 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMT-HI: MOE-based Hyperbolic Interpretable Deep Manifold Transformation for Unspervised Dimensionality Reduction
Oct 25, 2024



Dimensionality reduction (DR) plays a crucial role in various fields, including data engineering and visualization, by simplifying complex datasets while retaining essential information. However, the challenge of balancing DR accuracy and interpretability remains crucial, particularly for users dealing with high-dimensional data. Traditional DR methods often face a trade-off between precision and transparency, where optimizing for performance can lead to reduced interpretability, and vice versa. This limitation is especially prominent in real-world applications such as image, tabular, and text data analysis, where both accuracy and interpretability are critical. To address these challenges, this work introduces the MOE-based Hyperbolic Interpretable Deep Manifold Transformation (DMT-HI). The proposed approach combines hyperbolic embeddings, which effectively capture complex hierarchical structures, with Mixture of Experts (MOE) models, which dynamically allocate tasks based on input features. DMT-HI enhances DR accuracy by leveraging hyperbolic embeddings to represent the hierarchical nature of data, while also improving interpretability by explicitly linking input data, embedding outcomes, and key features through the MOE structure. Extensive experiments demonstrate that DMT-HI consistently achieves superior performance in both DR accuracy and model interpretability, making it a robust solution for complex data analysis. The code is available at \url{https://github.com/zangzelin/code_dmthi}.
Boosting Unsupervised Contrastive Learning Using Diffusion-Based Data Augmentation From Scratch
Sep 10, 2023Unsupervised contrastive learning methods have recently seen significant improvements, particularly through data augmentation strategies that aim to produce robust and generalizable representations. However, prevailing data augmentation methods, whether hand designed or based on foundation models, tend to rely heavily on prior knowledge or external data. This dependence often compromises their effectiveness and efficiency. Furthermore, the applicability of most existing data augmentation strategies is limited when transitioning to other research domains, especially science-related data. This limitation stems from the paucity of prior knowledge and labeled data available in these domains. To address these challenges, we introduce DiffAug-a novel and efficient Diffusion-based data Augmentation technique. DiffAug aims to ensure that the augmented and original data share a smoothed latent space, which is achieved through diffusion steps. Uniquely, unlike traditional methods, DiffAug first mines sufficient prior semantic knowledge about the neighborhood. This provides a constraint to guide the diffusion steps, eliminating the need for labels, external data/models, or prior knowledge. Designed as an architecture-agnostic framework, DiffAug provides consistent improvements. Specifically, it improves image classification and clustering accuracy by 1.6%~4.5%. When applied to biological data, DiffAug improves performance by up to 10.1%, with an average improvement of 5.8%. DiffAug shows good performance in both vision and biological domains.
Git: Clustering Based on Graph of Intensity Topology
Oct 04, 2021\textbf{A}ccuracy, \textbf{R}obustness to noises and scales, \textbf{I}nterpretability, \textbf{S}peed, and \textbf{E}asy to use (ARISE) are crucial requirements of a good clustering algorithm. However, achieving these goals simultaneously is challenging, and most advanced approaches only focus on parts of them. Towards an overall consideration of these aspects, we propose a novel clustering algorithm, namely GIT (Clustering Based on \textbf{G}raph of \textbf{I}ntensity \textbf{T}opology). GIT considers both local and global data structures: firstly forming local clusters based on intensity peaks of samples, and then estimating the global topological graph (topo-graph) between these local clusters. We use the Wasserstein Distance between the predicted and prior class proportions to automatically cut noisy edges in the topo-graph and merge connected local clusters as final clusters. Then, we compare GIT with seven competing algorithms on five synthetic datasets and nine real-world datasets. With fast local cluster detection, robust topo-graph construction and accurate edge-cutting, GIT shows attractive ARISE performance and significantly exceeds other non-convex clustering methods. For example, GIT outperforms its counterparts about $10\%$ (F1-score) on MNIST and FashionMNIST. Code is available at \color{red}{https://github.com/gaozhangyang/GIT}.
