 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMergeTok: Unified Continuous and Discrete Visual Tokenization via Token Merging
May 29, 2026Most visual tokenizers for image generation are bifurcated into two families with complementary limitations: continuous VAEs offer high-fidelity reconstruction but suffer from dense, entangled latents that are poorly suited for semantic control, whereas discrete VQ-based models enable autoregressive generation yet struggle with gradient sparsity, unstable training, and codebook collapse. In this work, we introduce MergeTok, a unified tokenizer that jointly optimizes continuous (VAE) and discrete (VQ) tokenizers within a encoder-decoder architecture, leveraging token merging techniques as a semantic bridge. By clustering similar tokens during encoding, MergeTok establishes a structural prior that provides dual supervision signals: (i) it imposes merged-token semantic alignment in the VAE branch, regularizing its latent space toward disentangled, semantic-aware representations; (ii) it derives group-wise constraints, promoting intra-group diversity and inter-group exclusivity that stabilize VQ training. MergeTok shows competitive reconstruction and generation performance on ImageNet-256, with substantially lower rFID than strong VAE and VQ models under matched token budgets, while producing semantically-organized token representations compatible with both autoregressive and diffusion generators. This shows that a single architecture can endow visual tokenizers with robust semantic organization and generator-friendly discreteness.
RankE: End-to-End Post-Training for Discrete Text-to-Image Generation with Decoder Co-Evolution
May 20, 2026Discrete autoregressive (AR) text-to-image (T2I) models pair a VQ tokenizer with an AR policy, and current post-training pipelines optimize only the policy while keeping the VQ decoder frozen. Recent diffusion T2I work, exemplified by REPA-E, has shown that the VAE itself constitutes a key alignment bottleneck, yet no analogous investigation exists for discrete AR models. We show that policy-only optimization induces Latent Covariate Shift: as the policy evolves, the resulting token distribution diverges from the ground-truth distribution on which the decoder was trained, such that reward scores improve while decoded image quality degrades. To address this mismatch, we propose RankE, the first end-to-end post-training framework for discrete T2I generation. Rather than optimizing the policy against a fixed decoder, RankE co-evolves both components through alternating optimization: each module maximizes a ranking-based alignment objective while being regularized by a stability-preserving anchor suited to its parameter space. This co-evolution breaks the fidelity--alignment trade-off that plagues frozen-decoder approaches: on LlamaGen-XL (775M), standard RL improves CLIP but degrades FID, whereas RankE improves both simultaneously (FID 15.21, CLIP 33.76 on MS-COCO 30K). Consistent gains on Janus-Pro (1B) confirm that decoder co-evolution reliably converts reward optimization into pixel-space quality improvements.
When Models Judge Themselves: Unsupervised Self-Evolution for Multimodal Reasoning
Mar 22, 2026Recent progress in multimodal large language models has led to strong performance on reasoning tasks, but these improvements largely rely on high-quality annotated data or teacher-model distillation, both of which are costly and difficult to scale.To address this, we propose an unsupervised self-evolution training framework for multimodal reasoning that achieves stable performance improvements without using human-annotated answers or external reward models. For each input, we sample multiple reasoning trajectories and jointly model their within group structure.We use the Actor's self-consistency signal as a training prior, and introduce a bounded Judge based modulation to continuously reweight trajectories of different quality.We further model the modulated scores as a group level distribution and convert absolute scores into relative advantages within each group, enabling more robust policy updates. Trained with Group Relative Policy Optimization (GRPO) on unlabeled data, our method consistently improves reasoning performance and generalization on five mathematical reasoning benchmarks, offering a scalable path toward self-evolving multimodal models.The code are available at https://dingwu1021.github.io/SelfJudge/.
Language-Guided and Motion-Aware Gait Representation for Generalizable Recognition
Jan 17, 2026Gait recognition is emerging as a promising technology and an innovative field within computer vision. However, existing methods typically rely on complex architectures to directly extract features from images and apply pooling operations to obtain sequence-level representations. Such designs often lead to overfitting on static noise (e.g., clothing), while failing to effectively capture dynamic motion regions.To address the above challenges, we present a Language guided and Motion-aware gait recognition framework, named LMGait.In particular, we utilize designed gait-related language cues to capture key motion features in gait sequences.
