 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedSAM-Agent: Empowering Interactive Medical Image Segmentation with Multi-turn Agentic Reinforcement Learning
Feb 03, 2026Medical image segmentation is evolving from task-specific models toward generalizable frameworks. Recent research leverages Multi-modal Large Language Models (MLLMs) as autonomous agents, employing reinforcement learning with verifiable reward (RLVR) to orchestrate specialized tools like the Segment Anything Model (SAM). However, these approaches often rely on single-turn, rigid interaction strategies and lack process-level supervision during training, which hinders their ability to fully exploit the dynamic potential of interactive tools and leads to redundant actions. To bridge this gap, we propose MedSAM-Agent, a framework that reformulates interactive segmentation as a multi-step autonomous decision-making process. First, we introduce a hybrid prompting strategy for expert-curated trajectory generation, enabling the model to internalize human-like decision heuristics and adaptive refinement strategies. Furthermore, we develop a two-stage training pipeline that integrates multi-turn, end-to-end outcome verification with a clinical-fidelity process reward design to promote interaction parsimony and decision efficiency. Extensive experiments across 6 medical modalities and 21 datasets demonstrate that MedSAM-Agent achieves state-of-the-art performance, effectively unifying autonomous medical reasoning with robust, iterative optimization. Code is available \href{https://github.com/CUHK-AIM-Group/MedSAM-Agent}{here}.
Dual-Phase LLM Reasoning: Self-Evolved Mathematical Frameworks
Jan 09, 2026In recent years, large language models (LLMs) have demonstrated significant potential in complex reasoning tasks like mathematical problem-solving. However, existing research predominantly relies on reinforcement learning (RL) frameworks while overlooking supervised fine-tuning (SFT) methods. This paper proposes a new two-stage training framework that enhances models' self-correction capabilities through self-generated long chain-of-thought (CoT) data. During the first stage, a multi-turn dialogue strategy guides the model to generate CoT data incorporating verification, backtracking, subgoal decomposition, and backward reasoning, with predefined rules filtering high-quality samples for supervised fine-tuning. The second stage employs a difficulty-aware rejection sampling mechanism to dynamically optimize data distribution, strengthening the model's ability to handle complex problems. The approach generates reasoning chains extended over 4 times longer while maintaining strong scalability, proving that SFT effectively activates models' intrinsic reasoning capabilities and provides a resource-efficient pathway for complex task optimization. Experimental results demonstrate performance improvements on mathematical benchmarks including GSM8K and MATH500, with the fine-tuned model achieving a substantial improvement on competition-level problems like AIME24. Code will be open-sourced.
R-4B: Incentivizing General-Purpose Auto-Thinking Capability in MLLMs via Bi-Mode Annealing and Reinforce Learning
Aug 28, 2025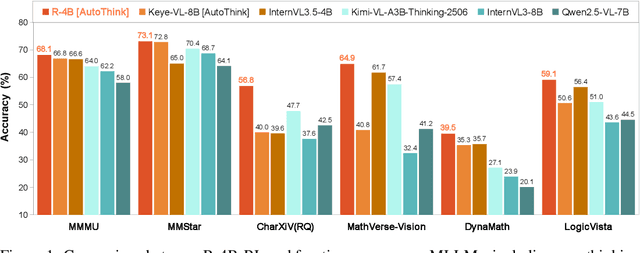
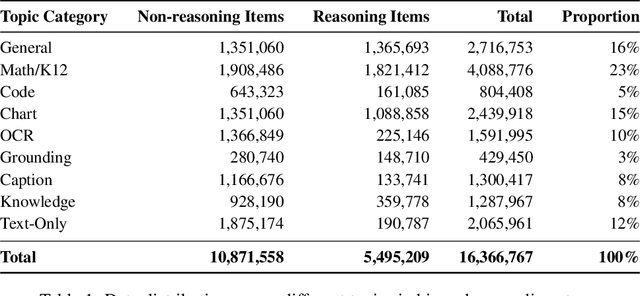
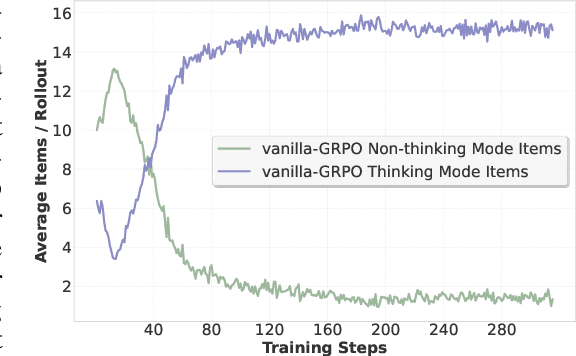
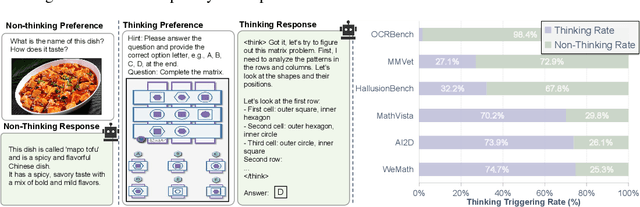