LookHops: light multi-order convolution and pooling for graph classification
Dec 28, 2020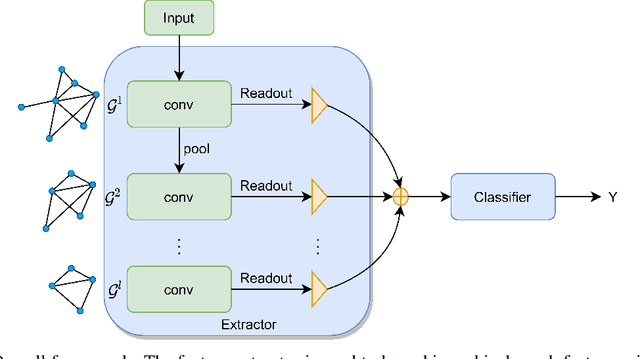
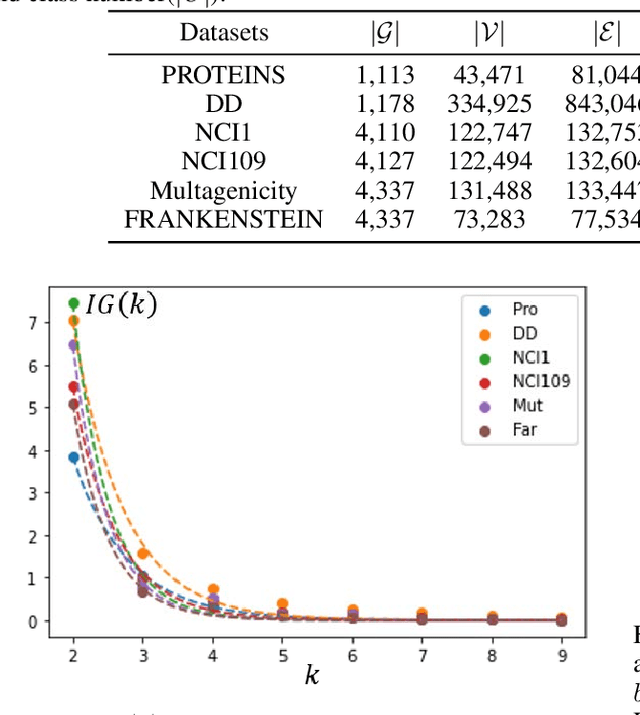
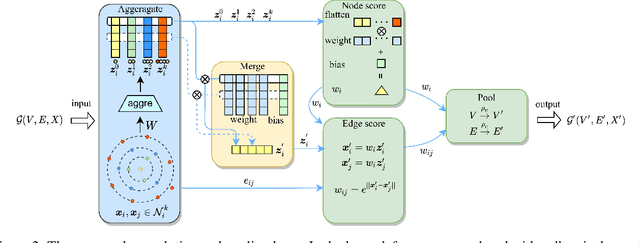

Convolution and pooling are the key operations to learn hierarchical representation for graph classification, where more expressive $k$-order($k>1$) method requires more computation cost, limiting the further applications. In this paper, we investigate the strategy of selecting $k$ via neighborhood information gain and propose light $k$-order convolution and pooling requiring fewer parameters while improving the performance. Comprehensive and fair experiments through six graph classification benchmarks show: 1) the performance improvement is consistent to the $k$-order information gain. 2) the proposed convolution requires fewer parameters while providing competitive results. 3) the proposed pooling outperforms SOTA algorithms in terms of efficiency and performance.
Deep Clustering and Representation Learning that Preserves Geometric Structures
Sep 29, 2020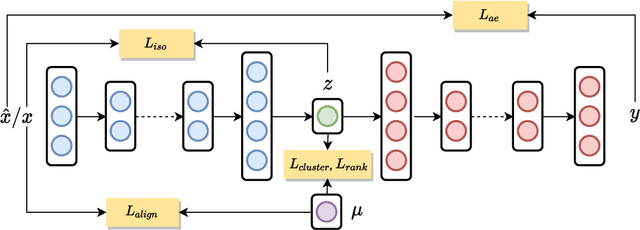
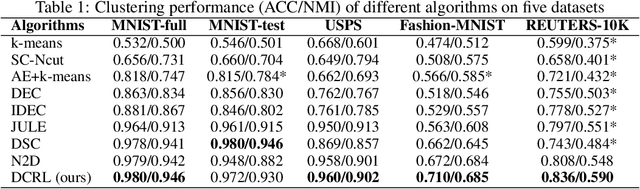
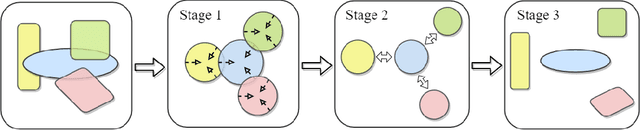
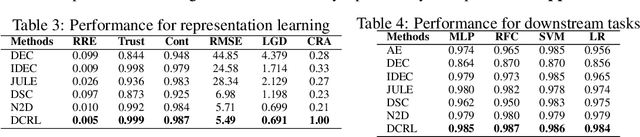
In this paper, we propose a novel framework for Deep Clustering and Representation Learning (DCRL) that preserves the geometric structure of data. In the proposed DCRL framework, the clustering of data points from different manifolds is done in the latent space guided by a clustering loss. To overcome the problem that clustering-oriented losses may deteriorate the geometric structure of embeddings in the latent space, two structure-oriented losses, namely an isometric loss and a ranking loss, are proposed to preserve intra-manifold structure locally and inter-manifold structure globally. Experimental results on various datasets show that the DCRL framework leads to comparable performances to current state-of-the-art deep clustering algorithms, yet exhibits superior performance for downstream tasks. Our results also demonstrate the importance and effectiveness of the proposed method in preserving geometric structure in terms of visualization and performance metrics.