Target-Balanced Score Distillation
Nov 12, 2025Score Distillation Sampling (SDS) enables 3D asset generation by distilling priors from pretrained 2D text-to-image diffusion models, but vanilla SDS suffers from over-saturation and over-smoothing. To mitigate this issue, recent variants have incorporated negative prompts. However, these methods face a critical trade-off: limited texture optimization, or significant texture gains with shape distortion. In this work, we first conduct a systematic analysis and reveal that this trade-off is fundamentally governed by the utilization of the negative prompts, where Target Negative Prompts (TNP) that embed target information in the negative prompts dramatically enhancing texture realism and fidelity but inducing shape distortions. Informed by this key insight, we introduce the Target-Balanced Score Distillation (TBSD). It formulates generation as a multi-objective optimization problem and introduces an adaptive strategy that effectively resolves the aforementioned trade-off. Extensive experiments demonstrate that TBSD significantly outperforms existing state-of-the-art methods, yielding 3D assets with high-fidelity textures and geometrically accurate shape.
Two-Timescale Joint Transmit and Pinching Beamforming for Pinching-Antenna Systems
Apr 13, 2025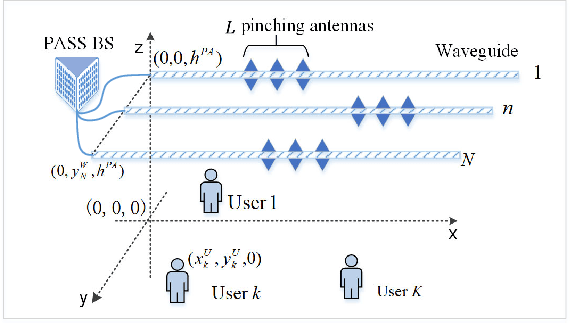
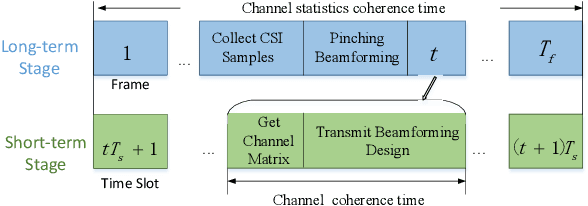
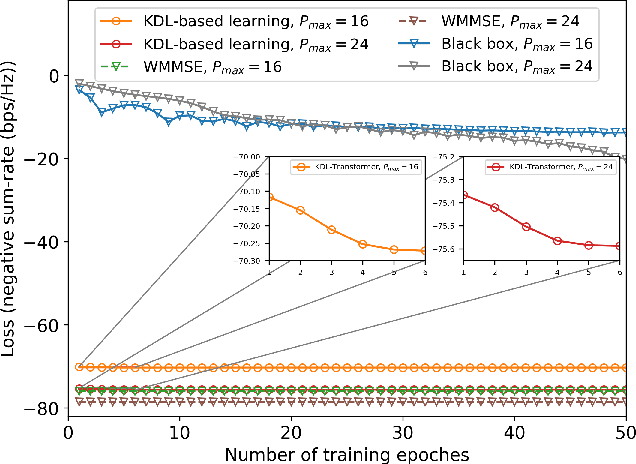
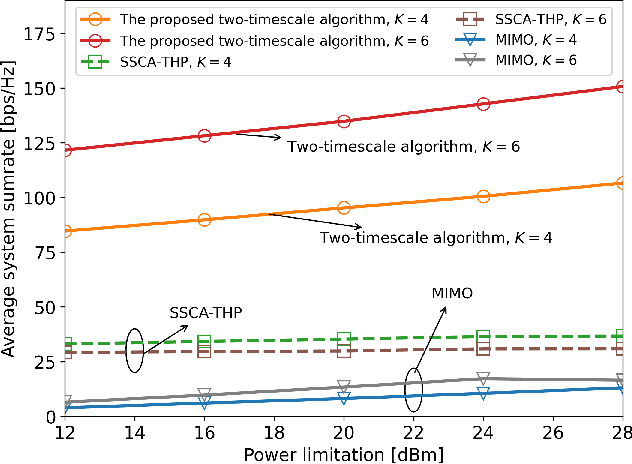
Pinching antenna systems (PASS) have been proposed as a revolutionary flexible antenna technology which facilitates line-of-sight links via numerous low-cost pinching antennas with adjustable activation positions over waveguides. This letter proposes a two-timescale joint transmit and pinching beamforming design for the maximization of sum rate of a PASS-based downlink multi-user multiple input single output system. A primal dual decomposition method is developed to decouple the two-timescale problem into two sub-problems: 1) A Karush-Kuhn-Tucker-guided dual learning-based approach is proposed to solve the short-term transmit beamforming design sub-problem; 2) The long-term pinching beamforming design sub-problem is tackled by adopting a stochastic successive convex approximation method. Simulation results demonstrate that the proposed two-timescale algorithm achieves a significant performance gain compared to other baselines.
