 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-CLIP: Zero-shot 3D Anomaly Detection by Geometry-Aware Prompt and Synergistic View Representation Learning
Feb 25, 2026Zero-shot 3D Anomaly Detection is an emerging task that aims to detect anomalies in a target dataset without any target training data, which is particularly important in scenarios constrained by sample scarcity and data privacy concerns. While current methods adapt CLIP by projecting 3D point clouds into 2D representations, they face challenges. The projection inherently loses some geometric details, and the reliance on a single 2D modality provides an incomplete visual understanding, limiting their ability to detect diverse anomaly types. To address these limitations, we propose the Geometry-Aware Prompt and Synergistic View Representation Learning (GS-CLIP) framework, which enables the model to identify geometric anomalies through a two-stage learning process. In stage 1, we dynamically generate text prompts embedded with 3D geometric priors. These prompts contain global shape context and local defect information distilled by our Geometric Defect Distillation Module (GDDM). In stage 2, we introduce Synergistic View Representation Learning architecture that processes rendered and depth images in parallel. A Synergistic Refinement Module (SRM) subsequently fuses the features of both streams, capitalizing on their complementary strengths. Comprehensive experimental results on four large-scale public datasets show that GS-CLIP achieves superior performance in detection. Code can be available at https://github.com/zhushengxinyue/GS-CLIP.
Variable-Length Wideband CSI Feedback via Loewner Interpolation and Deep Learning
Jan 13, 2026In this paper, we propose a variable-length wideband channel state information (CSI) feedback scheme for Frequency Division Duplex (FDD) massive multiple-input multipleoutput (MIMO) systems in U6G band (6425MHz-7125MHz). Existing compressive sensing (CS)-based and deep learning (DL)- based schemes preprocess the channel by truncating it in the angular-delay domain. However, the energy leakage effect caused by the Discrete Fourier Transform (DFT) basis will be more serious and leads to a bottleneck in recovery accuracy when applied to wideband channels such as those in U6G. To solve this problem, we introduce the Loewner Interpolation (LI) framework which generates a set of dynamic bases based on the current CSI matrix, enabling highly efficient compression in the frequency domain. Then, the LI basis is further compressed in the spatial domain through a neural network. To achieve a flexible trade-off between feedback overhead and recovery accuracy, we design a rateless auto-encoder trained with tail dropout and a multi-objective learning schedule, supporting variable-length feedback with a singular model. Meanwhile, the codewords are ranked by importance, ensuring that the base station (BS) can still maintain acceptable reconstruction performance under limited feedback with tail erasures. Furthermore, an adaptive quantization strategy is developed for the feedback framework to enhance robustness. Simulation results demonstrate that the proposed scheme could achieve higher CSI feedback accuracy with less or equal feedback overhead, and improve spectral efficiency compared with baseline schemes.
Robust Beamforming for Multiuser MIMO Systems with Unknown Channel Statistics: A Hybrid Offline-Online Framework
Dec 16, 2025Robust beamforming design under imperfect channel state information (CSI) is a fundamental challenge in multiuser multiple-input multiple-output (MU-MIMO) systems, particularly when the channel estimation error statistics are unknown. Conventional model-driven methods usually rely on prior knowledge of the error covariance matrix and data-driven deep learning approaches suffer from poor generalization capability to unseen channel conditions. To address these limitations, this paper proposes a hybrid offline-online framework that achieves effective offline learning and rapid online adaptation. In the offline phase, we propose a shared (among users) deep neural network (DNN) that is able to learn the channel estimation error covariance from observed samples, thus enabling robust beamforming without statistical priors. Meanwhile, to facilitate real-time deployment, we propose a sparse augmented low-rank (SALR) method to reduce complexity while maintaining comparable performance. In the online phase, we show that the proposed network can be rapidly fine-tuned with minimal gradient steps. Furthermore, a multiple basis model-agnostic meta-learning (MB-MAML) strategy is further proposed to maintain multiple meta-initializations and by dynamically selecting the best one online, we can improve the adaptation and generalization capability of the proposed framework under unseen or non-stationary channels. Simulation results demonstrate that the proposed offline-online framework exhibits strong robustness across diverse channel conditions and it is able to significantly outperform state-of-the-art (SOTA) baselines.
Cross-Sparsity-Enabled Multipath Perception via Structured Bayesian Inference for Multi-Target Estimation
Nov 18, 2025In this paper, we investigate a multi-target sensing system in multipath environment, where inter-target scattering gives rise to first-order reflected paths whose angles of departure (AoDs) and angles of arrival (AoAs) coincide with the direct-path angles of different targets. Unlike other multipath components, these first-order paths carry structural information that can be exploited as additional prior knowledge for target direction estimation. To exploit this property, we construct a sparse representation of the multi-target sensing channel and propose a novel cross sparsity structure under a three-layer hierarchical structured (3LHS) prior model, which leverages the first-order paths to enhance the prior probability of the direct paths and thereby improve the estimation accuracy. Building on this model, we propose a structured fast turbo variational Bayesian inference (SF-TVBI) algorithm, which integrates an efficient message-passing strategy to enable tractable probabilistic exchange within the cross sparsity, and a two-timescale update scheme to reduce the update frequency of the high-dimensional sparse vector. Simulation results demonstrate that leveraging the proposed cross sparsity structure is able to improve the target angle estimation accuracy substantially, and the SF-TVBI algorithm achieves estimation performance comparable to that of the Turbo-VBI, but with lower computational complexity.