Multimodal Large Language Models (MLLMs) equipped with step-by-step thinking capabilities have demonstrated remarkable performance on complex reasoning problems. However, this thinking process is redundant for simple problems solvable without complex reasoning. To address this inefficiency, we propose R-4B, an auto-thinking MLLM, which can adaptively decide when to think based on problem complexity. The central idea of R-4B is to empower the model with both thinking and non-thinking capabilities using bi-mode annealing, and apply Bi-mode Policy Optimization~(BPO) to improve the model's accuracy in determining whether to activate the thinking process. Specifically, we first train the model on a carefully curated dataset spanning various topics, which contains samples from both thinking and non-thinking modes. Then it undergoes a second phase of training under an improved GRPO framework, where the policy model is forced to generate responses from both modes for each input query. Experimental results show that R-4B achieves state-of-the-art performance across 25 challenging benchmarks. It outperforms Qwen2.5-VL-7B in most tasks and achieves performance comparable to larger models such as Kimi-VL-A3B-Thinking-2506 (16B) on reasoning-intensive benchmarks with lower computational cost.
RBench-V: A Primary Assessment for Visual Reasoning Models with Multi-modal Outputs
May 22, 2025The rapid advancement of native multi-modal models and omni-models, exemplified by GPT-4o, Gemini, and o3, with their capability to process and generate content across modalities such as text and images, marks a significant milestone in the evolution of intelligence. Systematic evaluation of their multi-modal output capabilities in visual thinking processes (also known as multi-modal chain of thought, M-CoT) becomes critically important. However, existing benchmarks for evaluating multi-modal models primarily focus on assessing multi-modal inputs and text-only reasoning while neglecting the importance of reasoning through multi-modal outputs. In this paper, we present a benchmark, dubbed RBench-V, designed to assess models' vision-indispensable reasoning abilities. To construct RBench-V, we carefully hand-pick 803 questions covering math, physics, counting, and games. Unlike previous benchmarks that typically specify certain input modalities, RBench-V presents problems centered on multi-modal outputs, which require image manipulation such as generating novel images and constructing auxiliary lines to support the reasoning process. We evaluate numerous open- and closed-source models on RBench-V, including o3, Gemini 2.5 Pro, Qwen2.5-VL, etc. Even the best-performing model, o3, achieves only 25.8% accuracy on RBench-V, far below the human score of 82.3%, highlighting that current models struggle to leverage multi-modal reasoning. Data and code are available at https://evalmodels.github.io/rbenchv
R-Bench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
May 04, 2025Reasoning stands as a cornerstone of intelligence, enabling the synthesis of existing knowledge to solve complex problems. Despite remarkable progress, existing reasoning benchmarks often fail to rigorously evaluate the nuanced reasoning capabilities required for complex, real-world problemsolving, particularly in multi-disciplinary and multimodal contexts. In this paper, we introduce a graduate-level, multi-disciplinary, EnglishChinese benchmark, dubbed as Reasoning Bench (R-Bench), for assessing the reasoning capability of both language and multimodal models. RBench spans 1,094 questions across 108 subjects for language model evaluation and 665 questions across 83 subjects for multimodal model testing in both English and Chinese. These questions are meticulously curated to ensure rigorous difficulty calibration, subject balance, and crosslinguistic alignment, enabling the assessment to be an Olympiad-level multi-disciplinary benchmark. We evaluate widely used models, including OpenAI o1, GPT-4o, DeepSeek-R1, etc. Experimental results indicate that advanced models perform poorly on complex reasoning, especially multimodal reasoning. Even the top-performing model OpenAI o1 achieves only 53.2% accuracy on our multimodal evaluation. Data and code are made publicly available at here.
