 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoneyTrap: Deceiving Large Language Model Attackers to Honeypot Traps with Resilient Multi-Agent Defense
Jan 07, 2026Jailbreak attacks pose significant threats to large language models (LLMs), enabling attackers to bypass safeguards. However, existing reactive defense approaches struggle to keep up with the rapidly evolving multi-turn jailbreaks, where attackers continuously deepen their attacks to exploit vulnerabilities. To address this critical challenge, we propose HoneyTrap, a novel deceptive LLM defense framework leveraging collaborative defenders to counter jailbreak attacks. It integrates four defensive agents, Threat Interceptor, Misdirection Controller, Forensic Tracker, and System Harmonizer, each performing a specialized security role and collaborating to complete a deceptive defense. To ensure a comprehensive evaluation, we introduce MTJ-Pro, a challenging multi-turn progressive jailbreak dataset that combines seven advanced jailbreak strategies designed to gradually deepen attack strategies across multi-turn attacks. Besides, we present two novel metrics: Mislead Success Rate (MSR) and Attack Resource Consumption (ARC), which provide more nuanced assessments of deceptive defense beyond conventional measures. Experimental results on GPT-4, GPT-3.5-turbo, Gemini-1.5-pro, and LLaMa-3.1 demonstrate that HoneyTrap achieves an average reduction of 68.77% in attack success rates compared to state-of-the-art baselines. Notably, even in a dedicated adaptive attacker setting with intensified conditions, HoneyTrap remains resilient, leveraging deceptive engagement to prolong interactions, significantly increasing the time and computational costs required for successful exploitation. Unlike simple rejection, HoneyTrap strategically wastes attacker resources without impacting benign queries, improving MSR and ARC by 118.11% and 149.16%, respectively.
When Bayesian Tensor Completion Meets Multioutput Gaussian Processes: Functional Universality and Rank Learning
Dec 25, 2025Functional tensor decomposition can analyze multi-dimensional data with real-valued indices, paving the path for applications in machine learning and signal processing. A limitation of existing approaches is the assumption that the tensor rank-a critical parameter governing model complexity-is known. However, determining the optimal rank is a non-deterministic polynomial-time hard (NP-hard) task and there is a limited understanding regarding the expressive power of functional low-rank tensor models for continuous signals. We propose a rank-revealing functional Bayesian tensor completion (RR-FBTC) method. Modeling the latent functions through carefully designed multioutput Gaussian processes, RR-FBTC handles tensors with real-valued indices while enabling automatic tensor rank determination during the inference process. We establish the universal approximation property of the model for continuous multi-dimensional signals, demonstrating its expressive power in a concise format. To learn this model, we employ the variational inference framework and derive an efficient algorithm with closed-form updates. Experiments on both synthetic and real-world datasets demonstrate the effectiveness and superiority of the RR-FBTC over state-of-the-art approaches. The code is available at https://github.com/OceanSTARLab/RR-FBTC.
MergeDNA: Context-aware Genome Modeling with Dynamic Tokenization through Token Merging
Nov 17, 2025



Modeling genomic sequences faces two unsolved challenges: the information density varies widely across different regions, while there is no clearly defined minimum vocabulary unit. Relying on either four primitive bases or independently designed DNA tokenizers, existing approaches with naive masked language modeling pre-training often fail to adapt to the varying complexities of genomic sequences. Leveraging Token Merging techniques, this paper introduces a hierarchical architecture that jointly optimizes a dynamic genomic tokenizer and latent Transformers with context-aware pre-training tasks. As for network structures, the tokenization module automatically chunks adjacent bases into words by stacking multiple layers of the differentiable token merging blocks with local-window constraints, then a Latent Encoder captures the global context of these merged words by full-attention blocks. Symmetrically employing a Latent Decoder and a Local Decoder, MergeDNA learns with two pre-training tasks: Merged Token Reconstruction simultaneously trains the dynamic tokenization module and adaptively filters important tokens, while Adaptive Masked Token Modeling learns to predict these filtered tokens to capture informative contents. Extensive experiments show that MergeDNA achieves superior performance on three popular DNA benchmarks and several multi-omics tasks with fine-tuning or zero-shot evaluation, outperforming typical tokenization methods and large-scale DNA foundation models.
