 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel as a Game: On Numerical and Spatial Consistency for Generative Games
Mar 27, 2025Recent advances in generative models have significantly impacted game generation. However, despite producing high-quality graphics and adequately receiving player input, existing models often fail to maintain fundamental game properties such as numerical and spatial consistency. Numerical consistency ensures gameplay mechanics correctly reflect score changes and other quantitative elements, while spatial consistency prevents jarring scene transitions, providing seamless player experiences. In this paper, we revisit the paradigm of generative games to explore what truly constitutes a Model as a Game (MaaG) with a well-developed mechanism. We begin with an empirical study on ``Traveler'', a 2D game created by an LLM featuring minimalist rules yet challenging generative models in maintaining consistency. Based on the DiT architecture, we design two specialized modules: (1) a numerical module that integrates a LogicNet to determine event triggers, with calculations processed externally as conditions for image generation; and (2) a spatial module that maintains a map of explored areas, retrieving location-specific information during generation and linking new observations to ensure continuity. Experiments across three games demonstrate that our integrated modules significantly enhance performance on consistency metrics compared to baselines, while incurring minimal time overhead during inference.
RedStone: Curating General, Code, Math, and QA Data for Large Language Models
Dec 04, 2024
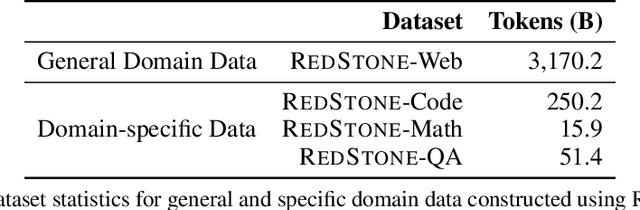
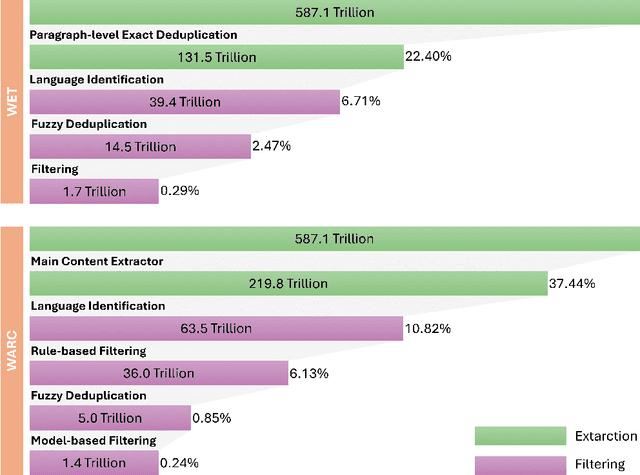
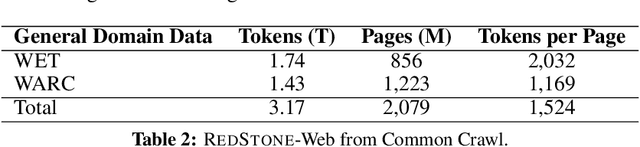
Pre-training Large Language Models (LLMs) on high-quality, meticulously curated datasets is widely recognized as critical for enhancing their performance and generalization capabilities. This study explores the untapped potential of Common Crawl as a comprehensive and flexible resource for pre-training LLMs, addressing both general-purpose language understanding and specialized domain knowledge. We introduce RedStone, an innovative and scalable pipeline engineered to extract and process data from Common Crawl, facilitating the creation of extensive and varied pre-training datasets. Unlike traditional datasets, which often require expensive curation and domain-specific expertise, RedStone leverages the breadth of Common Crawl to deliver datasets tailored to a wide array of domains. In this work, we exemplify its capability by constructing pre-training datasets across multiple fields, including general language understanding, code, mathematics, and question-answering tasks. The flexibility of RedStone allows for easy adaptation to other specialized domains, significantly lowering the barrier to creating valuable domain-specific datasets. Our findings demonstrate that Common Crawl, when harnessed through effective pipelines like RedStone, can serve as a rich, renewable source of pre-training data, unlocking new avenues for domain adaptation and knowledge discovery in LLMs. This work also underscores the importance of innovative data acquisition strategies and highlights the role of web-scale data as a powerful resource in the continued evolution of LLMs. RedStone code and data samples will be publicly available at \url{https://aka.ms/redstone}.
