 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Apr 20, 2026Large language models are increasingly expected to serve as general-purpose agents that interact with external, stateful tool environments. The Model Context Protocol (MCP) and broader agent skills offer a unified interface for connecting agents with scalable real-world services, but training robust agents remains limited by the lack of realistic environments and principled mechanisms for life-long learning. In this paper, we present \textbf{Agent-World}, a self-evolving training arena for advancing general agent intelligence through scalable environments. Agent-World has two main components: (1) Agentic Environment-Task Discovery, which autonomously explores topic-aligned databases and executable tool ecosystems from thousands of real-world environment themes and synthesizes verifiable tasks with controllable difficulty; and (2) Continuous Self-Evolving Agent Training, which combines multi-environment reinforcement learning with a self-evolving agent arena that automatically identifies capability gaps through dynamic task synthesis and drives targeted learning, enabling the co-evolution of agent policies and environments. Across 23 challenging agent benchmarks, Agent-World-8B and 14B consistently outperforms strong proprietary models and environment scaling baselines. Further analyses reveal scaling trends in relation to environment diversity and self-evolution rounds, offering insights for building general agent intelligence.
FailureAtlas:Mapping the Failure Landscape of T2I Models via Active Exploration
Sep 26, 2025Static benchmarks have provided a valuable foundation for comparing Text-to-Image (T2I) models. However, their passive design offers limited diagnostic power, struggling to uncover the full landscape of systematic failures or isolate their root causes. We argue for a complementary paradigm: active exploration. We introduce FailureAtlas, the first framework designed to autonomously explore and map the vast failure landscape of T2I models at scale. FailureAtlas frames error discovery as a structured search for minimal, failure-inducing concepts. While it is a computationally explosive problem, we make it tractable with novel acceleration techniques. When applied to Stable Diffusion models, our method uncovers hundreds of thousands of previously unknown error slices (over 247,000 in SD1.5 alone) and provides the first large-scale evidence linking these failures to data scarcity in the training set. By providing a principled and scalable engine for deep model auditing, FailureAtlas establishes a new, diagnostic-first methodology to guide the development of more robust generative AI. The code is available at https://github.com/cure-lab/FailureAtlas
Beyond Completion: A Foundation Model for General Knowledge Graph Reasoning
May 28, 2025In natural language processing (NLP) and computer vision (CV), the successful application of foundation models across diverse tasks has demonstrated their remarkable potential. However, despite the rich structural and textual information embedded in knowledge graphs (KGs), existing research of foundation model for KG has primarily focused on their structural aspects, with most efforts restricted to in-KG tasks (e.g., knowledge graph completion, KGC). This limitation has hindered progress in addressing more challenging out-of-KG tasks. In this paper, we introduce MERRY, a foundation model for general knowledge graph reasoning, and investigate its performance across two task categories: in-KG reasoning tasks (e.g., KGC) and out-of-KG tasks (e.g., KG question answering, KGQA). We not only utilize the structural information, but also the textual information in KGs. Specifically, we propose a multi-perspective Conditional Message Passing (CMP) encoding architecture to bridge the gap between textual and structural modalities, enabling their seamless integration. Additionally, we introduce a dynamic residual fusion module to selectively retain relevant textual information and a flexible edge scoring mechanism to adapt to diverse downstream tasks. Comprehensive evaluations on 28 datasets demonstrate that MERRY outperforms existing baselines in most scenarios, showcasing strong reasoning capabilities within KGs and excellent generalization to out-of-KG tasks such as KGQA.
GenSwarm: Scalable Multi-Robot Code-Policy Generation and Deployment via Language Models
Mar 31, 2025The development of control policies for multi-robot systems traditionally follows a complex and labor-intensive process, often lacking the flexibility to adapt to dynamic tasks. This has motivated research on methods to automatically create control policies. However, these methods require iterative processes of manually crafting and refining objective functions, thereby prolonging the development cycle. This work introduces \textit{GenSwarm}, an end-to-end system that leverages large language models to automatically generate and deploy control policies for multi-robot tasks based on simple user instructions in natural language. As a multi-language-agent system, GenSwarm achieves zero-shot learning, enabling rapid adaptation to altered or unseen tasks. The white-box nature of the code policies ensures strong reproducibility and interpretability. With its scalable software and hardware architectures, GenSwarm supports efficient policy deployment on both simulated and real-world multi-robot systems, realizing an instruction-to-execution end-to-end functionality that could prove valuable for robotics specialists and non-specialists alike.The code of the proposed GenSwarm system is available online: https://github.com/WindyLab/GenSwarm.
