 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Driven Design for Multi-Step Dexterous Manipulation: Insights from Neuroscience
Dec 15, 2024Multi-step dexterous manipulation is a fundamental skill in household scenarios, yet remains an underexplored area in robotics. This paper proposes a modular approach, where each step of the manipulation process is addressed with dedicated policies based on effective modality input, rather than relying on a single end-to-end model. To demonstrate this, a dexterous robotic hand performs a manipulation task involving picking up and rotating a box. Guided by insights from neuroscience, the task is decomposed into three sub-skills, 1)reaching, 2)grasping and lifting, and 3)in-hand rotation, based on the dominant sensory modalities employed in the human brain. Each sub-skill is addressed using distinct methods from a practical perspective: a classical controller, a Vision-Language-Action model, and a reinforcement learning policy with force feedback, respectively. We tested the pipeline on a real robot to demonstrate the feasibility of our approach. The key contribution of this study lies in presenting a neuroscience-inspired, modality-driven methodology for multi-step dexterous manipulation.
APriCoT: Action Primitives based on Contact-state Transition for In-Hand Tool Manipulation
Jul 16, 2024In-hand tool manipulation is an operation that not only manipulates a tool within the hand (i.e., in-hand manipulation) but also achieves a grasp suitable for a task after the manipulation. This study aims to achieve an in-hand tool manipulation skill through deep reinforcement learning. The difficulty of learning the skill arises because this manipulation requires (A) exploring long-term contact-state changes to achieve the desired grasp and (B) highly-varied motions depending on the contact-state transition. (A) leads to a sparsity of a reward on a successful grasp, and (B) requires an RL agent to explore widely within the state-action space to learn highly-varied actions, leading to sample inefficiency. To address these issues, this study proposes Action Primitives based on Contact-state Transition (APriCoT). APriCoT decomposes the manipulation into short-term action primitives by describing the operation as a contact-state transition based on three action representations (detach, crossover, attach). In each action primitive, fingers are required to perform short-term and similar actions. By training a policy for each primitive, we can mitigate the issues from (A) and (B). This study focuses on a fundamental operation as an example of in-hand tool manipulation: rotating an elongated object grasped with a precision grasp by half a turn to achieve the initial grasp. Experimental results demonstrated that ours succeeded in both the rotation and the achievement of the desired grasp, unlike existing studies. Additionally, it was found that the policy was robust to changes in object shape.
AVI-Talking: Learning Audio-Visual Instructions for Expressive 3D Talking Face Generation
Feb 25, 2024While considerable progress has been made in achieving accurate lip synchronization for 3D speech-driven talking face generation, the task of incorporating expressive facial detail synthesis aligned with the speaker's speaking status remains challenging. Our goal is to directly leverage the inherent style information conveyed by human speech for generating an expressive talking face that aligns with the speaking status. In this paper, we propose AVI-Talking, an Audio-Visual Instruction system for expressive Talking face generation. This system harnesses the robust contextual reasoning and hallucination capability offered by Large Language Models (LLMs) to instruct the realistic synthesis of 3D talking faces. Instead of directly learning facial movements from human speech, our two-stage strategy involves the LLMs first comprehending audio information and generating instructions implying expressive facial details seamlessly corresponding to the speech. Subsequently, a diffusion-based generative network executes these instructions. This two-stage process, coupled with the incorporation of LLMs, enhances model interpretability and provides users with flexibility to comprehend instructions and specify desired operations or modifications. Extensive experiments showcase the effectiveness of our approach in producing vivid talking faces with expressive facial movements and consistent emotional status.
Constraint-aware Policy for Compliant Manipulation
Nov 18, 2023Robot manipulation in a physically-constrained environment requires compliant manipulation. Compliant manipulation is a manipulation skill to adjust hand motion based on the force imposed by the environment. Recently, reinforcement learning (RL) has been applied to solve household operations involving compliant manipulation. However, previous RL methods have primarily focused on designing a policy for a specific operation that limits their applicability and requires separate training for every new operation. We propose a constraint-aware policy that is applicable to various unseen manipulations by grouping several manipulations together based on the type of physical constraint involved. The type of physical constraint determines the characteristic of the imposed force direction; thus, a generalized policy is trained in the environment and reward designed on the basis of this characteristic. This paper focuses on two types of physical constraints: prismatic and revolute joints. Experiments demonstrated that the same policy could successfully execute various compliant-manipulation operations, both in the simulation and reality. We believe this study is the first step toward realizing a generalized household-robot.