TextDiffuser-2: Unleashing the Power of Language Models for Text Rendering
Nov 28, 2023
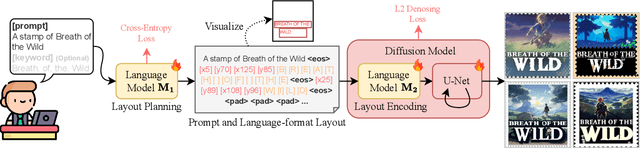
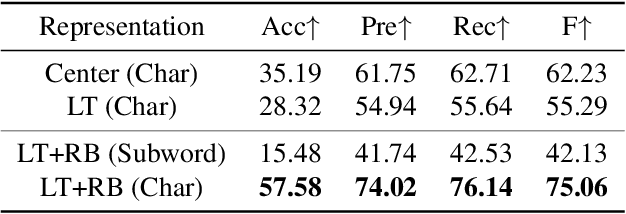
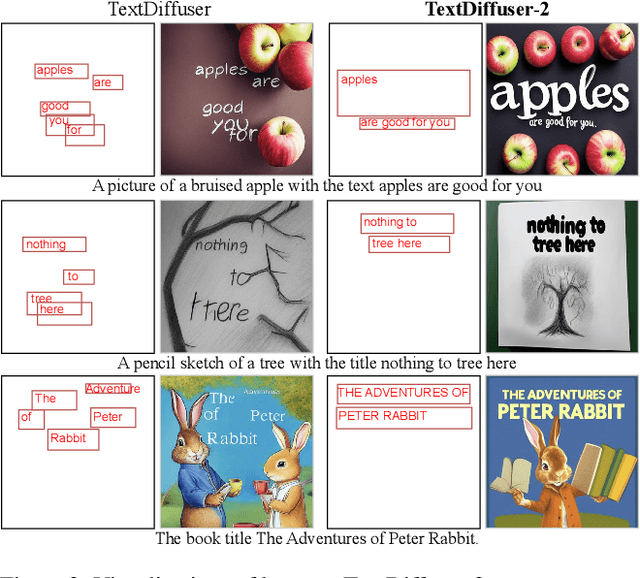
The diffusion model has been proven a powerful generative model in recent years, yet remains a challenge in generating visual text. Several methods alleviated this issue by incorporating explicit text position and content as guidance on where and what text to render. However, these methods still suffer from several drawbacks, such as limited flexibility and automation, constrained capability of layout prediction, and restricted style diversity. In this paper, we present TextDiffuser-2, aiming to unleash the power of language models for text rendering. Firstly, we fine-tune a large language model for layout planning. The large language model is capable of automatically generating keywords for text rendering and also supports layout modification through chatting. Secondly, we utilize the language model within the diffusion model to encode the position and texts at the line level. Unlike previous methods that employed tight character-level guidance, this approach generates more diverse text images. We conduct extensive experiments and incorporate user studies involving human participants as well as GPT-4V, validating TextDiffuser-2's capacity to achieve a more rational text layout and generation with enhanced diversity. The code and model will be available at \url{https://aka.ms/textdiffuser-2}.