Mitigating Visual Forgetting via Take-along Visual Conditioning for Multi-modal Long CoT Reasoning
Mar 17, 2025Recent advancements in Large Language Models (LLMs) have demonstrated enhanced reasoning capabilities, evolving from Chain-of-Thought (CoT) prompting to advanced, product-oriented solutions like OpenAI o1. During our re-implementation of this model, we noticed that in multimodal tasks requiring visual input (e.g., geometry problems), Multimodal LLMs (MLLMs) struggle to maintain focus on the visual information, in other words, MLLMs suffer from a gradual decline in attention to visual information as reasoning progresses, causing text-over-relied outputs. To investigate this, we ablate image inputs during long-chain reasoning. Concretely, we truncate the reasoning process midway, then re-complete the reasoning process with the input image removed. We observe only a ~2% accuracy drop on MathVista's test-hard subset, revealing the model's textual outputs dominate the following reasoning process. Motivated by this, we propose Take-along Visual Conditioning (TVC), a strategy that shifts image input to critical reasoning stages and compresses redundant visual tokens via dynamic pruning. This methodology helps the model retain attention to the visual components throughout the reasoning. Our approach achieves state-of-the-art performance on average across five mathematical reasoning benchmarks (+3.4% vs previous sota), demonstrating the effectiveness of TVC in enhancing multimodal reasoning systems.
HiTVideo: Hierarchical Tokenizers for Enhancing Text-to-Video Generation with Autoregressive Large Language Models
Mar 14, 2025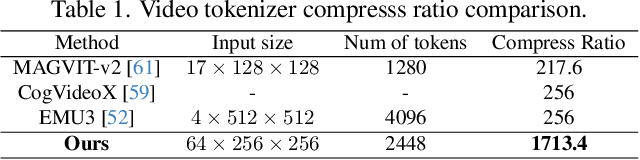
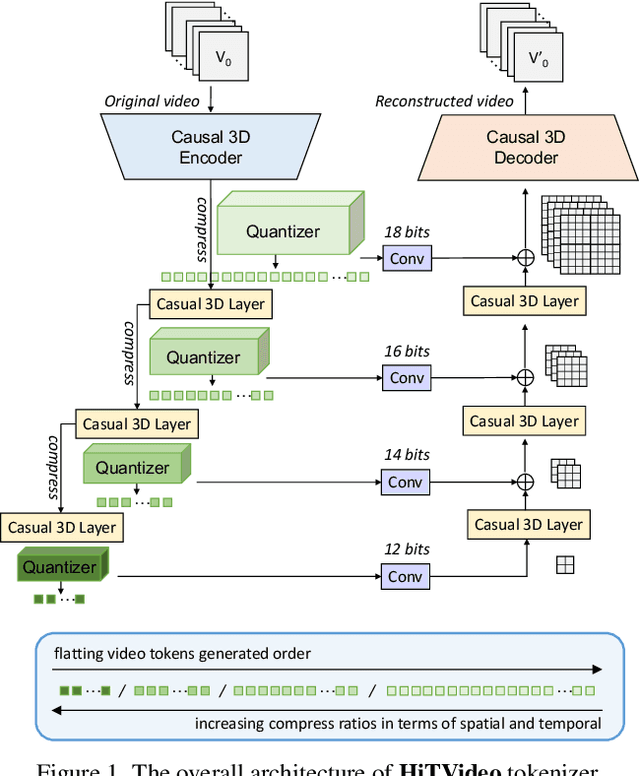
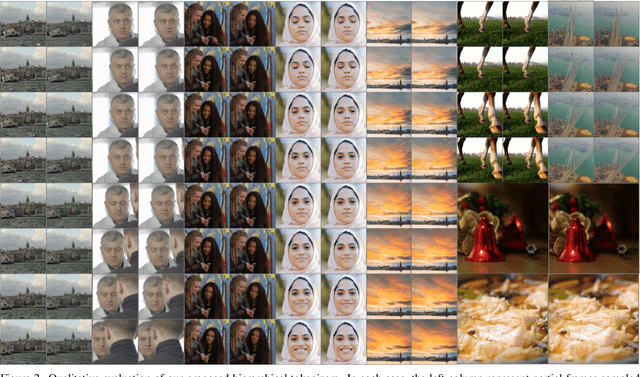

Text-to-video generation poses significant challenges due to the inherent complexity of video data, which spans both temporal and spatial dimensions. It introduces additional redundancy, abrupt variations, and a domain gap between language and vision tokens while generation. Addressing these challenges requires an effective video tokenizer that can efficiently encode video data while preserving essential semantic and spatiotemporal information, serving as a critical bridge between text and vision. Inspired by the observation in VQ-VAE-2 and workflows of traditional animation, we propose HiTVideo for text-to-video generation with hierarchical tokenizers. It utilizes a 3D causal VAE with a multi-layer discrete token framework, encoding video content into hierarchically structured codebooks. Higher layers capture semantic information with higher compression, while lower layers focus on fine-grained spatiotemporal details, striking a balance between compression efficiency and reconstruction quality. Our approach efficiently encodes longer video sequences (e.g., 8 seconds, 64 frames), reducing bits per pixel (bpp) by approximately 70\% compared to baseline tokenizers, while maintaining competitive reconstruction quality. We explore the trade-offs between compression and reconstruction, while emphasizing the advantages of high-compressed semantic tokens in text-to-video tasks. HiTVideo aims to address the potential limitations of existing video tokenizers in text-to-video generation tasks, striving for higher compression ratios and simplify LLMs modeling under language guidance, offering a scalable and promising framework for advancing text to video generation. Demo page: https://ziqinzhou66.github.io/project/HiTVideo.