GBV-SQL: Guided Generation and SQL2Text Back-Translation Validation for Multi-Agent Text2SQL
Sep 16, 2025While Large Language Models have significantly advanced Text2SQL generation, a critical semantic gap persists where syntactically valid queries often misinterpret user intent. To mitigate this challenge, we propose GBV-SQL, a novel multi-agent framework that introduces Guided Generation with SQL2Text Back-translation Validation. This mechanism uses a specialized agent to translate the generated SQL back into natural language, which verifies its logical alignment with the original question. Critically, our investigation reveals that current evaluation is undermined by a systemic issue: the poor quality of the benchmarks themselves. We introduce a formal typology for "Gold Errors", which are pervasive flaws in the ground-truth data, and demonstrate how they obscure true model performance. On the challenging BIRD benchmark, GBV-SQL achieves 63.23% execution accuracy, a 5.8% absolute improvement. After removing flawed examples, GBV-SQL achieves 96.5% (dev) and 97.6% (test) execution accuracy on the Spider benchmark. Our work offers both a robust framework for semantic validation and a critical perspective on benchmark integrity, highlighting the need for more rigorous dataset curation.
Robust Super-Resolution Compressive Sensing: A Two-timescale Alternating MAP Approach
Aug 09, 2025The problem of super-resolution compressive sensing (SR-CS) is crucial for various wireless sensing and communication applications. Existing methods often suffer from limited resolution capabilities and sensitivity to hyper-parameters, hindering their ability to accurately recover sparse signals when the grid parameters do not lie precisely on a fixed grid and are close to each other. To overcome these limitations, this paper introduces a novel robust super-resolution compressive sensing algorithmic framework using a two-timescale alternating maximum a posteriori (MAP) approach. At the slow timescale, the proposed framework iterates between a sparse signal estimation module and a grid update module. In the sparse signal estimation module, a hyperbolic-tangent prior distribution based variational Bayesian inference (tanh-VBI) algorithm with a strong sparsity promotion capability is adopted to estimate the posterior probability of the sparse vector and accurately identify active grid components carrying primary energy under a dense grid. Subsequently, the grid update module utilizes the BFGS algorithm to refine these low-dimensional active grid components at a faster timescale to achieve super-resolution estimation of the grid parameters with a low computational cost. The proposed scheme is applied to the channel extrapolation problem, and simulation results demonstrate the superiority of the proposed scheme compared to baseline schemes.
MT-PCR: A Hybrid Mamba-Transformer with Spatial Serialization for Hierarchical Point Cloud Registration
Jun 16, 2025Point cloud registration (PCR) is a fundamental task in 3D computer vision and robotics. Most existing learning-based PCR methods rely on Transformers, which suffer from quadratic computational complexity. This limitation restricts the resolution of point clouds that can be processed, inevitably leading to information loss. In contrast, Mamba-a recently proposed model based on state space models (SSMs)-achieves linear computational complexity while maintaining strong long-range contextual modeling capabilities. However, directly applying Mamba to PCR tasks yields suboptimal performance due to the unordered and irregular nature of point cloud data. To address this challenge, we propose MT-PCR, the first point cloud registration framework that integrates both Mamba and Transformer modules. Specifically, we serialize point cloud features using Z-order space-filling curves to enforce spatial locality, enabling Mamba to better model the geometric structure of the input. Additionally, we remove the order indicator module commonly used in Mamba-based sequence modeling, leads to improved performance in our setting. The serialized features are then processed by an optimized Mamba encoder, followed by a Transformer refinement stage. Extensive experiments on multiple benchmarks demonstrate that MT-PCR outperforms Transformer-based and concurrent state-of-the-art methods in both accuracy and efficiency, significantly reducing while GPU memory usage and FLOPs.
LiloDriver: A Lifelong Learning Framework for Closed-loop Motion Planning in Long-tail Autonomous Driving Scenarios
May 22, 2025Recent advances in autonomous driving research towards motion planners that are robust, safe, and adaptive. However, existing rule-based and data-driven planners lack adaptability to long-tail scenarios, while knowledge-driven methods offer strong reasoning but face challenges in representation, control, and real-world evaluation. To address these challenges, we present LiloDriver, a lifelong learning framework for closed-loop motion planning in long-tail autonomous driving scenarios. By integrating large language models (LLMs) with a memory-augmented planner generation system, LiloDriver continuously adapts to new scenarios without retraining. It features a four-stage architecture including perception, scene encoding, memory-based strategy refinement, and LLM-guided reasoning. Evaluated on the nuPlan benchmark, LiloDriver achieves superior performance in both common and rare driving scenarios, outperforming static rule-based and learning-based planners. Our results highlight the effectiveness of combining structured memory and LLM reasoning to enable scalable, human-like motion planning in real-world autonomous driving. Our code is available at https://github.com/Hyan-Yao/LiloDriver.
