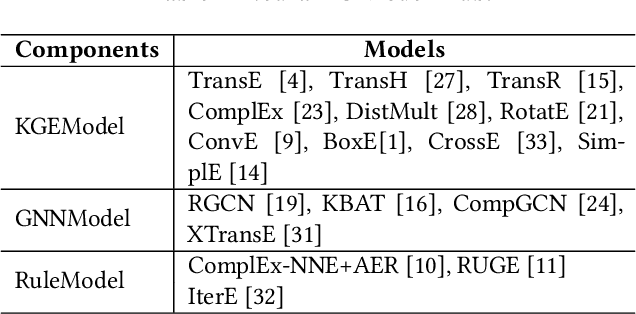
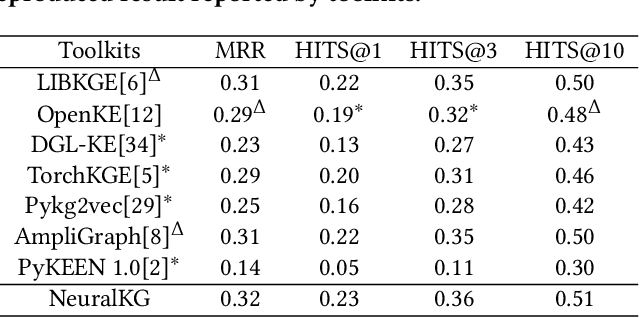
NeuralKG is an open-source Python-based library for diverse representation learning of knowledge graphs. It implements three different series of Knowledge Graph Embedding (KGE) methods, including conventional KGEs, GNN-based KGEs, and Rule-based KGEs. With a unified framework, NeuralKG successfully reproduces link prediction results of these methods on benchmarks, freeing users from the laborious task of reimplementing them, especially for some methods originally written in non-python programming languages. Besides, NeuralKG is highly configurable and extensible. It provides various decoupled modules that can be mixed and adapted to each other. Thus with NeuralKG, developers and researchers can quickly implement their own designed models and obtain the optimal training methods to achieve the best performance efficiently. We built an website in http://neuralkg.zjukg.cn to organize an open and shared KG representation learning community. The source code is all publicly released at https://github.com/zjukg/NeuralKG.
ZJUKLAB at SemEval-2021 Task 4: Negative Augmentation with Language Model for Reading Comprehension of Abstract Meaning
Feb 25, 2021
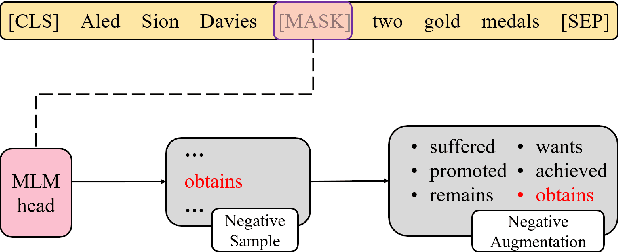

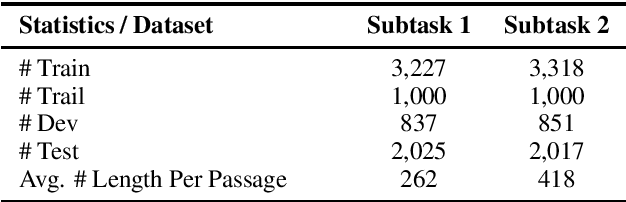
This paper presents our systems for the three Subtasks of SemEval Task4: Reading Comprehension of Abstract Meaning (ReCAM). We explain the algorithms used to learn our models and the process of tuning the algorithms and selecting the best model. Inspired by the similarity of the ReCAM task and the language pre-training, we propose a simple yet effective technology, namely, negative augmentation with language model. Evaluation results demonstrate the effectiveness of our proposed approach. Our models achieve the 4th rank on both official test sets of Subtask 1 and Subtask 2 with an accuracy of 87.9% and an accuracy of 92.8%, respectively. We further conduct comprehensive model analysis and observe interesting error cases, which may promote future researches.