Kosmos-2.5: A Multimodal Literate Model
Sep 20, 2023



We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
Sparkles: Unlocking Chats Across Multiple Images for Multimodal Instruction-Following Models
Aug 31, 2023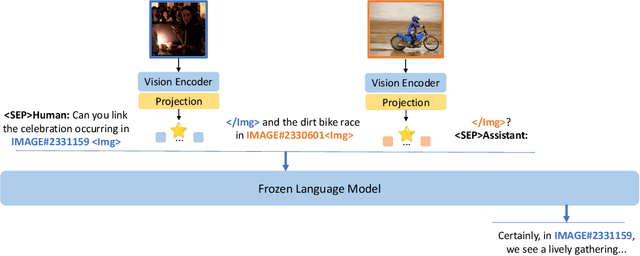


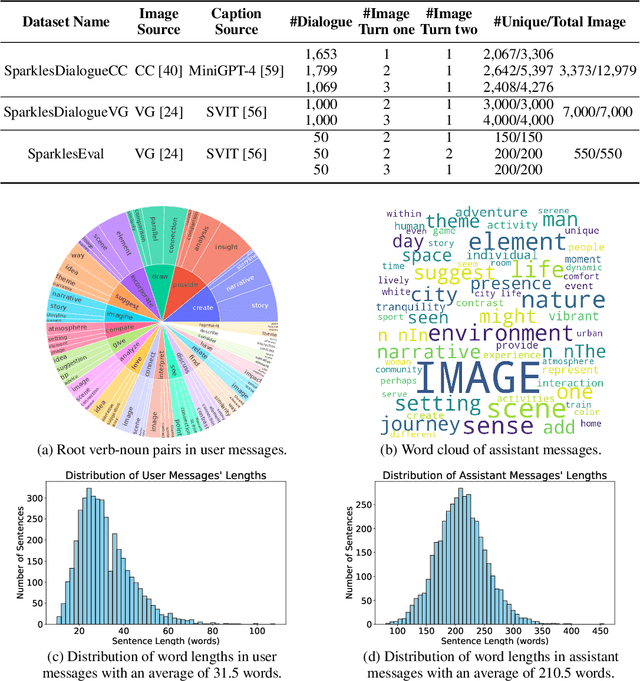
Large language models exhibit enhanced zero-shot performance on various tasks when fine-tuned with instruction-following data. Multimodal instruction-following models extend these capabilities by integrating both text and images. However, existing models such as MiniGPT-4 face challenges in maintaining dialogue coherence in scenarios involving multiple images. A primary reason is the lack of a specialized dataset for this critical application. To bridge these gaps, we present SparklesChat, a multimodal instruction-following model for open-ended dialogues across multiple images. To support the training, we introduce SparklesDialogue, the first machine-generated dialogue dataset tailored for word-level interleaved multi-image and text interactions. Furthermore, we construct SparklesEval, a GPT-assisted benchmark for quantitatively assessing a model's conversational competence across multiple images and dialogue turns. Our experiments validate the effectiveness of SparklesChat in understanding and reasoning across multiple images and dialogue turns. Specifically, SparklesChat outperformed MiniGPT-4 on established vision-and-language benchmarks, including the BISON binary image selection task and the NLVR2 visual reasoning task. Moreover, SparklesChat scored 8.56 out of 10 on SparklesEval, substantially exceeding MiniGPT-4's score of 3.91 and nearing GPT-4's score of 9.26. Qualitative evaluations further demonstrate SparklesChat's generality in handling real-world applications. All resources will be available at https://github.com/HYPJUDY/Sparkles.
TextDiffuser: Diffusion Models as Text Painters
May 24, 2023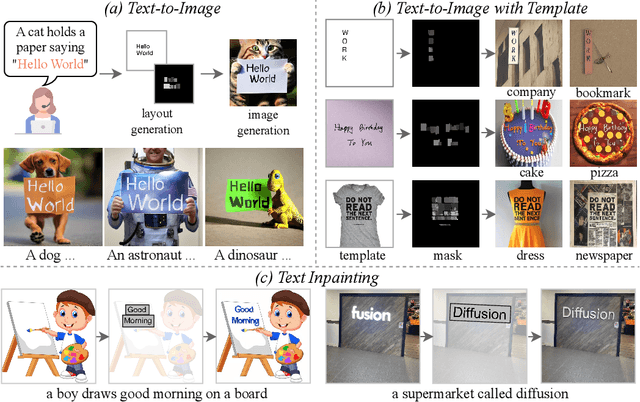
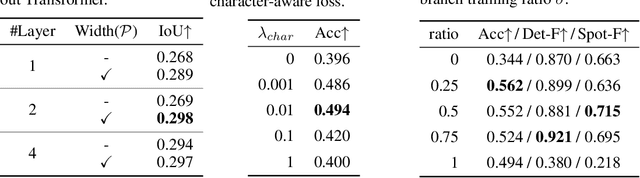
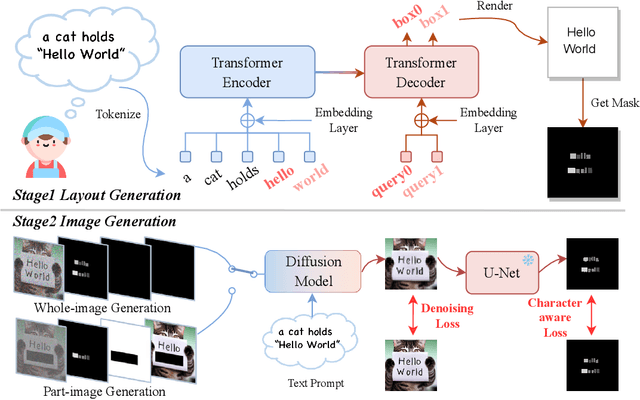
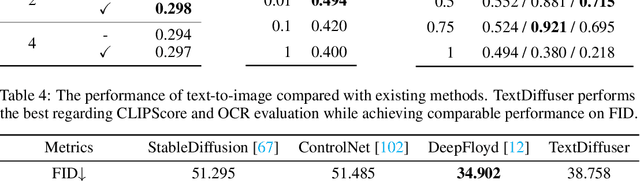
