 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLMR: Reinforcement Learning with Mixed Rewards for Creative Writing
Aug 28, 2025
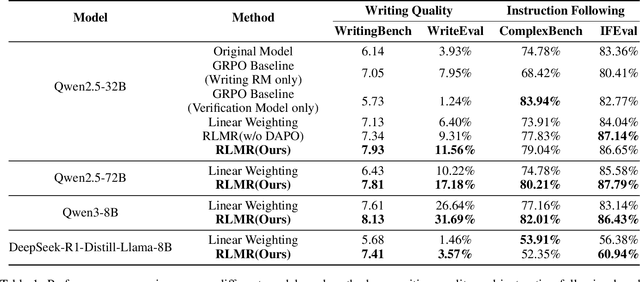
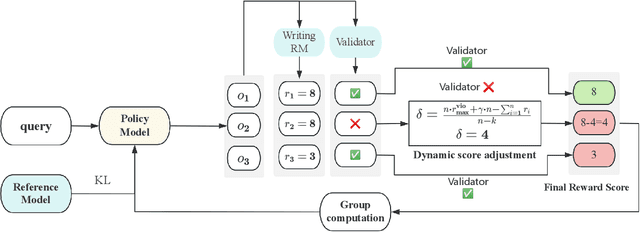
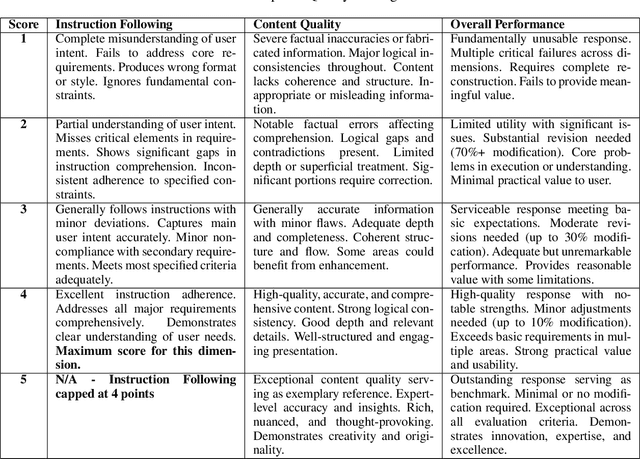
Large language models are extensively utilized in creative writing applications. Creative writing requires a balance between subjective writing quality (e.g., literariness and emotional expression) and objective constraint following (e.g., format requirements and word limits). Existing methods find it difficult to balance these two aspects: single reward strategies fail to improve both abilities simultaneously, while fixed-weight mixed-reward methods lack the ability to adapt to different writing scenarios. To address this problem, we propose Reinforcement Learning with Mixed Rewards (RLMR), utilizing a dynamically mixed reward system from a writing reward model evaluating subjective writing quality and a constraint verification model assessing objective constraint following. The constraint following reward weight is adjusted dynamically according to the writing quality within sampled groups, ensuring that samples violating constraints get negative advantage in GRPO and thus penalized during training, which is the key innovation of this proposed method. We conduct automated and manual evaluations across diverse model families from 8B to 72B parameters. Additionally, we construct a real-world writing benchmark named WriteEval for comprehensive evaluation. Results illustrate that our method achieves consistent improvements in both instruction following (IFEval from 83.36% to 86.65%) and writing quality (72.75% win rate in manual expert pairwise evaluations on WriteEval). To the best of our knowledge, RLMR is the first work to combine subjective preferences with objective verification in online RL training, providing an effective solution for multi-dimensional creative writing optimization.
