 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIBEVOICE-ASR Technical Report
Jan 26, 2026This report presents VibeVoice-ASR, a general-purpose speech understanding framework built upon VibeVoice, designed to address the persistent challenges of context fragmentation and multi-speaker complexity in long-form audio (e.g., meetings, podcasts) that remain despite recent advancements in short-form speech recognition. Unlike traditional pipelined approaches that rely on audio chunking, VibeVoice-ASRsupports single-pass processing for up to 60 minutes of audio. It unifies Automatic Speech Recognition, Speaker Diarization, and Timestamping into a single end-to-end generation task. In addition, VibeVoice-ASR supports over 50 languages, requires no explicit language setting, and natively handles code-switching within and across utterances. Furthermore, we introduce a prompt-based context injection mechanism that allows users to supply customized conetxt, significantly improving accuracy on domain-specific terminology and polyphonic character disambiguation.
VibeVoice Technical Report
Aug 26, 2025This report presents VibeVoice, a novel model designed to synthesize long-form speech with multiple speakers by employing next-token diffusion, which is a unified method for modeling continuous data by autoregressively generating latent vectors via diffusion. To enable this, we introduce a novel continuous speech tokenizer that, when compared to the popular Encodec model, improves data compression by 80 times while maintaining comparable performance. The tokenizer effectively preserves audio fidelity while significantly boosting computational efficiency for processing long sequences. Thus, VibeVoice can synthesize long-form speech for up to 90 minutes (in a 64K context window length) with a maximum of 4 speakers, capturing the authentic conversational ``vibe'' and surpassing open-source and proprietary dialogue models.
RedStone: Curating General, Code, Math, and QA Data for Large Language Models
Dec 04, 2024
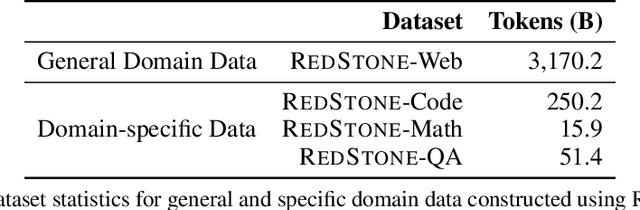
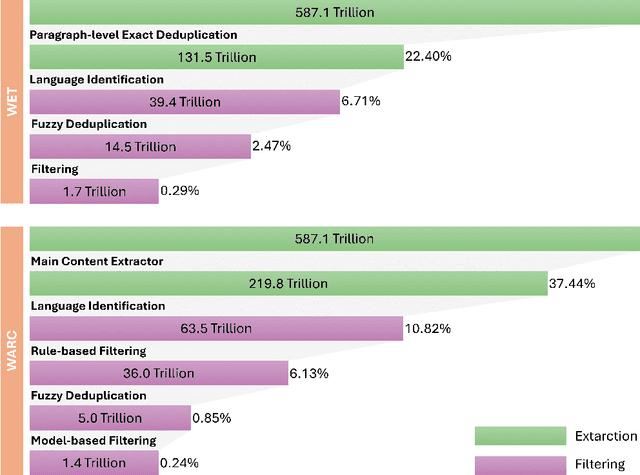
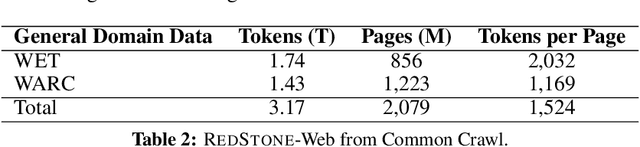
Pre-training Large Language Models (LLMs) on high-quality, meticulously curated datasets is widely recognized as critical for enhancing their performance and generalization capabilities. This study explores the untapped potential of Common Crawl as a comprehensive and flexible resource for pre-training LLMs, addressing both general-purpose language understanding and specialized domain knowledge. We introduce RedStone, an innovative and scalable pipeline engineered to extract and process data from Common Crawl, facilitating the creation of extensive and varied pre-training datasets. Unlike traditional datasets, which often require expensive curation and domain-specific expertise, RedStone leverages the breadth of Common Crawl to deliver datasets tailored to a wide array of domains. In this work, we exemplify its capability by constructing pre-training datasets across multiple fields, including general language understanding, code, mathematics, and question-answering tasks. The flexibility of RedStone allows for easy adaptation to other specialized domains, significantly lowering the barrier to creating valuable domain-specific datasets. Our findings demonstrate that Common Crawl, when harnessed through effective pipelines like RedStone, can serve as a rich, renewable source of pre-training data, unlocking new avenues for domain adaptation and knowledge discovery in LLMs. This work also underscores the importance of innovative data acquisition strategies and highlights the role of web-scale data as a powerful resource in the continued evolution of LLMs. RedStone code and data samples will be publicly available at \url{https://aka.ms/redstone}.
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023



We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.