Diffusion models have gained increasing attention for their impressive generation abilities but currently struggle with rendering accurate and coherent text. To address this issue, we introduce TextDiffuser, focusing on generating images with visually appealing text that is coherent with backgrounds. TextDiffuser consists of two stages: first, a Transformer model generates the layout of keywords extracted from text prompts, and then diffusion models generate images conditioned on the text prompt and the generated layout. Additionally, we contribute the first large-scale text images dataset with OCR annotations, MARIO-10M, containing 10 million image-text pairs with text recognition, detection, and character-level segmentation annotations. We further collect the MARIO-Eval benchmark to serve as a comprehensive tool for evaluating text rendering quality. Through experiments and user studies, we show that TextDiffuser is flexible and controllable to create high-quality text images using text prompts alone or together with text template images, and conduct text inpainting to reconstruct incomplete images with text. The code, model, and dataset will be available at \url{https://aka.ms/textdiffuser}.
LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking
Apr 19, 2022
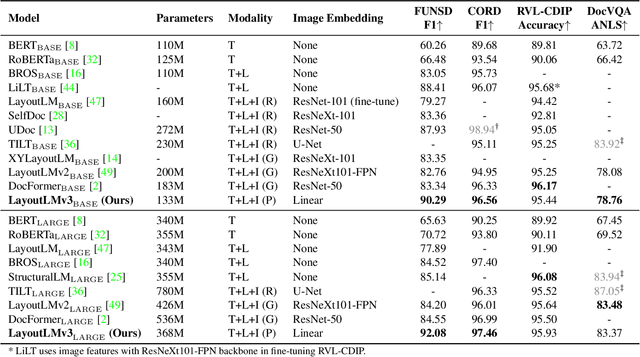
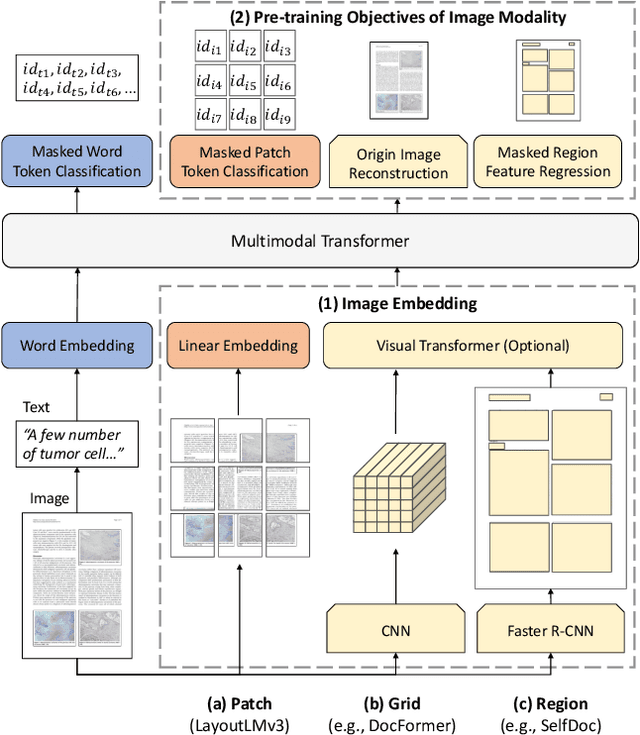
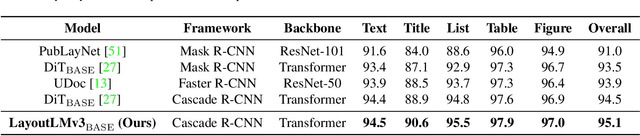
Self-supervised pre-training techniques have achieved remarkable progress in Document AI. Most multimodal pre-trained models use a masked language modeling objective to learn bidirectional representations on the text modality, but they differ in pre-training objectives for the image modality. This discrepancy adds difficulty to multimodal representation learning. In this paper, we propose LayoutLMv3 to pre-train multimodal Transformers for Document AI with unified text and image masking. Additionally, LayoutLMv3 is pre-trained with a word-patch alignment objective to learn cross-modal alignment by predicting whether the corresponding image patch of a text word is masked. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model for both text-centric and image-centric Document AI tasks. Experimental results show that LayoutLMv3 achieves state-of-the-art performance not only in text-centric tasks, including form understanding, receipt understanding, and document visual question answering, but also in image-centric tasks such as document image classification and document layout analysis. The code and models are publicly available at https://aka.ms/layoutlmv3.
