 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVE: Efficient Verification of Data Erasure through Customized Perturbation in Approximate Unlearning
Feb 03, 2026Verifying whether the machine unlearning process has been properly executed is critical but remains underexplored. Some existing approaches propose unlearning verification methods based on backdooring techniques. However, these methods typically require participation in the model's initial training phase to backdoor the model for later verification, which is inefficient and impractical. In this paper, we propose an efficient verification of erasure method (EVE) for verifying machine unlearning without requiring involvement in the model's initial training process. The core idea is to perturb the unlearning data to ensure the model prediction of the specified samples will change before and after unlearning with perturbed data. The unlearning users can leverage the observation of the changes as a verification signal. Specifically, the perturbations are designed with two key objectives: ensuring the unlearning effect and altering the unlearned model's prediction of target samples. We formalize the perturbation generation as an adversarial optimization problem, solving it by aligning the unlearning gradient with the gradient of boundary change for target samples. We conducted extensive experiments, and the results show that EVE can verify machine unlearning without involving the model's initial training process, unlike backdoor-based methods. Moreover, EVE significantly outperforms state-of-the-art unlearning verification methods, offering significant speedup in efficiency while enhancing verification accuracy. The source code of EVE is released at \uline{https://anonymous.4open.science/r/EVE-C143}, providing a novel tool for verification of machine unlearning.
GeoIB: Geometry-Aware Information Bottleneck via Statistical-Manifold Compression
Feb 03, 2026Information Bottleneck (IB) is widely used, but in deep learning, it is usually implemented through tractable surrogates, such as variational bounds or neural mutual information (MI) estimators, rather than directly controlling the MI I(X;Z) itself. The looseness and estimator-dependent bias can make IB "compression" only indirectly controlled and optimization fragile. We revisit the IB problem through the lens of information geometry and propose a \textbf{Geo}metric \textbf{I}nformation \textbf{B}ottleneck (\textbf{GeoIB}) that dispenses with mutual information (MI) estimation. We show that I(X;Z) and I(Z;Y) admit exact projection forms as minimal Kullback-Leibler (KL) distances from the joint distributions to their respective independence manifolds. Guided by this view, GeoIB controls information compression with two complementary terms: (i) a distribution-level Fisher-Rao (FR) discrepancy, which matches KL to second order and is reparameterization-invariant; and (ii) a geometry-level Jacobian-Frobenius (JF) term that provides a local capacity-type upper bound on I(Z;X) by penalizing pullback volume expansion of the encoder. We further derive a natural-gradient optimizer consistent with the FR metric and prove that the standard additive natural-gradient step is first-order equivalent to the geodesic update. We conducted extensive experiments and observed that the GeoIB achieves a better trade-off between prediction accuracy and compression ratio in the information plane than the mainstream IB baselines on popular datasets. GeoIB improves invariance and optimization stability by unifying distributional and geometric regularization under a single bottleneck multiplier. The source code of GeoIB is released at "https://anonymous.4open.science/r/G-IB-0569".
Towards Fair Large Language Model-based Recommender Systems without Costly Retraining
Jan 24, 2026Large Language Models (LLMs) have revolutionized Recommender Systems (RS) through advanced generative user modeling. However, LLM-based RS (LLM-RS) often inadvertently perpetuates bias present in the training data, leading to severe fairness issues. Addressing these fairness problems in LLM-RS faces two significant challenges. 1) Existing debiasing methods, designed for specific bias types, lack the generality to handle diverse or emerging biases in real-world applications. 2) Debiasing methods relying on retraining are computationally infeasible given the massive parameter scale of LLMs. To overcome these challenges, we propose FUDLR (Fast Unified Debiasing for LLM-RS). The core idea is to reformulate the debiasing problem as an efficient machine unlearning task with two stages. First, FUDLR identifies bias-inducing samples to unlearn through a novel bias-agnostic mask, optimized to balance fairness improvement with accuracy preservation. Its bias-agnostic design allows adaptability to various or co-existing biases simply by incorporating different fairness metrics. Second, FUDLR performs efficient debiasing by estimating and removing the influence of identified samples on model parameters. Extensive experiments demonstrate that FUDLR effectively and efficiently improves fairness while preserving recommendation accuracy, offering a practical path toward socially responsible LLM-RS. The code and data are available at https://github.com/JinLi-i/FUDLR.