Automated CAD Modeling Sequence Generation from Text Descriptions via Transformer-Based Large Language Models
May 26, 2025Designing complex computer-aided design (CAD) models is often time-consuming due to challenges such as computational inefficiency and the difficulty of generating precise models. We propose a novel language-guided framework for industrial design automation to address these issues, integrating large language models (LLMs) with computer-automated design (CAutoD).Through this framework, CAD models are automatically generated from parameters and appearance descriptions, supporting the automation of design tasks during the detailed CAD design phase. Our approach introduces three key innovations: (1) a semi-automated data annotation pipeline that leverages LLMs and vision-language large models (VLLMs) to generate high-quality parameters and appearance descriptions; (2) a Transformer-based CAD generator (TCADGen) that predicts modeling sequences via dual-channel feature aggregation; (3) an enhanced CAD modeling generation model, called CADLLM, that is designed to refine the generated sequences by incorporating the confidence scores from TCADGen. Experimental results demonstrate that the proposed approach outperforms traditional methods in both accuracy and efficiency, providing a powerful tool for automating industrial workflows and generating complex CAD models from textual prompts. The code is available at https://jianxliao.github.io/cadllm-page/
Scaling Spike-driven Transformer with Efficient Spike Firing Approximation Training
Nov 25, 2024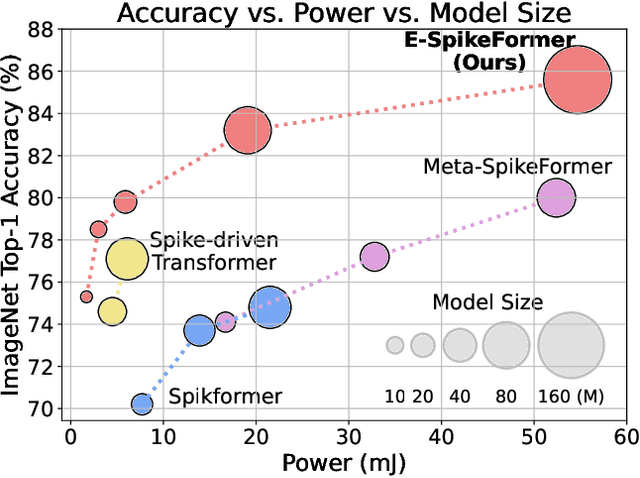
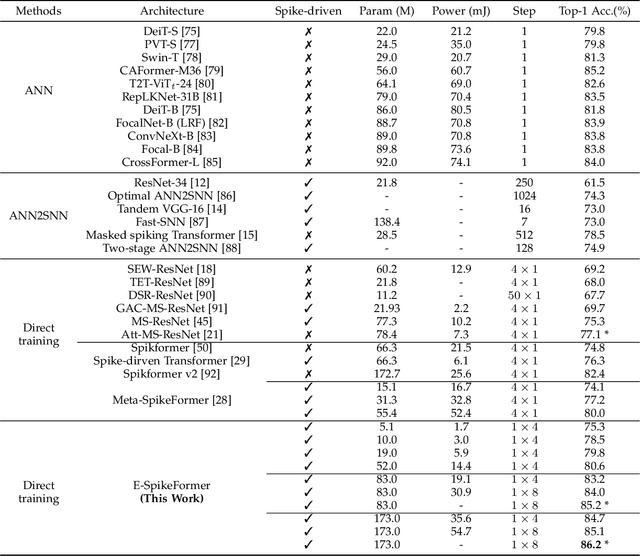
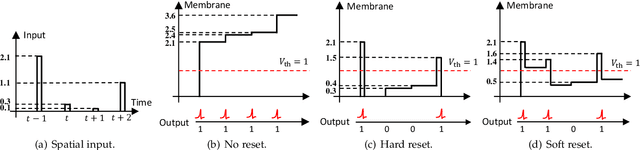
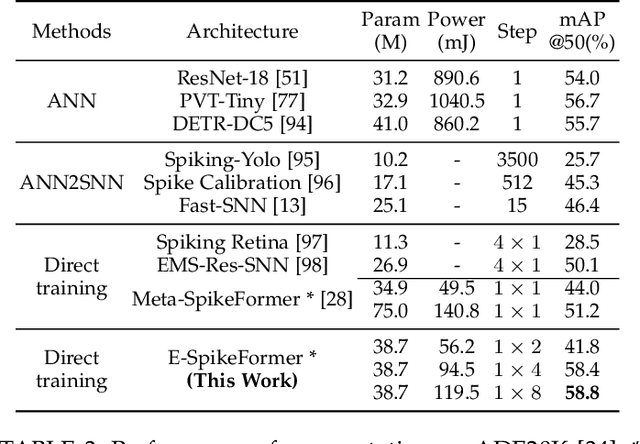
The ambition of brain-inspired Spiking Neural Networks (SNNs) is to become a low-power alternative to traditional Artificial Neural Networks (ANNs). This work addresses two major challenges in realizing this vision: the performance gap between SNNs and ANNs, and the high training costs of SNNs. We identify intrinsic flaws in spiking neurons caused by binary firing mechanisms and propose a Spike Firing Approximation (SFA) method using integer training and spike-driven inference. This optimizes the spike firing pattern of spiking neurons, enhancing efficient training, reducing power consumption, improving performance, enabling easier scaling, and better utilizing neuromorphic chips. We also develop an efficient spike-driven Transformer architecture and a spike-masked autoencoder to prevent performance degradation during SNN scaling. On ImageNet-1k, we achieve state-of-the-art top-1 accuracy of 78.5\%, 79.8\%, 84.0\%, and 86.2\% with models containing 10M, 19M, 83M, and 173M parameters, respectively. For instance, the 10M model outperforms the best existing SNN by 7.2\% on ImageNet, with training time acceleration and inference energy efficiency improved by 4.5$\times$ and 3.9$\times$, respectively. We validate the effectiveness and efficiency of the proposed method across various tasks, including object detection, semantic segmentation, and neuromorphic vision tasks. This work enables SNNs to match ANN performance while maintaining the low-power advantage, marking a significant step towards SNNs as a general visual backbone. Code is available at https://github.com/BICLab/Spike-Driven-Transformer-V3.