A Picture is Worth a Thousand Words: A Unified System for Diverse Captions and Rich Images Generation
Oct 19, 2021

A creative image-and-text generative AI system mimics humans' extraordinary abilities to provide users with diverse and comprehensive caption suggestions, as well as rich image creations. In this work, we demonstrate such an AI creation system to produce both diverse captions and rich images. When users imagine an image and associate it with multiple captions, our system paints a rich image to reflect all captions faithfully. Likewise, when users upload an image, our system depicts it with multiple diverse captions. We propose a unified multi-modal framework to achieve this goal. Specifically, our framework jointly models image-and-text representations with a Transformer network, which supports rich image creation by accepting multiple captions as input. We consider the relations among input captions to encourage diversity in training and adopt a non-autoregressive decoding strategy to enable real-time inference. Based on these, our system supports both diverse captions and rich images generations. Our code is available online.
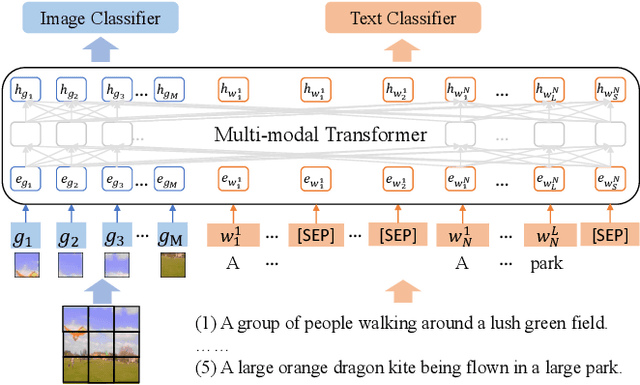
Unifying Multimodal Transformer for Bi-directional Image and Text Generation
Oct 19, 2021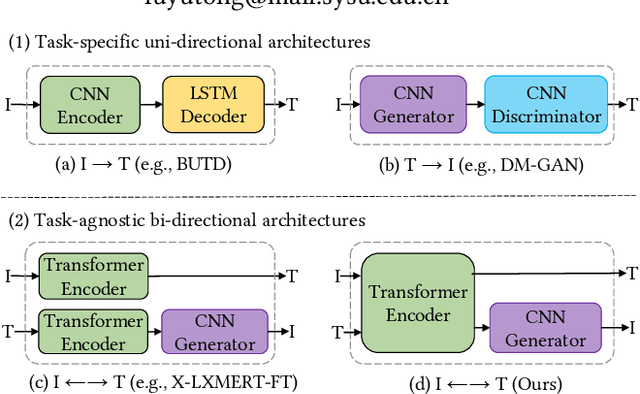
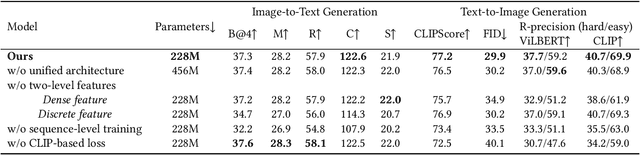
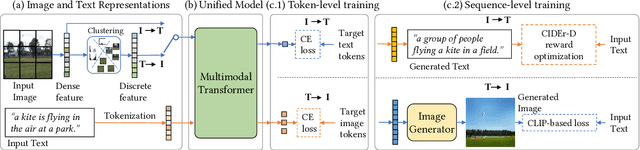
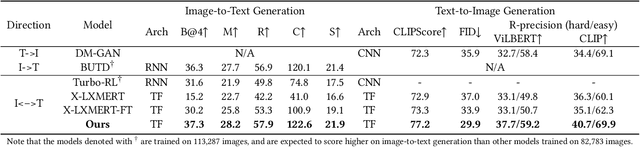
We study the joint learning of image-to-text and text-to-image generations, which are naturally bi-directional tasks. Typical existing works design two separate task-specific models for each task, which impose expensive design efforts. In this work, we propose a unified image-and-text generative framework based on a single multimodal model to jointly study the bi-directional tasks. We adopt Transformer as our unified architecture for its strong performance and task-agnostic design. Specifically, we formulate both tasks as sequence generation tasks, where we represent images and text as unified sequences of tokens, and the Transformer learns multimodal interactions to generate sequences. We further propose two-level granularity feature representations and sequence-level training to improve the Transformer-based unified framework. Experiments show that our approach significantly improves previous Transformer-based model X-LXMERT's FID from 37.0 to 29.9 (lower is better) for text-to-image generation, and improves CIDEr-D score from 100.9% to 122.6% for fine-tuned image-to-text generation on the MS-COCO dataset. Our code is available online.