BlindU: Blind Machine Unlearning without Revealing Erasing Data
Jan 12, 2026Machine unlearning enables data holders to remove the contribution of their specified samples from trained models to protect their privacy. However, it is paradoxical that most unlearning methods require the unlearning requesters to firstly upload their data to the server as a prerequisite for unlearning. These methods are infeasible in many privacy-preserving scenarios where servers are prohibited from accessing users' data, such as federated learning (FL). In this paper, we explore how to implement unlearning under the condition of not uncovering the erasing data to the server. We propose \textbf{Blind Unlearning (BlindU)}, which carries out unlearning using compressed representations instead of original inputs. BlindU only involves the server and the unlearning user: the user locally generates privacy-preserving representations, and the server performs unlearning solely on these representations and their labels. For the FL model training, we employ the information bottleneck (IB) mechanism. The encoder of the IB-based FL model learns representations that distort maximum task-irrelevant information from inputs, allowing FL users to generate compressed representations locally. For effective unlearning using compressed representation, BlindU integrates two dedicated unlearning modules tailored explicitly for IB-based models and uses a multiple gradient descent algorithm to balance forgetting and utility retaining. While IB compression already provides protection for task-irrelevant information of inputs, to further enhance the privacy protection, we introduce a noise-free differential privacy (DP) masking method to deal with the raw erasing data before compressing. Theoretical analysis and extensive experimental results illustrate the superiority of BlindU in privacy protection and unlearning effectiveness compared with the best existing privacy-preserving unlearning benchmarks.
Automated CAD Modeling Sequence Generation from Text Descriptions via Transformer-Based Large Language Models
May 26, 2025Designing complex computer-aided design (CAD) models is often time-consuming due to challenges such as computational inefficiency and the difficulty of generating precise models. We propose a novel language-guided framework for industrial design automation to address these issues, integrating large language models (LLMs) with computer-automated design (CAutoD).Through this framework, CAD models are automatically generated from parameters and appearance descriptions, supporting the automation of design tasks during the detailed CAD design phase. Our approach introduces three key innovations: (1) a semi-automated data annotation pipeline that leverages LLMs and vision-language large models (VLLMs) to generate high-quality parameters and appearance descriptions; (2) a Transformer-based CAD generator (TCADGen) that predicts modeling sequences via dual-channel feature aggregation; (3) an enhanced CAD modeling generation model, called CADLLM, that is designed to refine the generated sequences by incorporating the confidence scores from TCADGen. Experimental results demonstrate that the proposed approach outperforms traditional methods in both accuracy and efficiency, providing a powerful tool for automating industrial workflows and generating complex CAD models from textual prompts. The code is available at https://jianxliao.github.io/cadllm-page/
SCU: An Efficient Machine Unlearning Scheme for Deep Learning Enabled Semantic Communications
Feb 27, 2025Deep learning (DL) enabled semantic communications leverage DL to train encoders and decoders (codecs) to extract and recover semantic information. However, most semantic training datasets contain personal private information. Such concerns call for enormous requirements for specified data erasure from semantic codecs when previous users hope to move their data from the semantic system. {Existing machine unlearning solutions remove data contribution from trained models, yet usually in supervised sole model scenarios. These methods are infeasible in semantic communications that often need to jointly train unsupervised encoders and decoders.} In this paper, we investigate the unlearning problem in DL-enabled semantic communications and propose a semantic communication unlearning (SCU) scheme to tackle the problem. {SCU includes two key components. Firstly,} we customize the joint unlearning method for semantic codecs, including the encoder and decoder, by minimizing mutual information between the learned semantic representation and the erased samples. {Secondly,} to compensate for semantic model utility degradation caused by unlearning, we propose a contrastive compensation method, which considers the erased data as the negative samples and the remaining data as the positive samples to retrain the unlearned semantic models contrastively. Theoretical analysis and extensive experimental results on three representative datasets demonstrate the effectiveness and efficiency of our proposed methods.