Benchmarking Neural Decoding Backbones towards Enhanced On-edge iBCI Applications
Jun 08, 2024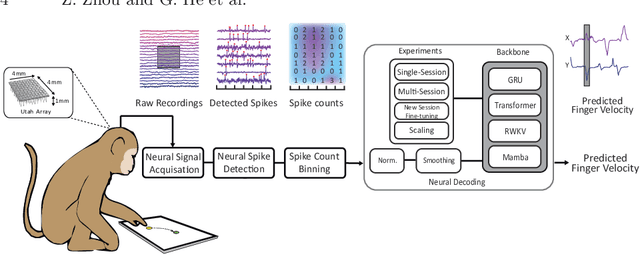
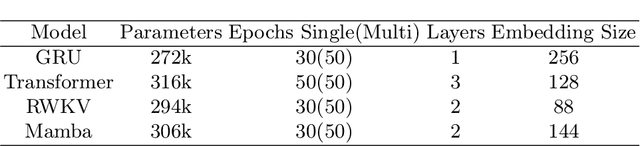
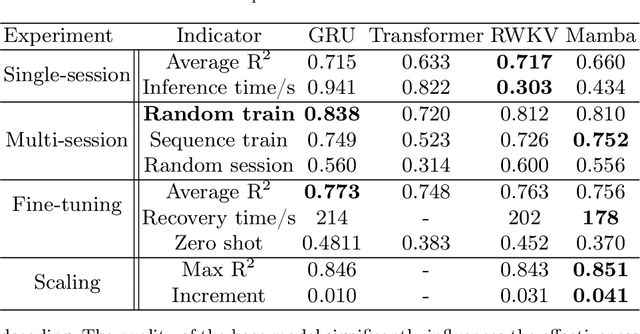
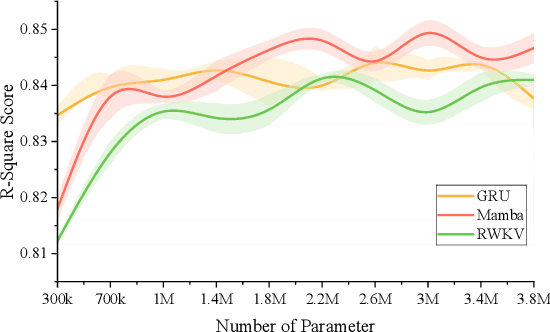
Traditional invasive Brain-Computer Interfaces (iBCIs) typically depend on neural decoding processes conducted on workstations within laboratory settings, which prevents their everyday usage. Implementing these decoding processes on edge devices, such as the wearables, introduces considerable challenges related to computational demands, processing speed, and maintaining accuracy. This study seeks to identify an optimal neural decoding backbone that boasts robust performance and swift inference capabilities suitable for edge deployment. We executed a series of neural decoding experiments involving nonhuman primates engaged in random reaching tasks, evaluating four prospective models, Gated Recurrent Unit (GRU), Transformer, Receptance Weighted Key Value (RWKV), and Selective State Space model (Mamba), across several metrics: single-session decoding, multi-session decoding, new session fine-tuning, inference speed, calibration speed, and scalability. The findings indicate that although the GRU model delivers sufficient accuracy, the RWKV and Mamba models are preferable due to their superior inference and calibration speeds. Additionally, RWKV and Mamba comply with the scaling law, demonstrating improved performance with larger data sets and increased model sizes, whereas GRU shows less pronounced scalability, and the Transformer model requires computational resources that scale prohibitively. This paper presents a thorough comparative analysis of the four models in various scenarios. The results are pivotal in pinpointing an optimal backbone that can handle increasing data volumes and is viable for edge implementation. This analysis provides essential insights for ongoing research and practical applications in the field.