GGBench: A Geometric Generative Reasoning Benchmark for Unified Multimodal Models
Nov 14, 2025
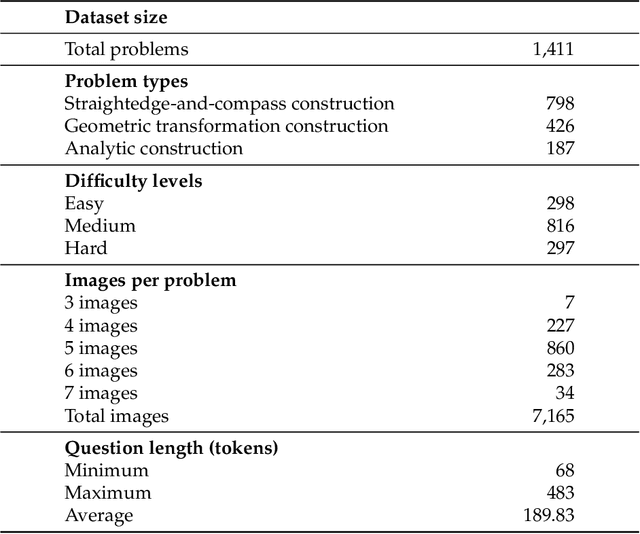
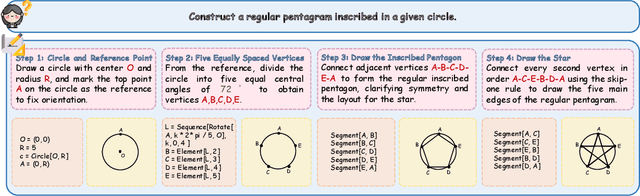

The advent of Unified Multimodal Models (UMMs) signals a paradigm shift in artificial intelligence, moving from passive perception to active, cross-modal generation. Despite their unprecedented ability to synthesize information, a critical gap persists in evaluation: existing benchmarks primarily assess discriminative understanding or unconstrained image generation separately, failing to measure the integrated cognitive process of generative reasoning. To bridge this gap, we propose that geometric construction provides an ideal testbed as it inherently demands a fusion of language comprehension and precise visual generation. We introduce GGBench, a benchmark designed specifically to evaluate geometric generative reasoning. It provides a comprehensive framework for systematically diagnosing a model's ability to not only understand and reason but to actively construct a solution, thereby setting a more rigorous standard for the next generation of intelligent systems. Project website: https://opendatalab-raiser.github.io/GGBench/.
MrCoM: A Meta-Regularized World-Model Generalizing Across Multi-Scenarios
Nov 09, 2025Model-based reinforcement learning (MBRL) is a crucial approach to enhance the generalization capabilities and improve the sample efficiency of RL algorithms. However, current MBRL methods focus primarily on building world models for single tasks and rarely address generalization across different scenarios. Building on the insight that dynamics within the same simulation engine share inherent properties, we attempt to construct a unified world model capable of generalizing across different scenarios, named Meta-Regularized Contextual World-Model (MrCoM). This method first decomposes the latent state space into various components based on the dynamic characteristics, thereby enhancing the accuracy of world-model prediction. Further, MrCoM adopts meta-state regularization to extract unified representation of scenario-relevant information, and meta-value regularization to align world-model optimization with policy learning across diverse scenario objectives. We theoretically analyze the generalization error upper bound of MrCoM in multi-scenario settings. We systematically evaluate our algorithm's generalization ability across diverse scenarios, demonstrating significantly better performance than previous state-of-the-art methods.
Less Is More: Generating Time Series with LLaMA-Style Autoregression in Simple Factorized Latent Spaces
Nov 07, 2025Generative models for multivariate time series are essential for data augmentation, simulation, and privacy preservation, yet current state-of-the-art diffusion-based approaches are slow and limited to fixed-length windows. We propose FAR-TS, a simple yet effective framework that combines disentangled factorization with an autoregressive Transformer over a discrete, quantized latent space to generate time series. Each time series is decomposed into a data-adaptive basis that captures static cross-channel correlations and temporal coefficients that are vector-quantized into discrete tokens. A LLaMA-style autoregressive Transformer then models these token sequences, enabling fast and controllable generation of sequences with arbitrary length. Owing to its streamlined design, FAR-TS achieves orders-of-magnitude faster generation than Diffusion-TS while preserving cross-channel correlations and an interpretable latent space, enabling high-quality and flexible time series synthesis.