Probing Inter-modality: Visual Parsing with Self-Attention for Vision-Language Pre-training
Jun 28, 2021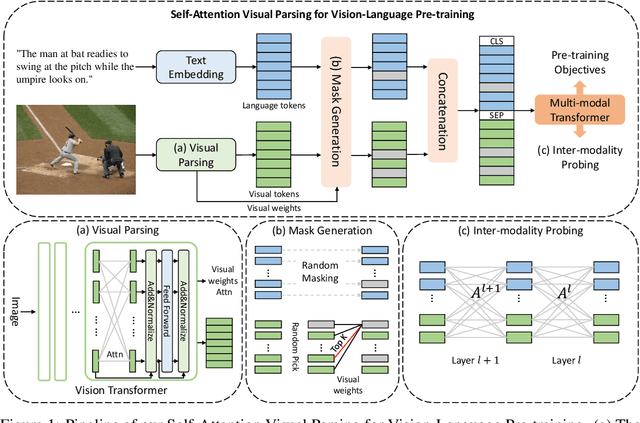
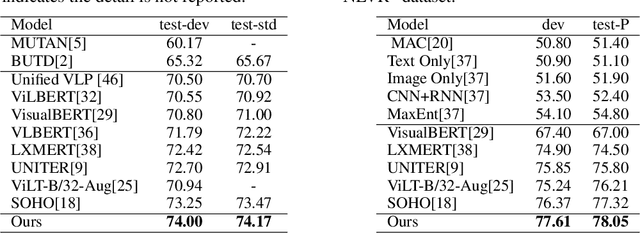

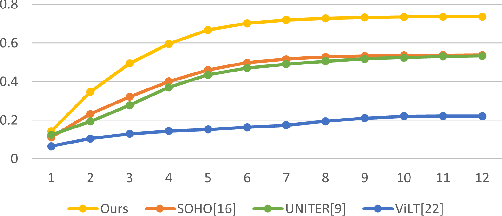
Vision-Language Pre-training (VLP) aims to learn multi-modal representations from image-text pairs and serves for downstream vision-language tasks in a fine-tuning fashion. The dominant VLP models adopt a CNN-Transformer architecture, which embeds images with a CNN, and then aligns images and text with a Transformer. Visual relationship between visual contents plays an important role in image understanding and is the basic for inter-modal alignment learning. However, CNNs have limitations in visual relation learning due to local receptive field's weakness in modeling long-range dependencies. Thus the two objectives of learning visual relation and inter-modal alignment are encapsulated in the same Transformer network. Such design might restrict the inter-modal alignment learning in the Transformer by ignoring the specialized characteristic of each objective. To tackle this, we propose a fully Transformer visual embedding for VLP to better learn visual relation and further promote inter-modal alignment. Specifically, we propose a metric named Inter-Modality Flow (IMF) to measure the interaction between vision and language modalities (i.e., inter-modality). We also design a novel masking optimization mechanism named Masked Feature Regression (MFR) in Transformer to further promote the inter-modality learning. To the best of our knowledge, this is the first study to explore the benefit of Transformer for visual feature learning in VLP. We verify our method on a wide range of vision-language tasks, including Image-Text Retrieval, Visual Question Answering (VQA), Visual Entailment and Visual Reasoning. Our approach not only outperforms the state-of-the-art VLP performance, but also shows benefits on the IMF metric.