ImageBrush: Learning Visual In-Context Instructions for Exemplar-Based Image Manipulation
Aug 02, 2023While language-guided image manipulation has made remarkable progress, the challenge of how to instruct the manipulation process faithfully reflecting human intentions persists. An accurate and comprehensive description of a manipulation task using natural language is laborious and sometimes even impossible, primarily due to the inherent uncertainty and ambiguity present in linguistic expressions. Is it feasible to accomplish image manipulation without resorting to external cross-modal language information? If this possibility exists, the inherent modality gap would be effortlessly eliminated. In this paper, we propose a novel manipulation methodology, dubbed ImageBrush, that learns visual instructions for more accurate image editing. Our key idea is to employ a pair of transformation images as visual instructions, which not only precisely captures human intention but also facilitates accessibility in real-world scenarios. Capturing visual instructions is particularly challenging because it involves extracting the underlying intentions solely from visual demonstrations and then applying this operation to a new image. To address this challenge, we formulate visual instruction learning as a diffusion-based inpainting problem, where the contextual information is fully exploited through an iterative process of generation. A visual prompting encoder is carefully devised to enhance the model's capacity in uncovering human intent behind the visual instructions. Extensive experiments show that our method generates engaging manipulation results conforming to the transformations entailed in demonstrations. Moreover, our model exhibits robust generalization capabilities on various downstream tasks such as pose transfer, image translation and video inpainting.
Tracker: Model-based Reinforcement Learning for Tracking Control of Human Finger Attached with Thin McKibben Muscles
Apr 01, 2023To adopt the soft hand exoskeleton to support activities of daily livings, it is necessary to control finger joints precisely with the exoskeleton. The problem of controlling joints to follow a given trajectory is called the tracking control problem. In this study, we focus on the tracking control problem of a human finger attached with thin McKibben muscles. To achieve precise control with thin McKibben muscles, there are two problems: one is the complex characteristics of the muscles, for example, non-linearity, hysteresis, uncertainties in the real world, and the other is the difficulty in accessing a precise model of the muscles and human fingers. To solve these problems, we adopted DreamerV2, which is a model-based reinforcement learning method, but the target trajectory cannot be generated by the learned model. Therefore, we propose Tracker, which is an extension of DreamerV2 for the tracking control problem. In the experiment, we showed that Tracker can achieve an approximately 81% smaller error than PID for the control of a two-link manipulator that imitates a part of human index finger from the metacarpal bone to the proximal bone. Tracker achieved the control of the third joint of the human index finger with a small error by being trained for approximately 60 minutes. In addition, it took approximately 15 minutes, which is less than the time required for the first training, to achieve almost the same accuracy by fine-tuning the policy pre-trained by the user's finger after taking off and attaching thin McKibben muscles again as the accuracy before taking off.
Make Your Brief Stroke Real and Stereoscopic: 3D-Aware Simplified Sketch to Portrait Generation
Feb 14, 2023



Creating the photo-realistic version of people sketched portraits is useful to various entertainment purposes. Existing studies only generate portraits in the 2D plane with fixed views, making the results less vivid. In this paper, we present Stereoscopic Simplified Sketch-to-Portrait (SSSP), which explores the possibility of creating Stereoscopic 3D-aware portraits from simple contour sketches by involving 3D generative models. Our key insight is to design sketch-aware constraints that can fully exploit the prior knowledge of a tri-plane-based 3D-aware generative model. Specifically, our designed region-aware volume rendering strategy and global consistency constraint further enhance detail correspondences during sketch encoding. Moreover, in order to facilitate the usage of layman users, we propose a Contour-to-Sketch module with vector quantized representations, so that easily drawn contours can directly guide the generation of 3D portraits. Extensive comparisons show that our method generates high-quality results that match the sketch. Our usability study verifies that our system is greatly preferred by user.
Masked Lip-Sync Prediction by Audio-Visual Contextual Exploitation in Transformers
Dec 09, 2022



Previous studies have explored generating accurately lip-synced talking faces for arbitrary targets given audio conditions. However, most of them deform or generate the whole facial area, leading to non-realistic results. In this work, we delve into the formulation of altering only the mouth shapes of the target person. This requires masking a large percentage of the original image and seamlessly inpainting it with the aid of audio and reference frames. To this end, we propose the Audio-Visual Context-Aware Transformer (AV-CAT) framework, which produces accurate lip-sync with photo-realistic quality by predicting the masked mouth shapes. Our key insight is to exploit desired contextual information provided in audio and visual modalities thoroughly with delicately designed Transformers. Specifically, we propose a convolution-Transformer hybrid backbone and design an attention-based fusion strategy for filling the masked parts. It uniformly attends to the textural information on the unmasked regions and the reference frame. Then the semantic audio information is involved in enhancing the self-attention computation. Additionally, a refinement network with audio injection improves both image and lip-sync quality. Extensive experiments validate that our model can generate high-fidelity lip-synced results for arbitrary subjects.