MergeVQ: A Unified Framework for Visual Generation and Representation with Disentangled Token Merging and Quantization
Apr 01, 2025Masked Image Modeling (MIM) with Vector Quantization (VQ) has achieved great success in both self-supervised pre-training and image generation. However, most existing methods struggle to address the trade-off in shared latent space for generation quality vs. representation learning and efficiency. To push the limits of this paradigm, we propose MergeVQ, which incorporates token merging techniques into VQ-based generative models to bridge the gap between image generation and visual representation learning in a unified architecture. During pre-training, MergeVQ decouples top-k semantics from latent space with the token merge module after self-attention blocks in the encoder for subsequent Look-up Free Quantization (LFQ) and global alignment and recovers their fine-grained details through cross-attention in the decoder for reconstruction. As for the second-stage generation, we introduce MergeAR, which performs KV Cache compression for efficient raster-order prediction. Extensive experiments on ImageNet verify that MergeVQ as an AR generative model achieves competitive performance in both visual representation learning and image generation tasks while maintaining favorable token efficiency and inference speed. The code and model will be available at https://apexgen-x.github.io/MergeVQ.
Unveiling the Backbone-Optimizer Coupling Bias in Visual Representation Learning
Oct 08, 2024



This paper delves into the interplay between vision backbones and optimizers, unvealing an inter-dependent phenomenon termed \textit{\textbf{b}ackbone-\textbf{o}ptimizer \textbf{c}oupling \textbf{b}ias} (BOCB). We observe that canonical CNNs, such as VGG and ResNet, exhibit a marked co-dependency with SGD families, while recent architectures like ViTs and ConvNeXt share a tight coupling with the adaptive learning rate ones. We further show that BOCB can be introduced by both optimizers and certain backbone designs and may significantly impact the pre-training and downstream fine-tuning of vision models. Through in-depth empirical analysis, we summarize takeaways on recommended optimizers and insights into robust vision backbone architectures. We hope this work can inspire the community to question long-held assumptions on backbones and optimizers, stimulate further explorations, and thereby contribute to more robust vision systems. The source code and models are publicly available at https://bocb-ai.github.io/.
Masked Modeling for Self-supervised Representation Learning on Vision and Beyond
Jan 09, 2024



As the deep learning revolution marches on, self-supervised learning has garnered increasing attention in recent years thanks to its remarkable representation learning ability and the low dependence on labeled data. Among these varied self-supervised techniques, masked modeling has emerged as a distinctive approach that involves predicting parts of the original data that are proportionally masked during training. This paradigm enables deep models to learn robust representations and has demonstrated exceptional performance in the context of computer vision, natural language processing, and other modalities. In this survey, we present a comprehensive review of the masked modeling framework and its methodology. We elaborate on the details of techniques within masked modeling, including diverse masking strategies, recovering targets, network architectures, and more. Then, we systematically investigate its wide-ranging applications across domains. Furthermore, we also explore the commonalities and differences between masked modeling methods in different fields. Toward the end of this paper, we conclude by discussing the limitations of current techniques and point out several potential avenues for advancing masked modeling research. A paper list project with this survey is available at \url{https://github.com/Lupin1998/Awesome-MIM}.