TAPE: Tailored Posterior Difference for Auditing of Machine Unlearning
Feb 27, 2025With the increasing prevalence of Web-based platforms handling vast amounts of user data, machine unlearning has emerged as a crucial mechanism to uphold users' right to be forgotten, enabling individuals to request the removal of their specified data from trained models. However, the auditing of machine unlearning processes remains significantly underexplored. Although some existing methods offer unlearning auditing by leveraging backdoors, these backdoor-based approaches are inefficient and impractical, as they necessitate involvement in the initial model training process to embed the backdoors. In this paper, we propose a TAilored Posterior diffErence (TAPE) method to provide unlearning auditing independently of original model training. We observe that the process of machine unlearning inherently introduces changes in the model, which contains information related to the erased data. TAPE leverages unlearning model differences to assess how much information has been removed through the unlearning operation. Firstly, TAPE mimics the unlearned posterior differences by quickly building unlearned shadow models based on first-order influence estimation. Secondly, we train a Reconstructor model to extract and evaluate the private information of the unlearned posterior differences to audit unlearning. Existing privacy reconstructing methods based on posterior differences are only feasible for model updates of a single sample. To enable the reconstruction effective for multi-sample unlearning requests, we propose two strategies, unlearned data perturbation and unlearned influence-based division, to augment the posterior difference. Extensive experimental results indicate the significant superiority of TAPE over the state-of-the-art unlearning verification methods, at least 4.5$\times$ efficiency speedup and supporting the auditing for broader unlearning scenarios.
Generating with Fairness: A Modality-Diffused Counterfactual Framework for Incomplete Multimodal Recommendations
Jan 21, 2025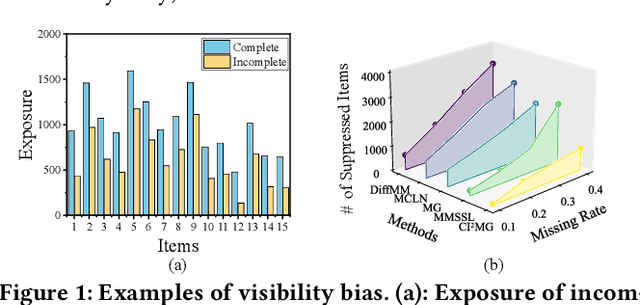
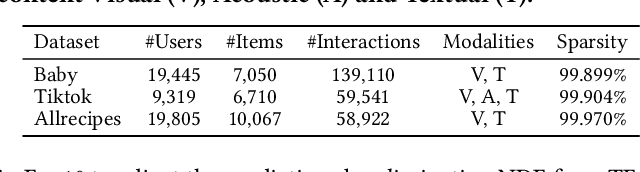
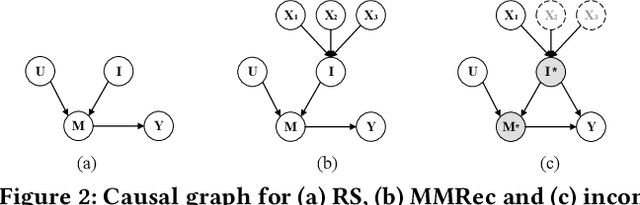
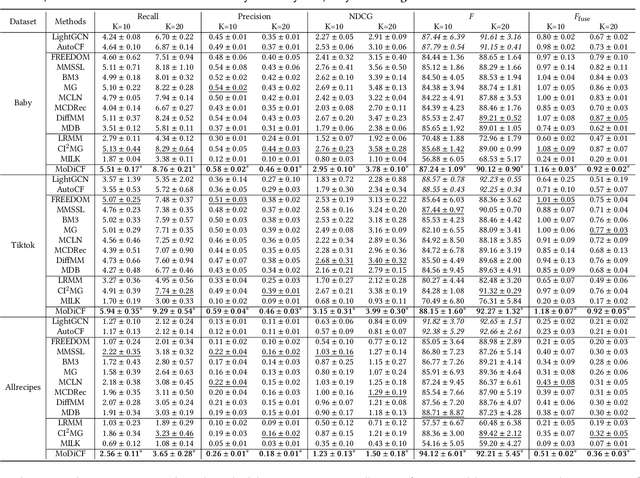
