 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Efficient Any Transformer-to-Mamba Distillation via Attention Bridge
Oct 22, 2025State-space models (SSMs) have emerged as efficient alternatives to Transformers for sequence modeling, offering superior scalability through recurrent structures. However, their training remains costly and the ecosystem around them is far less mature than that of Transformers. Moreover, the structural heterogeneity between SSMs and Transformers makes it challenging to efficiently distill knowledge from pretrained attention models. In this work, we propose Cross-architecture distillation via Attention Bridge (CAB), a novel data-efficient distillation framework that efficiently transfers attention knowledge from Transformer teachers to state-space student models. Unlike conventional knowledge distillation that transfers knowledge only at the output level, CAB enables token-level supervision via a lightweight bridge and flexible layer-wise alignment, improving both efficiency and transferability. We further introduce flexible layer-wise alignment strategies to accommodate architectural discrepancies between teacher and student. Extensive experiments across vision and language domains demonstrate that our method consistently improves the performance of state-space models, even under limited training data, outperforming both standard and cross-architecture distillation methods. Our findings suggest that attention-based knowledge can be efficiently transferred to recurrent models, enabling rapid utilization of Transformer expertise for building a stronger SSM community.
DisenGCD: A Meta Multigraph-assisted Disentangled Graph Learning Framework for Cognitive Diagnosis
Oct 23, 2024



Existing graph learning-based cognitive diagnosis (CD) methods have made relatively good results, but their student, exercise, and concept representations are learned and exchanged in an implicit unified graph, which makes the interaction-agnostic exercise and concept representations be learned poorly, failing to provide high robustness against noise in students' interactions. Besides, lower-order exercise latent representations obtained in shallow layers are not well explored when learning the student representation. To tackle the issues, this paper suggests a meta multigraph-assisted disentangled graph learning framework for CD (DisenGCD), which learns three types of representations on three disentangled graphs: student-exercise-concept interaction, exercise-concept relation, and concept dependency graphs, respectively. Specifically, the latter two graphs are first disentangled from the interaction graph. Then, the student representation is learned from the interaction graph by a devised meta multigraph learning module; multiple learnable propagation paths in this module enable current student latent representation to access lower-order exercise latent representations, which can lead to more effective nad robust student representations learned; the exercise and concept representations are learned on the relation and dependency graphs by graph attention modules. Finally, a novel diagnostic function is devised to handle three disentangled representations for prediction. Experiments show better performance and robustness of DisenGCD than state-of-the-art CD methods and demonstrate the effectiveness of the disentangled learning framework and meta multigraph module. The source code is available at \textcolor{red}{\url{https://github.com/BIMK/Intelligent-Education/tree/main/DisenGCD}}.
Boosting Unsupervised Contrastive Learning Using Diffusion-Based Data Augmentation From Scratch
Sep 10, 2023Unsupervised contrastive learning methods have recently seen significant improvements, particularly through data augmentation strategies that aim to produce robust and generalizable representations. However, prevailing data augmentation methods, whether hand designed or based on foundation models, tend to rely heavily on prior knowledge or external data. This dependence often compromises their effectiveness and efficiency. Furthermore, the applicability of most existing data augmentation strategies is limited when transitioning to other research domains, especially science-related data. This limitation stems from the paucity of prior knowledge and labeled data available in these domains. To address these challenges, we introduce DiffAug-a novel and efficient Diffusion-based data Augmentation technique. DiffAug aims to ensure that the augmented and original data share a smoothed latent space, which is achieved through diffusion steps. Uniquely, unlike traditional methods, DiffAug first mines sufficient prior semantic knowledge about the neighborhood. This provides a constraint to guide the diffusion steps, eliminating the need for labels, external data/models, or prior knowledge. Designed as an architecture-agnostic framework, DiffAug provides consistent improvements. Specifically, it improves image classification and clustering accuracy by 1.6%~4.5%. When applied to biological data, DiffAug improves performance by up to 10.1%, with an average improvement of 5.8%. DiffAug shows good performance in both vision and biological domains.
