 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training
Oct 21, 2025The adoption of long context windows has become a standard feature in Large Language Models (LLMs), as extended contexts significantly enhance their capacity for complex reasoning and broaden their applicability across diverse scenarios. Dynamic sparse attention is a promising approach for reducing the computational cost of long-context. However, efficiently training LLMs with dynamic sparse attention on ultra-long contexts-especially in distributed settings-remains a significant challenge, due in large part to worker- and step-level imbalance. This paper introduces MTraining, a novel distributed methodology leveraging dynamic sparse attention to enable efficient training for LLMs with ultra-long contexts. Specifically, MTraining integrates three key components: a dynamic sparse training pattern, balanced sparse ring attention, and hierarchical sparse ring attention. These components are designed to synergistically address the computational imbalance and communication overheads inherent in dynamic sparse attention mechanisms during the training of models with extensive context lengths. We demonstrate the efficacy of MTraining by training Qwen2.5-3B, successfully expanding its context window from 32K to 512K tokens on a cluster of 32 A100 GPUs. Our evaluations on a comprehensive suite of downstream tasks, including RULER, PG-19, InfiniteBench, and Needle In A Haystack, reveal that MTraining achieves up to a 6x higher training throughput while preserving model accuracy. Our code is available at https://github.com/microsoft/MInference/tree/main/MTraining.
Diffusion^2: Turning 3D Environments into Radio Frequency Heatmaps
Oct 02, 2025Modeling radio frequency (RF) signal propagation is essential for understanding the environment, as RF signals offer valuable insights beyond the capabilities of RGB cameras, which are limited by the visible-light spectrum, lens coverage, and occlusions. It is also useful for supporting wireless diagnosis, deployment, and optimization. However, accurately predicting RF signals in complex environments remains a challenge due to interactions with obstacles such as absorption and reflection. We introduce Diffusion^2, a diffusion-based approach that uses 3D point clouds to model the propagation of RF signals across a wide range of frequencies, from Wi-Fi to millimeter waves. To effectively capture RF-related features from 3D data, we present the RF-3D Encoder, which encapsulates the complexities of 3D geometry along with signal-specific details. These features undergo multi-scale embedding to simulate the actual RF signal dissemination process. Our evaluation, based on synthetic and real-world measurements, demonstrates that Diffusion^2 accurately estimates the behavior of RF signals in various frequency bands and environmental conditions, with an error margin of just 1.9 dB and 27x faster than existing methods, marking a significant advancement in the field. Refer to https://rfvision-project.github.io/ for more information.
VidGuard-R1: AI-Generated Video Detection and Explanation via Reasoning MLLMs and RL
Oct 02, 2025With the rapid advancement of AI-generated videos, there is an urgent need for effective detection tools to mitigate societal risks such as misinformation and reputational harm. In addition to accurate classification, it is essential that detection models provide interpretable explanations to ensure transparency for regulators and end users. To address these challenges, we introduce VidGuard-R1, the first video authenticity detector that fine-tunes a multi-modal large language model (MLLM) using group relative policy optimization (GRPO). Our model delivers both highly accurate judgments and insightful reasoning. We curate a challenging dataset of 140k real and AI-generated videos produced by state-of-the-art generation models, carefully designing the generation process to maximize discrimination difficulty. We then fine-tune Qwen-VL using GRPO with two specialized reward models that target temporal artifacts and generation complexity. Extensive experiments demonstrate that VidGuard-R1 achieves state-of-the-art zero-shot performance on existing benchmarks, with additional training pushing accuracy above 95%. Case studies further show that VidGuard-R1 produces precise and interpretable rationales behind its predictions. The code is publicly available at https://VidGuard-R1.github.io.