Clustering Based on Graph of Density Topology
Sep 24, 2020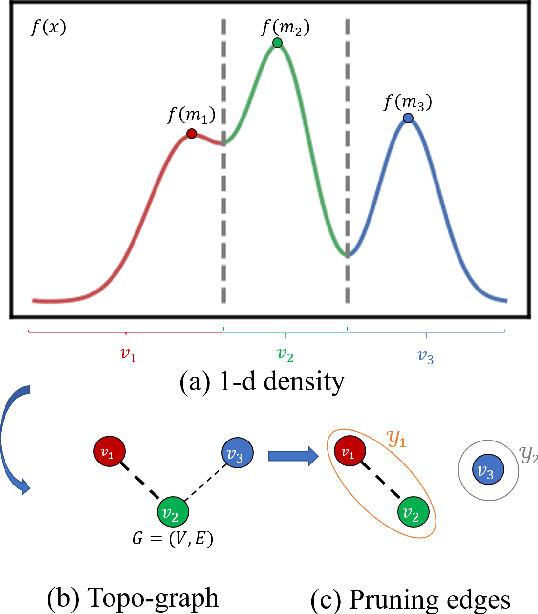

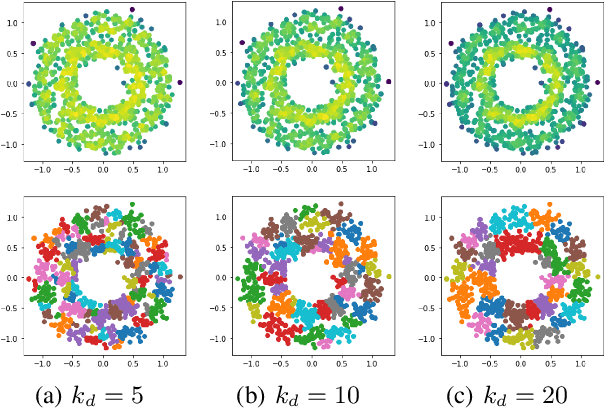
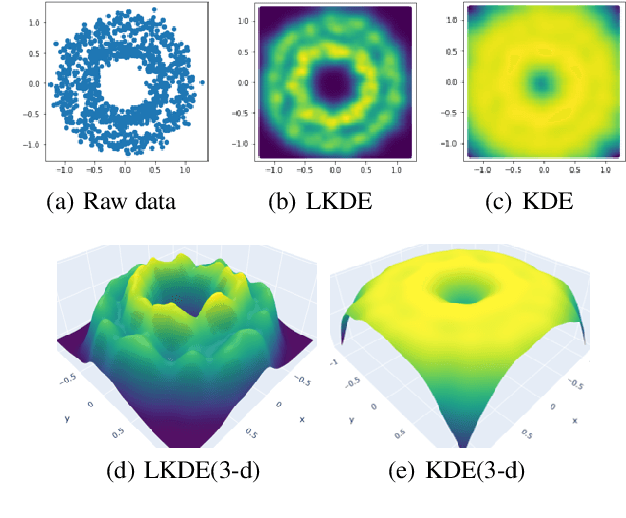
Data clustering with uneven distribution in high level noise is challenging. Currently, HDBSCAN is considered as the SOTA algorithm for this problem. In this paper, we propose a novel clustering algorithm based on what we call graph of density topology (GDT). GDT jointly considers the local and global structures of data samples: firstly forming local clusters based on a density growing process with a strategy for properly noise handling as well as cluster boundary detection; and then estimating a GDT from relationship between local clusters in terms of a connectivity measure, givingglobal topological graph. The connectivity, measuring similarity between neighboring local clusters, is based on local clusters rather than individual points, ensuring its robustness to even very large noise. Evaluation results on both toy and real-world datasets show that GDT achieves the SOTA performance by far on almost all the popular datasets, and has a low time complexity of O(nlogn). The code is available at https://github.com/gaozhangyang/DGC.git.