Multi-hierarchical Convolutional Network for Efficient Remote Photoplethysmograph Signal and Heart Rate Estimation from Face Video Clips
Apr 06, 2021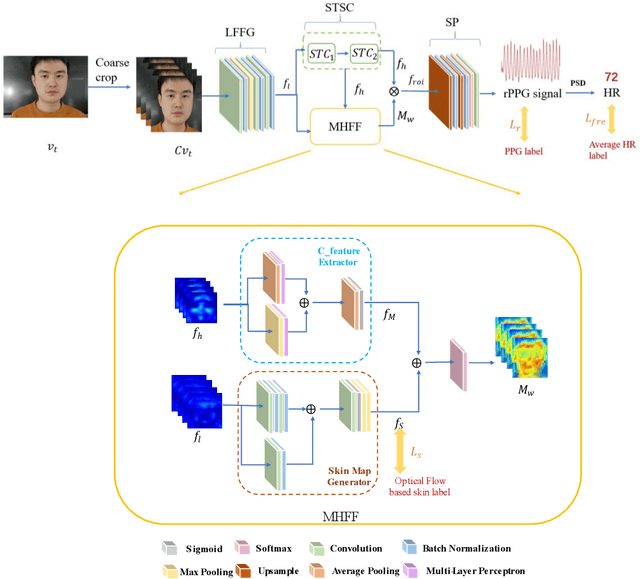
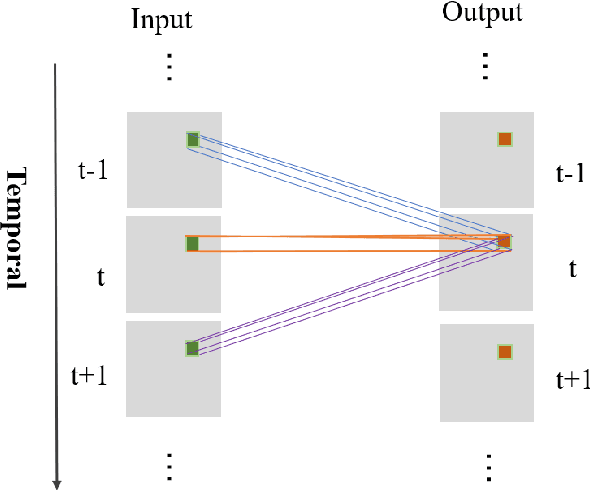
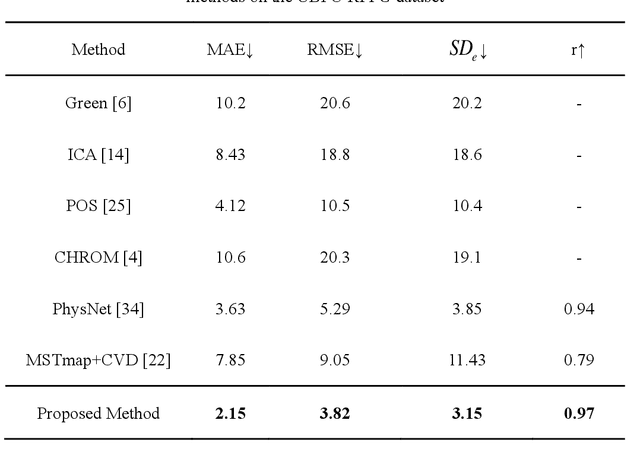
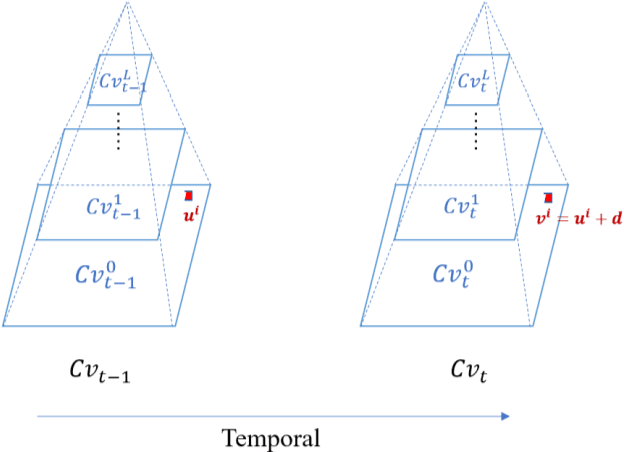
Heart beat rhythm and heart rate (HR) are important physiological parameters of the human body. This study presents an efficient multi-hierarchical spatio-temporal convolutional network that can quickly estimate remote physiological (rPPG) signal and HR from face video clips. First, the facial color distribution characteristics are extracted using a low-level face feature Generation (LFFG) module. Then, the three-dimensional (3D) spatio-temporal stack convolution module (STSC) and multi-hierarchical feature fusion module (MHFF) are used to strengthen the spatio-temporal correlation of multi-channel features. In the MHFF, sparse optical flow is used to capture the tiny motion information of faces between frames and generate a self-adaptive region of interest (ROI) skin mask. Finally, the signal prediction module (SP) is used to extract the estimated rPPG signal. The experimental results on the three datasets show that the proposed network outperforms the state-of-the-art methods.