$ΔL$ Normalization: Rethink Loss Aggregation in RLVR
Sep 09, 2025We propose $\Delta L$ Normalization, a simple yet effective loss aggregation method tailored to the characteristic of dynamic generation lengths in Reinforcement Learning with Verifiable Rewards (RLVR). Recently, RLVR has demonstrated strong potential in improving the reasoning capabilities of large language models (LLMs), but a major challenge lies in the large variability of response lengths during training, which leads to high gradient variance and unstable optimization. Although previous methods such as GRPO, DAPO, and Dr. GRPO introduce different loss normalization terms to address this issue, they either produce biased estimates or still suffer from high gradient variance. By analyzing the effect of varying lengths on policy loss both theoretically and empirically, we reformulate the problem as finding a minimum-variance unbiased estimator. Our proposed $\Delta L$ Normalization not only provides an unbiased estimate of the true policy loss but also minimizes gradient variance in theory. Extensive experiments show that it consistently achieves superior results across different model sizes, maximum lengths, and tasks. Our code will be made public at https://github.com/zerolllin/Delta-L-Normalization.
MmBack: Clock-free Multi-Sensor Backscatter with Synchronous Acquisition and Multiplexing
Jul 02, 2025Backscatter tags provide a low-power solution for sensor applications, yet many real-world scenarios require multiple sensors-often of different types-for complex sensing tasks. However, existing designs support only a single sensor per tag, increasing spatial overhead. State-of-the-art approaches to multiplexing multiple sensor streams on a single tag rely on onboard clocks or multiple modulation chains, which add cost, enlarge form factor, and remain prone to timing drift-disrupting synchronization across sensors. We present mmBack, a low-power, clock-free backscatter tag that enables synchronous multi-sensor data acquisition and multiplexing over a single modulation chain. mmBack synchronizes sensor inputs in parallel using a shared reference signal extracted from ambient RF excitation, eliminating the need for an onboard timing source. To efficiently multiplex sensor data, mmBack designs a voltage-division scheme to multiplex multiple sensor inputs as backscatter frequency shifts through a single oscillator and RF switch. At the receiver, mmBack develops a frequency tracking algorithm and a finite-state machine for accurate demultiplexing. mmBack's ASIC design consumes 25.56uW, while its prototype supports 5 concurrent sensor streams with bandwidths of up to 5kHz and 3 concurrent sensor streams with bandwidth of up to 18kHz. Evaluation shows that mmBack achieves an average SNR surpassing 15dB in signal reconstruction.
Enhancing User Engagement in Socially-Driven Dialogue through Interactive LLM Alignments
Jun 26, 2025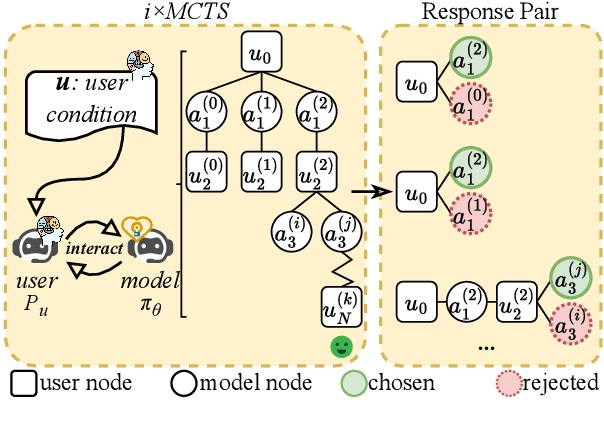

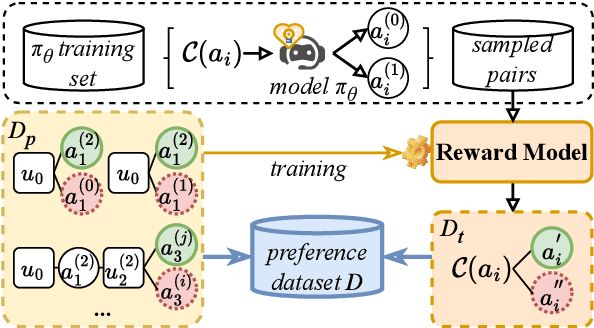

Enhancing user engagement through interactions plays an essential role in socially-driven dialogues. While prior works have optimized models to reason over relevant knowledge or plan a dialogue act flow, the relationship between user engagement and knowledge or dialogue acts is subtle and does not guarantee user engagement in socially-driven dialogues. To this end, we enable interactive LLMs to learn user engagement by leveraging signals from the future development of conversations. Specifically, we adopt a more direct and relevant indicator of user engagement, i.e., the user's reaction related to dialogue intention after the interaction, as a reward to align interactive LLMs. To