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Mar 27, 2025



Large Language Models (LLMs) have shown remarkable capabilities in reasoning, exemplified by the success of OpenAI-o1 and DeepSeek-R1. However, integrating reasoning with external search processes remains challenging, especially for complex multi-hop questions requiring multiple retrieval steps. We propose ReSearch, a novel framework that trains LLMs to Reason with Search via reinforcement learning without using any supervised data on reasoning steps. Our approach treats search operations as integral components of the reasoning chain, where when and how to perform searches is guided by text-based thinking, and search results subsequently influence further reasoning. We train ReSearch on Qwen2.5-7B(-Instruct) and Qwen2.5-32B(-Instruct) models and conduct extensive experiments. Despite being trained on only one dataset, our models demonstrate strong generalizability across various benchmarks. Analysis reveals that ReSearch naturally elicits advanced reasoning capabilities such as reflection and self-correction during the reinforcement learning process.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Interpretable deep learning illuminates multiple structures fluorescence imaging: a path toward trustworthy artificial intelligence in microscopy
Jan 09, 2025Live-cell imaging of multiple subcellular structures is essential for understanding subcellular dynamics. However, the conventional multi-color sequential fluorescence microscopy suffers from significant imaging delays and limited number of subcellular structure separate labeling, resulting in substantial limitations for real-time live-cell research applications. Here, we present the Adaptive Explainable Multi-Structure Network (AEMS-Net), a deep-learning framework that enables simultaneous prediction of two subcellular structures from a single image. The model normalizes staining intensity and prioritizes critical image features by integrating attention mechanisms and brightness adaptation layers. Leveraging the Kolmogorov-Arnold representation theorem, our model decomposes learned features into interpretable univariate functions, enhancing the explainability of complex subcellular morphologies. We demonstrate that AEMS-Net allows real-time recording of interactions between mitochondria and microtubules, requiring only half the conventional sequential-channel imaging procedures. Notably, this approach achieves over 30% improvement in imaging quality compared to traditional deep learning methods, establishing a new paradigm for long-term, interpretable live-cell imaging that advances the ability to explore subcellular dynamics.
Deblur4DGS: 4D Gaussian Splatting from Blurry Monocular Video
Dec 09, 2024



Recent 4D reconstruction methods have yielded impressive results but rely on sharp videos as supervision. However, motion blur often occurs in videos due to camera shake and object movement, while existing methods render blurry results when using such videos for reconstructing 4D models. Although a few NeRF-based approaches attempted to address the problem, they struggled to produce high-quality results, due to the inaccuracy in estimating continuous dynamic representations within the exposure time. Encouraged by recent works in 3D motion trajectory modeling using 3D Gaussian Splatting (3DGS), we suggest taking 3DGS as the scene representation manner, and propose the first 4D Gaussian Splatting framework to reconstruct a high-quality 4D model from blurry monocular video, named Deblur4DGS. Specifically, we transform continuous dynamic representations estimation within an exposure time into the exposure time estimation. Moreover, we introduce exposure regularization to avoid trivial solutions, as well as multi-frame and multi-resolution consistency ones to alleviate artifacts. Furthermore, to better represent objects with large motion, we suggest blur-aware variable canonical Gaussians. Beyond novel-view synthesis, Deblur4DGS can be applied to improve blurry video from multiple perspectives, including deblurring, frame interpolation, and video stabilization. Extensive experiments on the above four tasks show that Deblur4DGS outperforms state-of-the-art 4D reconstruction methods. The codes are available at https://github.com/ZcsrenlongZ/Deblur4DGS.