Weakly-Supervised Action Localization by Hierarchically-structured Latent Attention Modeling
Aug 19, 2023Weakly-supervised action localization aims to recognize and localize action instancese in untrimmed videos with only video-level labels. Most existing models rely on multiple instance learning(MIL), where the predictions of unlabeled instances are supervised by classifying labeled bags. The MIL-based methods are relatively well studied with cogent performance achieved on classification but not on localization. Generally, they locate temporal regions by the video-level classification but overlook the temporal variations of feature semantics. To address this problem, we propose a novel attention-based hierarchically-structured latent model to learn the temporal variations of feature semantics. Specifically, our model entails two components, the first is an unsupervised change-points detection module that detects change-points by learning the latent representations of video features in a temporal hierarchy based on their rates of change, and the second is an attention-based classification model that selects the change-points of the foreground as the boundaries. To evaluate the effectiveness of our model, we conduct extensive experiments on two benchmark datasets, THUMOS-14 and ActivityNet-v1.3. The experiments show that our method outperforms current state-of-the-art methods, and even achieves comparable performance with fully-supervised methods.
Efficient Deep Spiking Multi-Layer Perceptrons with Multiplication-Free Inference
Jun 21, 2023



Advancements in adapting deep convolution architectures for Spiking Neural Networks (SNNs) have significantly enhanced image classification performance and reduced computational burdens. However, the inability of Multiplication-Free Inference (MFI) to harmonize with attention and transformer mechanisms, which are critical to superior performance on high-resolution vision tasks, imposes limitations on these gains. To address this, our research explores a new pathway, drawing inspiration from the progress made in Multi-Layer Perceptrons (MLPs). We propose an innovative spiking MLP architecture that uses batch normalization to retain MFI compatibility and introduces a spiking patch encoding layer to reinforce local feature extraction capabilities. As a result, we establish an efficient multi-stage spiking MLP network that effectively blends global receptive fields with local feature extraction for comprehensive spike-based computation. Without relying on pre-training or sophisticated SNN training techniques, our network secures a top-1 accuracy of 66.39% on the ImageNet-1K dataset, surpassing the directly trained spiking ResNet-34 by 2.67%. Furthermore, we curtail computational costs, model capacity, and simulation steps. An expanded version of our network challenges the performance of the spiking VGG-16 network with a 71.64% top-1 accuracy, all while operating with a model capacity 2.1 times smaller. Our findings accentuate the potential of our deep SNN architecture in seamlessly integrating global and local learning abilities. Interestingly, the trained receptive field in our network mirrors the activity patterns of cortical cells.