achieve this, we develop a user simulator to interact with target interactive LLMs and explore interactions between the user and the interactive LLM system via \textit{i$\times$MCTS} (\textit{M}onte \textit{C}arlo \textit{T}ree \textit{S}earch for \textit{i}nteraction). In this way, we collect a dataset containing pairs of higher and lower-quality experiences using \textit{i$\times$MCTS}, and align interactive LLMs for high-level user engagement by direct preference optimization (DPO) accordingly. Experiments conducted on two socially-driven dialogue scenarios (emotional support conversations and persuasion for good) demonstrate that our method effectively enhances user engagement in interactive LLMs.
SecurityLingua: Efficient Defense of LLM Jailbreak Attacks via Security-Aware Prompt Compression
Jun 15, 2025Large language models (LLMs) have achieved widespread adoption across numerous applications. However, many LLMs are vulnerable to malicious attacks even after safety alignment. These attacks typically bypass LLMs' safety guardrails by wrapping the original malicious instructions inside adversarial jailbreaks prompts. Previous research has proposed methods such as adversarial training and prompt rephrasing to mitigate these safety vulnerabilities, but these methods often reduce the utility of LLMs or lead to significant computational overhead and online latency. In this paper, we propose SecurityLingua, an effective and efficient approach to defend LLMs against jailbreak attacks via security-oriented prompt compression. Specifically, we train a prompt compressor designed to discern the "true intention" of the input prompt, with a particular focus on detecting the malicious intentions of adversarial prompts. Then, in addition to the original prompt, the intention is passed via the system prompt to the target LLM to help it identify the true intention of the request. SecurityLingua ensures a consistent user experience by leaving the original input prompt intact while revealing the user's potentially malicious intention and stimulating the built-in safety guardrails of the LLM. Moreover, thanks to prompt compression, SecurityLingua incurs only a negligible overhead and extra token cost compared to all existing defense methods, making it an especially practical solution for LLM defense. Experimental results demonstrate that SecurityLingua can effectively defend against malicious attacks and maintain utility of the LLM with negligible compute and latency overhead. Our code is available at https://aka.ms/SecurityLingua.
ReasonGen-R1: CoT for Autoregressive Image generation models through SFT and RL
May 30, 2025Although chain-of-thought reasoning and reinforcement learning (RL) have driven breakthroughs in NLP, their integration into generative vision models remains underexplored. We introduce ReasonGen-R1, a two-stage framework that first imbues an autoregressive image generator with explicit text-based "thinking" skills via supervised fine-tuning on a newly generated reasoning dataset of written rationales, and then refines its outputs using Group Relative Policy Optimization. To enable the model to reason through text before generating images, We automatically generate and release a corpus of model crafted rationales paired with visual prompts, enabling controlled planning of object layouts, styles, and scene compositions. Our GRPO algorithm uses reward signals from a pretrained vision language model to assess overall visual quality, optimizing the policy in each update. Evaluations on GenEval, DPG, and the T2I benchmark demonstrate that ReasonGen-R1 consistently outperforms strong baselines and prior state-of-the-art models. More: aka.ms/reasongen.