UniHR: Hierarchical Representation Learning for Unified Knowledge Graph Link Prediction
Nov 11, 2024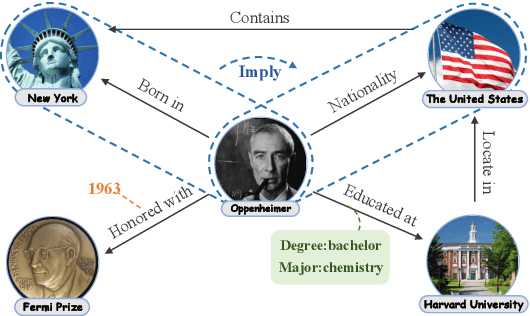
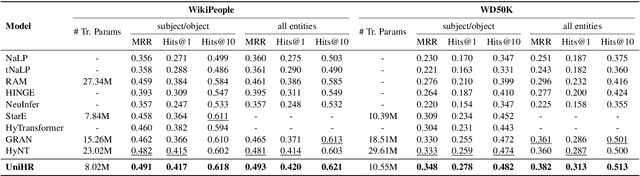
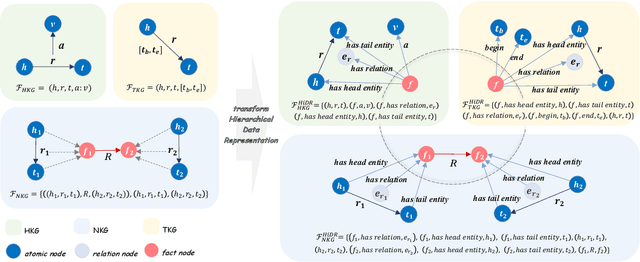
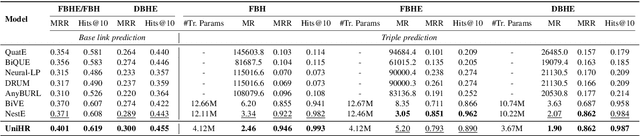
Beyond-triple fact representations including hyper-relational facts with auxiliary key-value pairs, temporal facts with additional timestamps, and nested facts implying relationships between facts, are gaining significant attention. However, existing link prediction models are usually designed for one specific type of facts, making it difficult to generalize to other fact representations. To overcome this limitation, we propose a Unified Hierarchical Representation learning framework (UniHR) for unified knowledge graph link prediction. It consists of a unified Hierarchical Data Representation (HiDR) module and a unified Hierarchical Structure Learning (HiSL) module as graph encoder. The HiDR module unifies hyper-relational KGs, temporal KGs, and nested factual KGs into triple-based representations. Then HiSL incorporates intra-fact and inter-fact message passing, focusing on enhancing the semantic information within individual facts and enriching the structural information between facts. Experimental results across 7 datasets from 3 types of KGs demonstrate that our UniHR outperforms baselines designed for one specific kind of KG, indicating strong generalization capability of HiDR form and the effectiveness of HiSL module. Code and data are available at https://github.com/Lza12a/UniHR.
DisenGCD: A Meta Multigraph-assisted Disentangled Graph Learning Framework for Cognitive Diagnosis
Oct 23, 2024



Existing graph learning-based cognitive diagnosis (CD) methods have made relatively good results, but their student, exercise, and concept representations are learned and exchanged in an implicit unified graph, which makes the interaction-agnostic exercise and concept representations be learned poorly, failing to provide high robustness against noise in students' interactions. Besides, lower-order exercise latent representations obtained in shallow layers are not well explored when learning the student representation. To tackle the issues, this paper suggests a meta multigraph-assisted disentangled graph learning framework for CD (DisenGCD), which learns three types of representations on three disentangled graphs: student-exercise-concept interaction, exercise-concept relation, and concept dependency graphs, respectively. Specifically, the latter two graphs are first disentangled from the interaction graph. Then, the student representation is learned from the interaction graph by a devised meta multigraph learning module; multiple learnable propagation paths in this module enable current student latent representation to access lower-order exercise latent representations, which can lead to more effective nad robust student representations learned; the exercise and concept representations are learned on the relation and dependency graphs by graph attention modules. Finally, a novel diagnostic function is devised to handle three disentangled representations for prediction. Experiments show better performance and robustness of DisenGCD than state-of-the-art CD methods and demonstrate the effectiveness of the disentangled learning framework and meta multigraph module. The source code is available at \textcolor{red}{\url{https://github.com/BIMK/Intelligent-Education/tree/main/DisenGCD}}.