 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Sep 11, 2025Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by pre-training a large-scale Vision-Language Model (VLM) on robotic data. While this approach greatly enhances performance, it also incurs significant training costs. In this paper, we investigate how to effectively bridge vision-language (VL) representations to action (A). We introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale VLMs and extensive pre-training. To this end, we first systematically analyze the effectiveness of various VL conditions and present key findings on which conditions are essential for bridging perception and action spaces. Based on these insights, we propose a lightweight Policy module with Bridge Attention, which autonomously injects the optimal condition into the action space. In this way, our method achieves high performance using only a 0.5B-parameter backbone, without any robotic data pre-training. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that VLA-Adapter not only achieves state-of-the-art level performance, but also offers the fast inference speed reported to date. Furthermore, thanks to the proposed advanced bridging paradigm, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, greatly lowering the barrier to deploying the VLA model. Project page: https://vla-adapter.github.io/.
VibeVoice Technical Report
Aug 26, 2025This report presents VibeVoice, a novel model designed to synthesize long-form speech with multiple speakers by employing next-token diffusion, which is a unified method for modeling continuous data by autoregressively generating latent vectors via diffusion. To enable this, we introduce a novel continuous speech tokenizer that, when compared to the popular Encodec model, improves data compression by 80 times while maintaining comparable performance. The tokenizer effectively preserves audio fidelity while significantly boosting computational efficiency for processing long sequences. Thus, VibeVoice can synthesize long-form speech for up to 90 minutes (in a 64K context window length) with a maximum of 4 speakers, capturing the authentic conversational ``vibe'' and surpassing open-source and proprietary dialogue models.
Maximizing Asynchronicity in Event-based Neural Networks
May 16, 2025Event cameras deliver visual data with high temporal resolution, low latency, and minimal redundancy, yet their asynchronous, sparse sequential nature challenges standard tensor-based machine learning (ML). While the recent asynchronous-to-synchronous (A2S) paradigm aims to bridge this gap by asynchronously encoding events into learned representations for ML pipelines, existing A2S approaches often sacrifice representation expressivity and generalizability compared to dense, synchronous methods. This paper introduces EVA (EVent Asynchronous representation learning), a novel A2S framework to generate highly expressive and generalizable event-by-event representations. Inspired by the analogy between events and language, EVA uniquely adapts advances from language modeling in linear attention and self-supervised learning for its construction. In demonstration, EVA outperforms prior A2S methods on recognition tasks (DVS128-Gesture and N-Cars), and represents the first A2S framework to successfully master demanding detection tasks, achieving a remarkable 47.7 mAP on the Gen1 dataset. These results underscore EVA's transformative potential for advancing real-time event-based vision applications.
Multimodal Latent Language Modeling with Next-Token Diffusion
Dec 11, 2024



Multimodal generative models require a unified approach to handle both discrete data (e.g., text and code) and continuous data (e.g., image, audio, video). In this work, we propose Latent Language Modeling (LatentLM), which seamlessly integrates continuous and discrete data using causal Transformers. Specifically, we employ a variational autoencoder (VAE) to represent continuous data as latent vectors and introduce next-token diffusion for autoregressive generation of these vectors. Additionally, we develop $\sigma$-VAE to address the challenges of variance collapse, which is crucial for autoregressive modeling. Extensive experiments demonstrate the effectiveness of LatentLM across various modalities. In image generation, LatentLM surpasses Diffusion Transformers in both performance and scalability. When integrated into multimodal large language models, LatentLM provides a general-purpose interface that unifies multimodal generation and understanding. Experimental results show that LatentLM achieves favorable performance compared to Transfusion and vector quantized models in the setting of scaling up training tokens. In text-to-speech synthesis, LatentLM outperforms the state-of-the-art VALL-E 2 model in speaker similarity and robustness, while requiring 10x fewer decoding steps. The results establish LatentLM as a highly effective and scalable approach to advance large multimodal models.