Video Interpolation by Event-driven Anisotropic Adjustment of Optical Flow
Aug 19, 2022
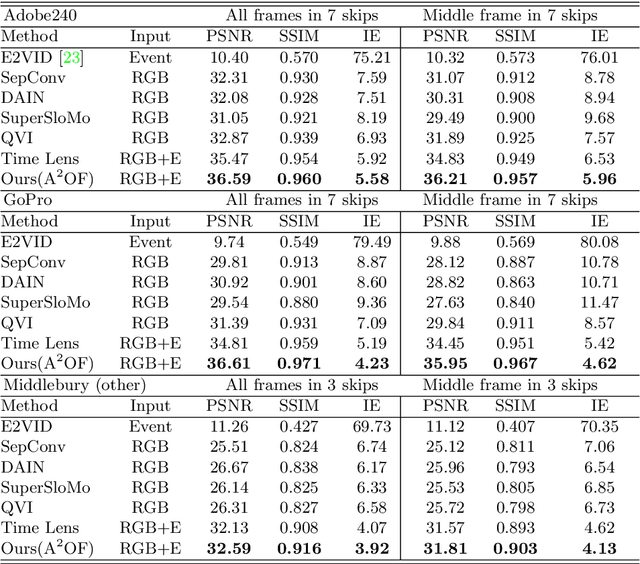
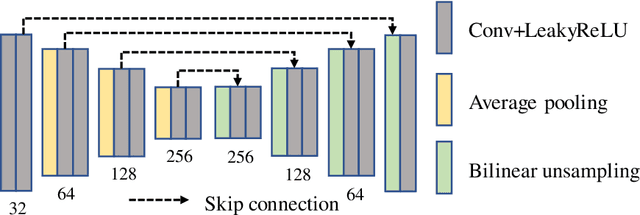
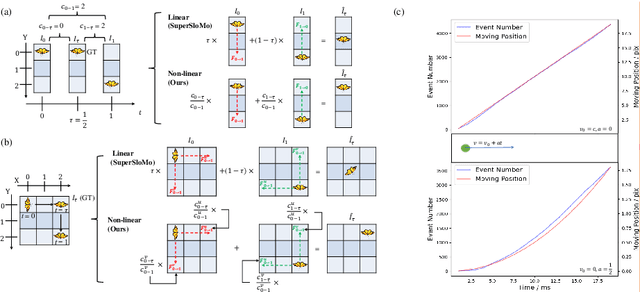
Video frame interpolation is a challenging task due to the ever-changing real-world scene. Previous methods often calculate the bi-directional optical flows and then predict the intermediate optical flows under the linear motion assumptions, leading to isotropic intermediate flow generation. Follow-up research obtained anisotropic adjustment through estimated higher-order motion information with extra frames. Based on the motion assumptions, their methods are hard to model the complicated motion in real scenes. In this paper, we propose an end-to-end training method A^2OF for video frame interpolation with event-driven Anisotropic Adjustment of Optical Flows. Specifically, we use events to generate optical flow distribution masks for the intermediate optical flow, which can model the complicated motion between two frames. Our proposed method outperforms the previous methods in video frame interpolation, taking supervised event-based video interpolation to a higher stage.
TimeReplayer: Unlocking the Potential of Event Cameras for Video Interpolation
Mar 25, 2022

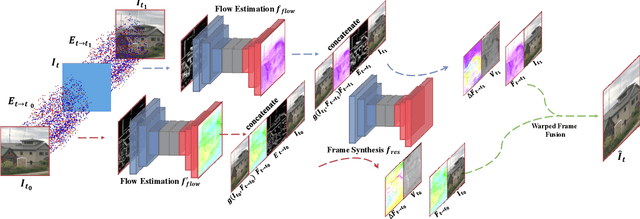
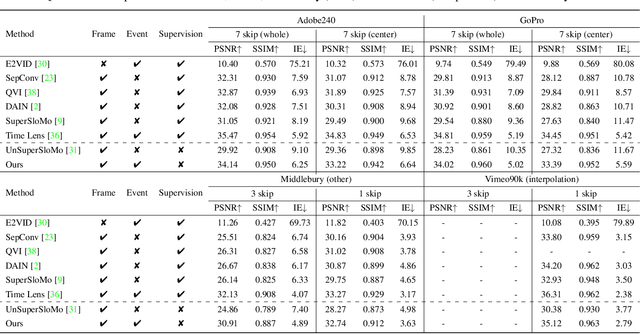
Recording fast motion in a high FPS (frame-per-second) requires expensive high-speed cameras. As an alternative, interpolating low-FPS videos from commodity cameras has attracted significant attention. If only low-FPS videos are available, motion assumptions (linear or quadratic) are necessary to infer intermediate frames, which fail to model complex motions. Event camera, a new camera with pixels producing events of brightness change at the temporal resolution of $\mu s$ $(10^{-6}$ second $)$, is a game-changing device to enable video interpolation at the presence of arbitrarily complex motion. Since event camera is a novel sensor, its potential has not been fulfilled due to the lack of processing algorithms. The pioneering work Time Lens introduced event cameras to video interpolation by designing optical devices to collect a large amount of paired training data of high-speed frames and events, which is too costly to scale. To fully unlock the potential of event cameras, this paper proposes a novel TimeReplayer algorithm to interpolate videos captured by commodity cameras with events. It is trained in an unsupervised cycle-consistent style, canceling the necessity of high-speed training data and bringing the additional ability of video extrapolation. Its state-of-the-art results and demo videos in supplementary reveal the promising future of event-based vision.