A Unified Model for Recommendation with Selective Neighborhood Modeling
Oct 19, 2020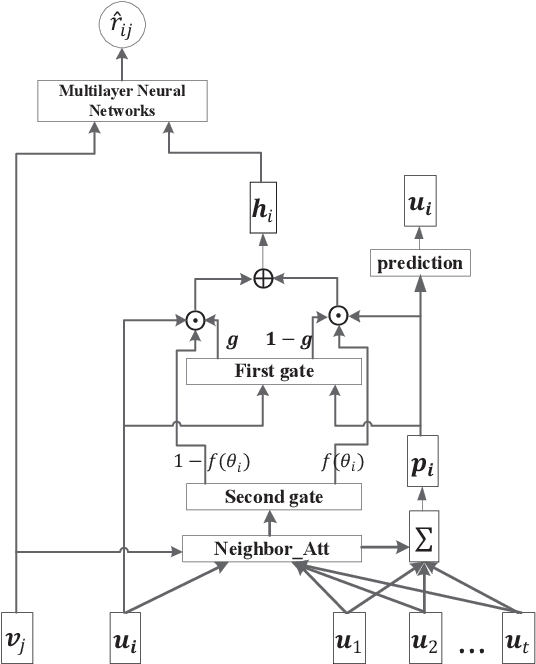
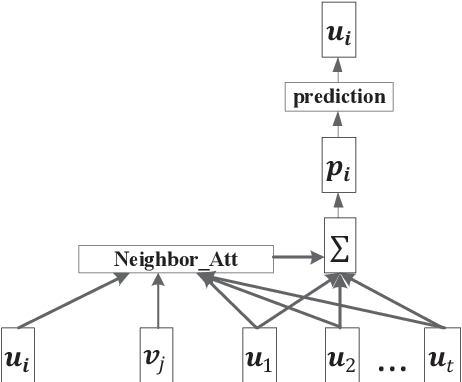
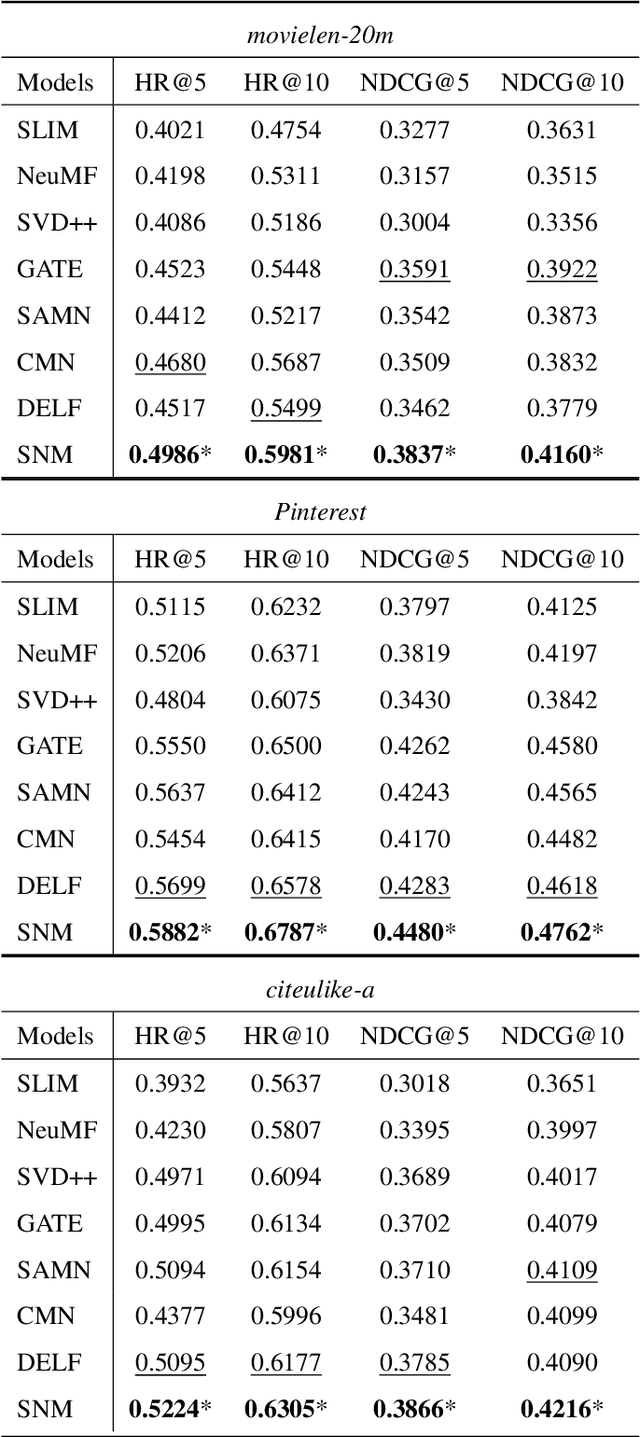
Neighborhood-based recommenders are a major class of Collaborative Filtering (CF) models. The intuition is to exploit neighbors with similar preferences for bridging unseen user-item pairs and alleviating data sparseness. Many existing works propose neural attention networks to aggregate neighbors and place higher weights on specific subsets of users for recommendation. However, the neighborhood information is not necessarily always informative, and the noises in the neighborhood can negatively affect the model performance. To address this issue, we propose a novel neighborhood-based recommender, where a hybrid gated network is designed to automatically separate similar neighbors from dissimilar (noisy) ones, and aggregate those similar neighbors to comprise neighborhood representations. The confidence in the neighborhood is also addressed by putting higher weights on the neighborhood representations if we are confident with the neighborhood information, and vice versa. In addition, a user-neighbor component is proposed to explicitly regularize user-neighbor proximity in the latent space. These two components are combined into a unified model to complement each other for the recommendation task. Extensive experiments on three publicly available datasets show that the proposed model consistently outperforms state-of-the-art neighborhood-based recommenders. We also study different variants of the proposed model to justify the underlying intuition of the proposed hybrid gated network and user-neighbor modeling components.