StyleDecipher: Robust and Explainable Detection of LLM-Generated Texts with Stylistic Analysis
Oct 14, 2025With the increasing integration of large language models (LLMs) into open-domain writing, detecting machine-generated text has become a critical task for ensuring content authenticity and trust. Existing approaches rely on statistical discrepancies or model-specific heuristics to distinguish between LLM-generated and human-written text. However, these methods struggle in real-world scenarios due to limited generalization, vulnerability to paraphrasing, and lack of explainability, particularly when facing stylistic diversity or hybrid human-AI authorship. In this work, we propose StyleDecipher, a robust and explainable detection framework that revisits LLM-generated text detection using combined feature extractors to quantify stylistic differences. By jointly modeling discrete stylistic indicators and continuous stylistic representations derived from semantic embeddings, StyleDecipher captures distinctive style-level divergences between human and LLM outputs within a unified representation space. This framework enables accurate, explainable, and domain-agnostic detection without requiring access to model internals or labeled segments. Extensive experiments across five diverse domains, including news, code, essays, reviews, and academic abstracts, demonstrate that StyleDecipher consistently achieves state-of-the-art in-domain accuracy. Moreover, in cross-domain evaluations, it surpasses existing baselines by up to 36.30%, while maintaining robustness against adversarial perturbations and mixed human-AI content. Further qualitative and quantitative analysis confirms that stylistic signals provide explainable evidence for distinguishing machine-generated text. Our source code can be accessed at https://github.com/SiyuanLi00/StyleDecipher.
ResearchPulse: Building Method-Experiment Chains through Multi-Document Scientific Inference
Sep 03, 2025Understanding how scientific ideas evolve requires more than summarizing individual papers-it demands structured, cross-document reasoning over thematically related research. In this work, we formalize multi-document scientific inference, a new task that extracts and aligns motivation, methodology, and experimental results across related papers to reconstruct research development chains. This task introduces key challenges, including temporally aligning loosely structured methods and standardizing heterogeneous experimental tables. We present ResearchPulse, an agent-based framework that integrates instruction planning, scientific content extraction, and structured visualization. It consists of three coordinated agents: a Plan Agent for task decomposition, a Mmap-Agent that constructs motivation-method mind maps, and a Lchart-Agent that synthesizes experimental line charts. To support this task, we introduce ResearchPulse-Bench, a citation-aware benchmark of annotated paper clusters. Experiments show that our system, despite using 7B-scale agents, consistently outperforms strong baselines like GPT-4o in semantic alignment, structural consistency, and visual fidelity. The dataset are available in https://huggingface.co/datasets/ResearchPulse/ResearchPulse-Bench.
Multi-View 3D Point Tracking
Aug 28, 2025We introduce the first data-driven multi-view 3D point tracker, designed to track arbitrary points in dynamic scenes using multiple camera views. Unlike existing monocular trackers, which struggle with depth ambiguities and occlusion, or prior multi-camera methods that require over 20 cameras and tedious per-sequence optimization, our feed-forward model directly predicts 3D correspondences using a practical number of cameras (e.g., four), enabling robust and accurate online tracking. Given known camera poses and either sensor-based or estimated multi-view depth, our tracker fuses multi-view features into a unified point cloud and applies k-nearest-neighbors correlation alongside a transformer-based update to reliably estimate long-range 3D correspondences, even under occlusion. We train on 5K synthetic multi-view Kubric sequences and evaluate on two real-world benchmarks: Panoptic Studio and DexYCB, achieving median trajectory errors of 3.1 cm and 2.0 cm, respectively. Our method generalizes well to diverse camera setups of 1-8 views with varying vantage points and video lengths of 24-150 frames. By releasing our tracker alongside training and evaluation datasets, we aim to set a new standard for multi-view 3D tracking research and provide a practical tool for real-world applications. Project page available at https://ethz-vlg.github.io/mvtracker.
Interpreting Fedspeak with Confidence: A LLM-Based Uncertainty-Aware Framework Guided by Monetary Policy Transmission Paths
Aug 12, 2025"Fedspeak", the stylized and often nuanced language used by the U.S. Federal Reserve, encodes implicit policy signals and strategic stances. The Federal Open Market Committee strategically employs Fedspeak as a communication tool to shape market expectations and influence both domestic and global economic conditions. As such, automatically parsing and interpreting Fedspeak presents a high-impact challenge, with significant implications for financial forecasting, algorithmic trading, and data-driven policy analysis. In this paper, we propose an LLM-based, uncertainty-aware framework for deciphering Fedspeak and classifying its underlying monetary policy stance. Technically, to enrich the semantic and contextual representation of Fedspeak texts, we incorporate domain-specific reasoning grounded in the monetary policy transmission mechanism. We further introduce a dynamic uncertainty decoding module to assess the confidence of model predictions, thereby enhancing both classification accuracy and model reliability. Experimental results demonstrate that our framework achieves state-of-the-art performance on the policy stance analysis task. Moreover, statistical analysis reveals a significant positive correlation between perceptual uncertainty and model error rates, validating the effectiveness of perceptual uncertainty as a diagnostic signal.