ScalingFilter: Assessing Data Quality through Inverse Utilization of Scaling Laws
Aug 15, 2024



High-quality data is crucial for the pre-training performance of large language models. Unfortunately, existing quality filtering methods rely on a known high-quality dataset as reference, which can introduce potential bias and compromise diversity. In this paper, we propose ScalingFilter, a novel approach that evaluates text quality based on the perplexity difference between two language models trained on the same data, thereby eliminating the influence of the reference dataset in the filtering process. An theoretical analysis shows that ScalingFilter is equivalent to an inverse utilization of scaling laws. Through training models with 1.3B parameters on the same data source processed by various quality filters, we find ScalingFilter can improve zero-shot performance of pre-trained models in downstream tasks. To assess the bias introduced by quality filtering, we introduce semantic diversity, a metric of utilizing text embedding models for semantic representations. Extensive experiments reveal that semantic diversity is a reliable indicator of dataset diversity, and ScalingFilter achieves an optimal balance between downstream performance and semantic diversity.
Xwin-LM: Strong and Scalable Alignment Practice for LLMs
May 30, 2024In this work, we present Xwin-LM, a comprehensive suite of alignment methodologies for large language models (LLMs). This suite encompasses several key techniques, including supervised finetuning (SFT), reward modeling (RM), rejection sampling finetuning (RS), and direct preference optimization (DPO). The key components are as follows: (1) Xwin-LM-SFT, models initially finetuned with high-quality instruction data; (2) Xwin-Pair, a large-scale, multi-turn preference dataset meticulously annotated using GPT-4; (3) Xwin-RM, reward models trained on Xwin-Pair, developed at scales of 7B, 13B, and 70B parameters; (4) Xwin-Set, a multiwise preference dataset in which each prompt is linked to 64 unique responses generated by Xwin-LM-SFT and scored by Xwin-RM; (5) Xwin-LM-RS, models finetuned with the highest-scoring responses from Xwin-Set; (6) Xwin-LM-DPO, models further optimized on Xwin-Set using the DPO algorithm. Our evaluations on AlpacaEval and MT-bench demonstrate consistent and significant improvements across the pipeline, demonstrating the strength and scalability of Xwin-LM. The repository https://github.com/Xwin-LM/Xwin-LM will be continually updated to foster community research.
Common 7B Language Models Already Possess Strong Math Capabilities
Mar 07, 2024



Mathematical capabilities were previously believed to emerge in common language models only at a very large scale or require extensive math-related pre-training. This paper shows that the LLaMA-2 7B model with common pre-training already exhibits strong mathematical abilities, as evidenced by its impressive accuracy of 97.7% and 72.0% on the GSM8K and MATH benchmarks, respectively, when selecting the best response from 256 random generations. The primary issue with the current base model is the difficulty in consistently eliciting its inherent mathematical capabilities. Notably, the accuracy for the first answer drops to 49.5% and 7.9% on the GSM8K and MATH benchmarks, respectively. We find that simply scaling up the SFT data can significantly enhance the reliability of generating correct answers. However, the potential for extensive scaling is constrained by the scarcity of publicly available math questions. To overcome this limitation, we employ synthetic data, which proves to be nearly as effective as real data and shows no clear saturation when scaled up to approximately one million samples. This straightforward approach achieves an accuracy of 82.6% on GSM8K and 40.6% on MATH using LLaMA-2 7B models, surpassing previous models by 14.2% and 20.8%, respectively. We also provide insights into scaling behaviors across different reasoning complexities and error types.