Bounded and Uniform Energy-based Out-of-distribution Detection for Graphs
Apr 18, 2025Given the critical role of graphs in real-world applications and their high-security requirements, improving the ability of graph neural networks (GNNs) to detect out-of-distribution (OOD) data is an urgent research problem. The recent work GNNSAFE proposes a framework based on the aggregation of negative energy scores that significantly improves the performance of GNNs to detect node-level OOD data. However, our study finds that score aggregation among nodes is susceptible to extreme values due to the unboundedness of the negative energy scores and logit shifts, which severely limits the accuracy of GNNs in detecting node-level OOD data. In this paper, we propose NODESAFE: reducing the generation of extreme scores of nodes by adding two optimization terms that make the negative energy scores bounded and mitigate the logit shift. Experimental results show that our approach dramatically improves the ability of GNNs to detect OOD data at the node level, e.g., in detecting OOD data induced by Structure Manipulation, the metric of FPR95 (lower is better) in scenarios without (with) OOD data exposure are reduced from the current SOTA by 28.4% (22.7%).
Two-Timescale Joint Transmit and Pinching Beamforming for Pinching-Antenna Systems
Apr 13, 2025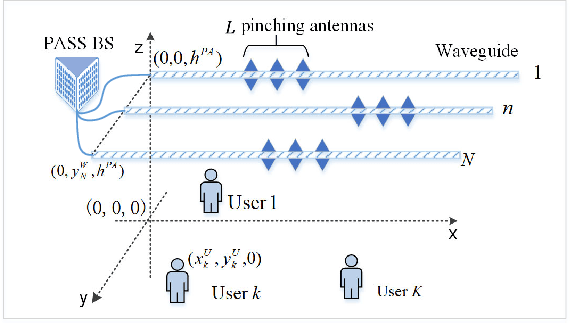
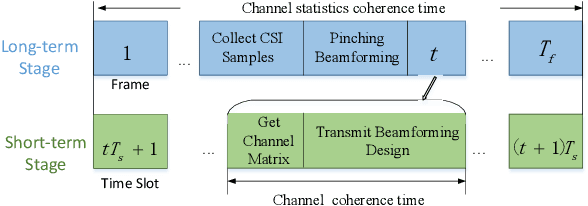
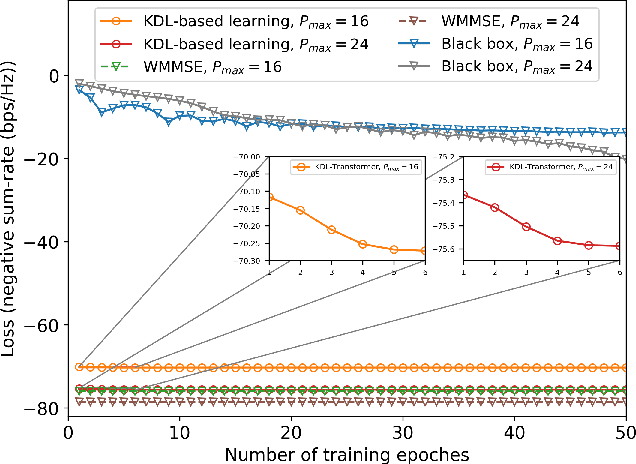
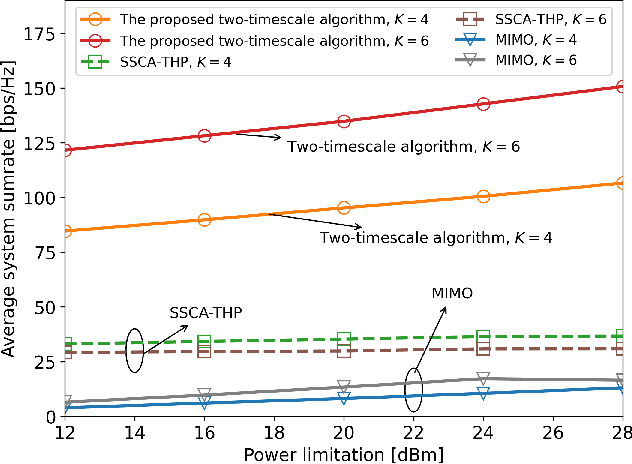
Pinching antenna systems (PASS) have been proposed as a revolutionary flexible antenna technology which facilitates line-of-sight links via numerous low-cost pinching antennas with adjustable activation positions over waveguides. This letter proposes a two-timescale joint transmit and pinching beamforming design for the maximization of sum rate of a PASS-based downlink multi-user multiple input single output system. A primal dual decomposition method is developed to decouple the two-timescale problem into two sub-problems: 1) A Karush-Kuhn-Tucker-guided dual learning-based approach is proposed to solve the short-term transmit beamforming design sub-problem; 2) The long-term pinching beamforming design sub-problem is tackled by adopting a stochastic successive convex approximation method. Simulation results demonstrate that the proposed two-timescale algorithm achieves a significant performance gain compared to other baselines.