RedStone: Curating General, Code, Math, and QA Data for Large Language Models
Dec 04, 2024
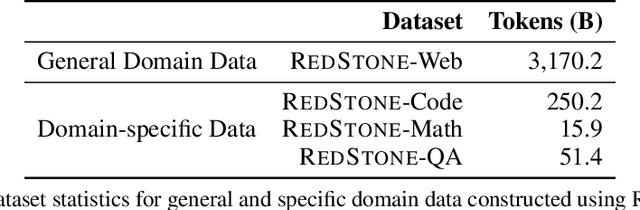
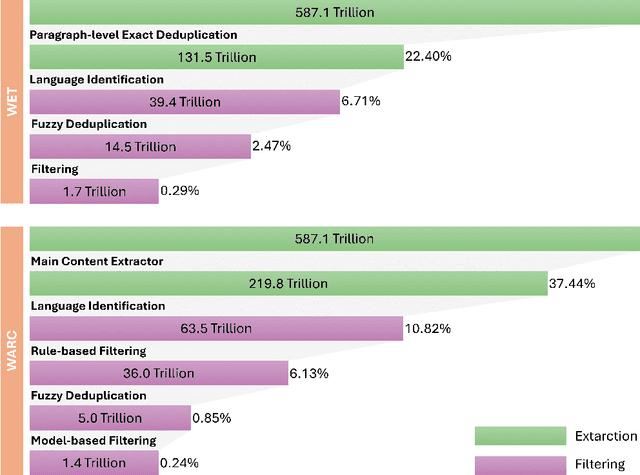
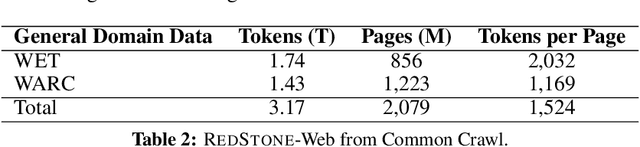
Pre-training Large Language Models (LLMs) on high-quality, meticulously curated datasets is widely recognized as critical for enhancing their performance and generalization capabilities. This study explores the untapped potential of Common Crawl as a comprehensive and flexible resource for pre-training LLMs, addressing both general-purpose language understanding and specialized domain knowledge. We introduce RedStone, an innovative and scalable pipeline engineered to extract and process data from Common Crawl, facilitating the creation of extensive and varied pre-training datasets. Unlike traditional datasets, which often require expensive curation and domain-specific expertise, RedStone leverages the breadth of Common Crawl to deliver datasets tailored to a wide array of domains. In this work, we exemplify its capability by constructing pre-training datasets across multiple fields, including general language understanding, code, mathematics, and question-answering tasks. The flexibility of RedStone allows for easy adaptation to other specialized domains, significantly lowering the barrier to creating valuable domain-specific datasets. Our findings demonstrate that Common Crawl, when harnessed through effective pipelines like RedStone, can serve as a rich, renewable source of pre-training data, unlocking new avenues for domain adaptation and knowledge discovery in LLMs. This work also underscores the importance of innovative data acquisition strategies and highlights the role of web-scale data as a powerful resource in the continued evolution of LLMs. RedStone code and data samples will be publicly available at \url{https://aka.ms/redstone}.
LICM: Effective and Efficient Long Interest Chain Modeling for News Recommendation
Aug 01, 2024



Accurately recommending personalized candidate news articles to users has always been the core challenge of news recommendation system. News recommendations often require modeling of user interests to match candidate news. Recent efforts have primarily focused on extract local subgraph information, the lack of a comprehensive global news graph extraction has hindered the ability to utilize global news information collaboratively among similar users. To overcome these limitations, we propose an effective and efficient Long Interest Chain Modeling for News Recommendation(LICM), which combines neighbor interest with long-chain interest distilled from a global news click graph based on the collaborative of similar users to enhance news recommendation. For a global news graph based on the click history of all users, long chain interest generated from it can better utilize the high-dimensional information within it, enhancing the effectiveness of collaborative recommendations. We therefore design a comprehensive selection mechanism and interest encoder to obtain long-chain interest from the global graph. Finally, we use a gated network to integrate long-chain information with neighbor information to achieve the final user representation. Experiment results on real-world datasets validate the effectiveness and efficiency of our model to improve the performance of news recommendation.
You Only Cache Once: Decoder-Decoder Architectures for Language Models
May 08, 2024We introduce a decoder-decoder architecture, YOCO, for large language models, which only caches key-value pairs once. It consists of two components, i.e., a cross-decoder stacked upon a self-decoder. The self-decoder efficiently encodes global key-value (KV) caches that are reused by the cross-decoder via cross-attention. The overall model behaves like a decoder-only Transformer, although YOCO only caches once. The design substantially reduces GPU memory demands, yet retains global attention capability. Additionally, the computation flow enables prefilling to early exit without changing the final output, thereby significantly speeding up the prefill stage. Experimental results demonstrate that YOCO achieves favorable performance compared to Transformer in various settings of scaling up model size and number of training tokens. We also extend YOCO to 1M context length with near-perfect needle retrieval accuracy. The profiling results show that YOCO improves inference memory, prefill latency, and throughput by orders of magnitude across context lengths and model sizes. Code is available at https://aka.ms/YOCO.
Multi-Head Mixture-of-Experts
Apr 23, 2024Sparse Mixtures of Experts (SMoE) scales model capacity without significant increases in training and inference costs, but exhibits the following two issues: (1) Low expert activation, where only a small subset of experts are activated for optimization. (2) Lacking fine-grained analytical capabilities for multiple semantic concepts within individual tokens. We propose Multi-Head Mixture-of-Experts (MH-MoE), which employs a multi-head mechanism to split each token into multiple sub-tokens. These sub-tokens are then assigned to and processed by a diverse set of experts in parallel, and seamlessly reintegrated into the original token form. The multi-head mechanism enables the model to collectively attend to information from various representation spaces within different experts, while significantly enhances expert activation, thus deepens context understanding and alleviate overfitting. Moreover, our MH-MoE is straightforward to implement and decouples from other SMoE optimization methods, making it easy to integrate with other SMoE models for enhanced performance. Extensive experimental results across three tasks: English-focused language modeling, Multi-lingual language modeling and Masked multi-modality modeling tasks, demonstrate the effectiveness of MH-MoE.
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Feb 27, 2024Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.