Visual Object Tracking by Segmentation with Graph Convolutional Network
Sep 08, 2020

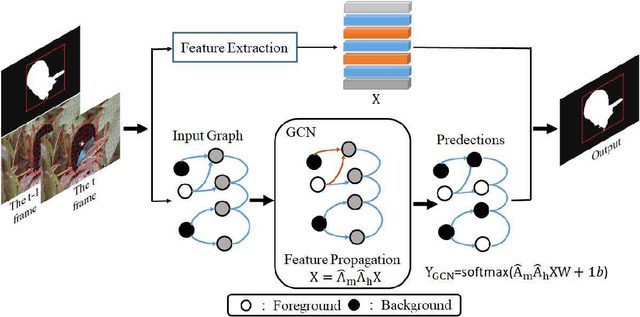
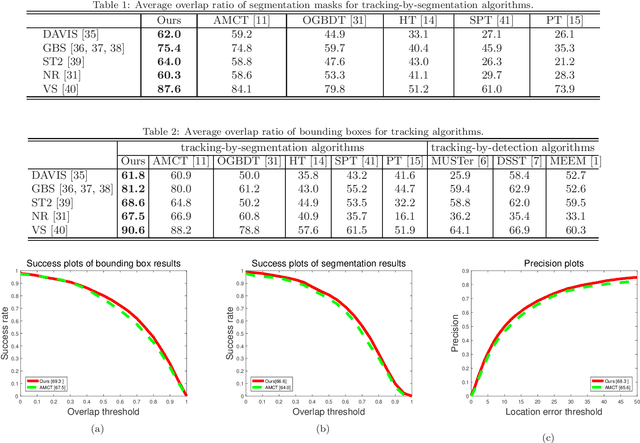
Segmentation-based tracking has been actively studied in computer vision and multimedia. Superpixel based object segmentation and tracking methods are usually developed for this task. However, they independently perform feature representation and learning of superpixels which may lead to sub-optimal results. In this paper, we propose to utilize graph convolutional network (GCN) model for superpixel based object tracking. The proposed model provides a general end-to-end framework which integrates i) label linear prediction, and ii) structure-aware feature information of each superpixel together to obtain object segmentation and further improves the performance of tracking. The main benefits of the proposed GCN method have two main aspects. First, it provides an effective end-to-end way to exploit both spatial and temporal consistency constraint for target object segmentation. Second, it utilizes a mixed graph convolution module to learn a context-aware and discriminative feature for superpixel representation and labeling. An effective algorithm has been developed to optimize the proposed model. Extensive experiments on five datasets demonstrate that our method obtains better performance against existing alternative methods.