Incomplete scenario is a prevalent, practical, yet challenging setting in Multimodal Recommendations (MMRec), where some item modalities are missing due to various factors. Recently, a few efforts have sought to improve the recommendation accuracy by exploring generic structures from incomplete data. However, two significant gaps persist: 1) the difficulty in accurately generating missing data due to the limited ability to capture modality distributions; and 2) the critical but overlooked visibility bias, where items with missing modalities are more likely to be disregarded due to the prioritization of items' multimodal data over user preference alignment. This bias raises serious concerns about the fair treatment of items. To bridge these two gaps, we propose a novel Modality-Diffused Counterfactual (MoDiCF) framework for incomplete multimodal recommendations. MoDiCF features two key modules: a novel modality-diffused data completion module and a new counterfactual multimodal recommendation module. The former, equipped with a particularly designed multimodal generative framework, accurately generates and iteratively refines missing data from learned modality-specific distribution spaces. The latter, grounded in the causal perspective, effectively mitigates the negative causal effects of visibility bias and thus assures fairness in recommendations. Both modules work collaboratively to address the two aforementioned significant gaps for generating more accurate and fair results. Extensive experiments on three real-world datasets demonstrate the superior performance of MoDiCF in terms of both recommendation accuracy and fairness
Unleashing the Power of Continual Learning on Non-Centralized Devices: A Survey
Dec 18, 2024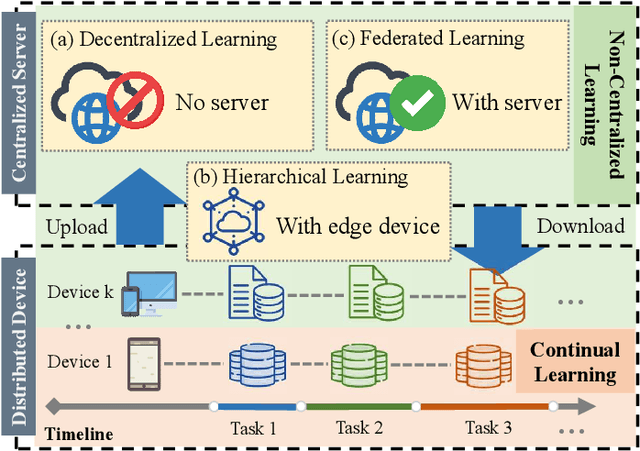
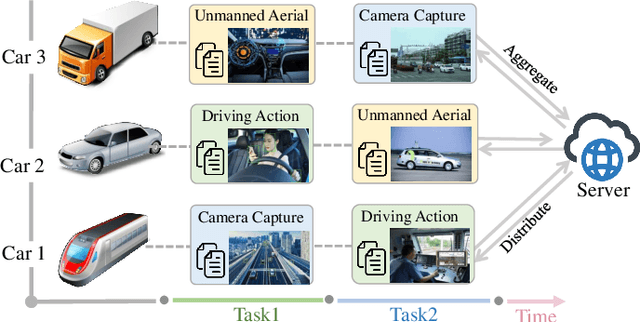
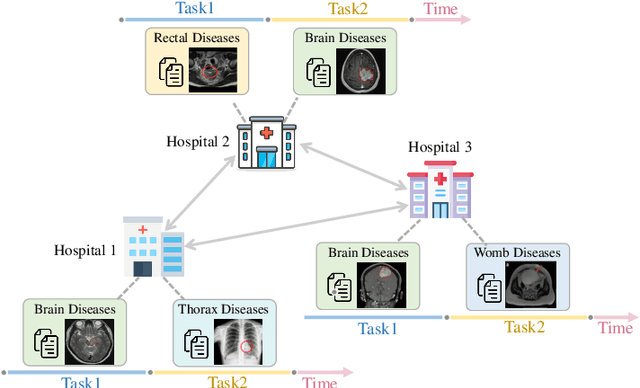
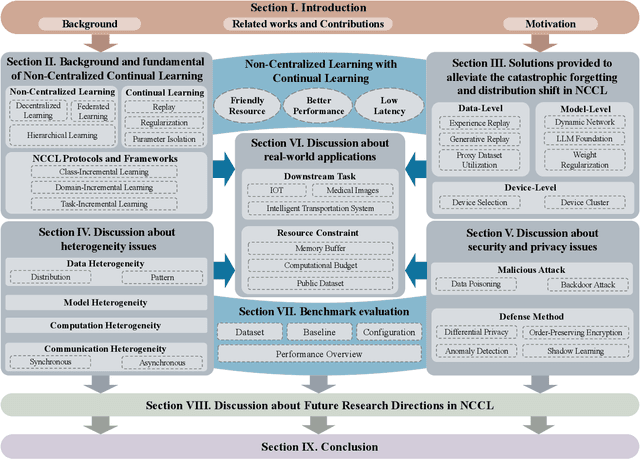
Non-Centralized Continual Learning (NCCL) has become an emerging paradigm for enabling distributed devices such as vehicles and servers to handle streaming data from a joint non-stationary environment. To achieve high reliability and scalability in deploying this paradigm in distributed systems, it is essential to conquer challenges stemming from both spatial and temporal dimensions, manifesting as distribution shifts, catastrophic forgetting, heterogeneity, and privacy issues. This survey focuses on a comprehensive examination of the development of the non-centralized continual learning algorithms and the real-world deployment across distributed devices. We begin with an introduction to the background and fundamentals of