Chain-of-Model Learning for Language Model
May 17, 2025In this paper, we propose a novel learning paradigm, termed Chain-of-Model (CoM), which incorporates the causal relationship into the hidden states of each layer as a chain style, thereby introducing great scaling efficiency in model training and inference flexibility in deployment. We introduce the concept of Chain-of-Representation (CoR), which formulates the hidden states at each layer as a combination of multiple sub-representations (i.e., chains) at the hidden dimension level. In each layer, each chain from the output representations can only view all of its preceding chains in the input representations. Consequently, the model built upon CoM framework can progressively scale up the model size by increasing the chains based on the previous models (i.e., chains), and offer multiple sub-models at varying sizes for elastic inference by using different chain numbers. Based on this principle, we devise Chain-of-Language-Model (CoLM), which incorporates the idea of CoM into each layer of Transformer architecture. Based on CoLM, we further introduce CoLM-Air by introducing a KV sharing mechanism, that computes all keys and values within the first chain and then shares across all chains. This design demonstrates additional extensibility, such as enabling seamless LM switching, prefilling acceleration and so on. Experimental results demonstrate our CoLM family can achieve comparable performance to the standard Transformer, while simultaneously enabling greater flexiblity, such as progressive scaling to improve training efficiency and offer multiple varying model sizes for elastic inference, paving a a new way toward building language models. Our code will be released in the future at: https://github.com/microsoft/CoLM.
Empowering Agentic Video Analytics Systems with Video Language Models
May 02, 2025

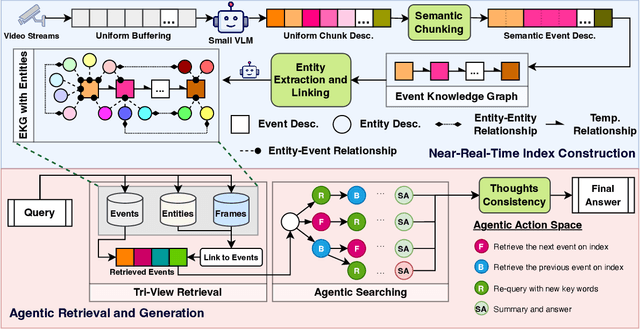
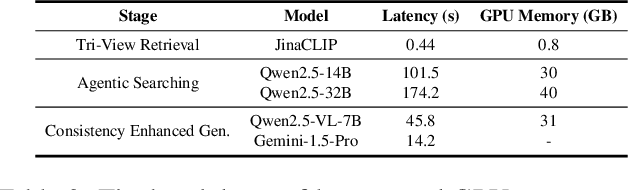
AI-driven video analytics has become increasingly pivotal across diverse domains. However, existing systems are often constrained to specific, predefined tasks, limiting their adaptability in open-ended analytical scenarios. The recent emergence of Video-Language Models (VLMs) as transformative technologies offers significant potential for enabling open-ended video understanding, reasoning, and analytics. Nevertheless, their limited context windows present challenges when processing ultra-long video content, which is prevalent in real-world applications. To address this, we introduce AVAS, a VLM-powered system designed for open-ended, advanced video analytics. AVAS incorporates two key innovations: (1) the near real-time construction of Event Knowledge Graphs (EKGs) for efficient indexing of long or continuous video streams, and (2) an agentic retrieval-generation mechanism that leverages EKGs to handle complex and diverse queries. Comprehensive evaluations on public benchmarks, LVBench and VideoMME-Long, demonstrate that AVAS achieves state-of-the-art performance, attaining 62.3% and 64.1% accuracy, respectively, significantly surpassing existing VLM and video Retrieval-Augmented Generation (RAG) systems. Furthermore, to evaluate video analytics in ultra-long and open-world video scenarios, we introduce a new benchmark, AVAS-100. This benchmark comprises 8 videos, each exceeding 10 hours in duration, along with 120 manually annotated, diverse, and complex question-answer pairs. On AVAS-100, AVAS achieves top-tier performance with an accuracy of 75.8%.