Task-grasping from human demonstration
Mar 01, 2022



A challenge in robot grasping is to achieve task-grasping which is to select a grasp that is advantageous to the success of tasks before and after grasps. One of the frameworks to address this difficulty is Learning-from-Observation (LfO), which obtains various hints from human demonstrations. This paper solves three issues in the grasping skills in the LfO framework: 1) how to functionally mimic human-demonstrated grasps to robots with limited grasp capability, 2) how to coordinate grasp skills with reaching body mimicking, 3) how to robustly perform grasps under object pose and shape uncertainty. A deep reinforcement learning using contact-web based rewards and domain randomization of approach directions is proposed to achieve such robust mimicked grasping skills. Experiment results show that the trained grasping skills can be applied in an LfO system and executed on a real robot. In addition, it is shown that the trained skill is robust to errors in the object pose and to the uncertainty of the object shape and can be combined with various reach-coordination.
SerumRNN: Step by Step Audio VST Effect Programming
Apr 08, 2021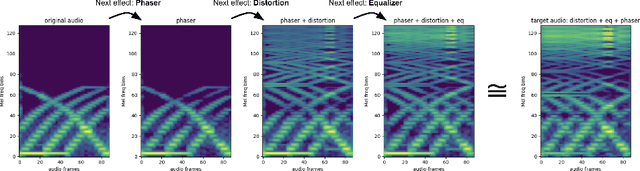
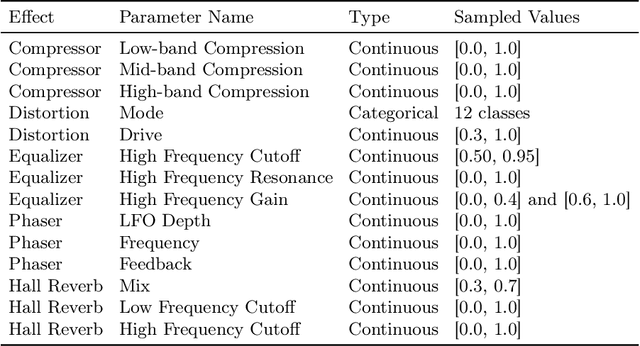

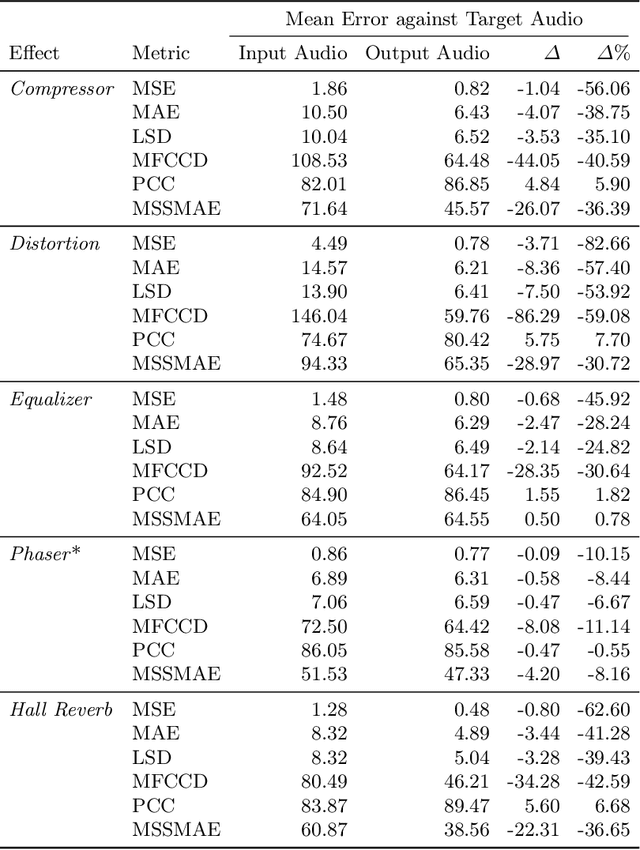
Learning to program an audio production VST synthesizer is a time consuming process, usually obtained through inefficient trial and error and only mastered after years of experience. As an educational and creative tool for sound designers, we propose SerumRNN: a system that provides step-by-step instructions for applying audio effects to change a user's input audio towards a desired sound. We apply our system to Xfer Records Serum: currently one of the most popular and complex VST synthesizers used by the audio production community. Our results indicate that SerumRNN is consistently able to provide useful feedback for a variety of different audio effects and synthesizer presets. We demonstrate the benefits of using an iterative system and show that SerumRNN learns to prioritize effects and can discover more efficient effect order sequences than a variety of baselines.
* Audio samples of the system can be listened to at bit.ly/serum_rnn