non-centralized learning and continual learning. Then, we review existing solutions from three levels to represent how existing techniques alleviate the catastrophic forgetting and distribution shift. Additionally, we delve into the various types of heterogeneity issues, security, and privacy attributes, as well as real-world applications across three prevalent scenarios. Furthermore, we establish a large-scale benchmark to revisit this problem and analyze the performance of the state-of-the-art NCCL approaches. Finally, we discuss the important challenges and future research directions in NCCL.
New Emerged Security and Privacy of Pre-trained Model: a Survey and Outlook
Nov 12, 2024



Thanks to the explosive growth of data and the development of computational resources, it is possible to build pre-trained models that can achieve outstanding performance on various tasks, such as neural language processing, computer vision, and more. Despite their powerful capabilities, pre-trained models have also sparked attention to the emerging security challenges associated with their real-world applications. Security and privacy issues, such as leaking privacy information and generating harmful responses, have seriously undermined users' confidence in these powerful models. Concerns are growing as model performance improves dramatically. Researchers are eager to explore the unique security and privacy issues that have emerged, their distinguishing factors, and how to defend against them. However, the current literature lacks a clear taxonomy of emerging attacks and defenses for pre-trained models, which hinders a high-level and comprehensive understanding of these questions. To fill the gap, we conduct a systematical survey on the security risks of pre-trained models, proposing a taxonomy of attack and defense methods based on the accessibility of pre-trained models' input and weights in various security test scenarios. This taxonomy categorizes attacks and defenses into No-Change, Input-Change, and Model-Change approaches. With the taxonomy analysis, we capture the unique security and privacy issues of pre-trained models, categorizing and summarizing existing security issues based on their characteristics. In addition, we offer a timely and comprehensive review of each category's strengths and limitations. Our survey concludes by highlighting potential new research opportunities in the security and privacy of pre-trained models.