 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Motion Factorization for Compositional Video Generation
Mar 10, 2026Compositional video generation aims to synthesize multiple instances with diverse appearance and motion, which is widely applicable in real-world scenarios. However, current approaches mainly focus on binding semantics, neglecting to understand diverse motion categories specified in prompts. In this paper, we propose a motion factorization framework that decomposes complex motion into three primary categories: motionlessness, rigid motion, and non-rigid motion. Specifically, our framework follows a planning before generation paradigm. (1) During planning, we reason about motion laws on the motion graph to obtain frame-wise changes in the shape and position of each instance. This alleviates semantic ambiguities in the user prompt by organizing it into a structured representation of instances and their interactions. (2) During generation, we modulate the synthesis of distinct motion categories in a disentangled manner. Conditioned on the motion cues, guidance branches stabilize appearance in motionless regions, preserve rigid-body geometry, and regularize local non-rigid deformations. Crucially, our two modules are model-agnostic, which can be seamlessly incorporated into various diffusion model architectures. Extensive experiments demonstrate that our framework achieves impressive performance in motion synthesis on real-world benchmarks. Our code will be released soon.
HiTVideo: Hierarchical Tokenizers for Enhancing Text-to-Video Generation with Autoregressive Large Language Models
Mar 14, 2025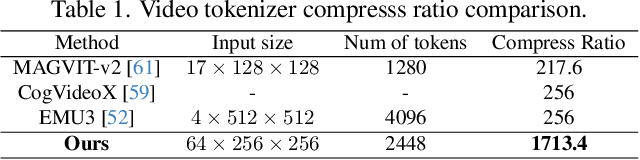
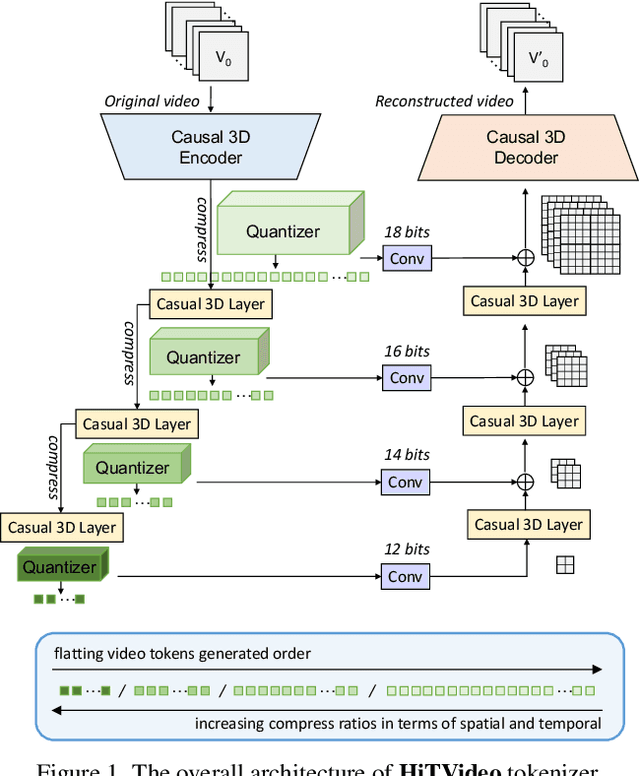
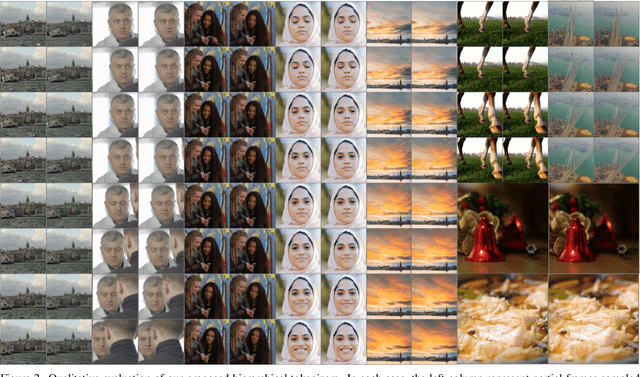

Text-to-video generation poses significant challenges due to the inherent complexity of video data, which spans both temporal and spatial dimensions. It introduces additional redundancy, abrupt variations, and a domain gap between language and vision tokens while generation. Addressing these challenges requires an effective video tokenizer that can efficiently encode video data while preserving essential semantic and spatiotemporal information, serving as a critical bridge between text and vision. Inspired by the observation in VQ-VAE-2 and workflows of traditional animation, we propose HiTVideo for text-to-video generation with hierarchical tokenizers. It utilizes a 3D causal VAE with a multi-layer discrete token framework, encoding video content into hierarchically structured codebooks. Higher layers capture semantic information with higher compression, while lower layers focus on fine-grained spatiotemporal details, striking a balance between compression efficiency and reconstruction quality. Our approach efficiently encodes longer video sequences (e.g., 8 seconds, 64 frames), reducing bits per pixel (bpp) by approximately 70\% compared to baseline tokenizers, while maintaining competitive reconstruction quality. We explore the trade-offs between compression and reconstruction, while emphasizing the advantages of high-compressed semantic tokens in text-to-video tasks. HiTVideo aims to address the potential limitations of existing video tokenizers in text-to-video generation tasks, striving for higher compression ratios and simplify LLMs modeling under language guidance, offering a scalable and promising framework for advancing text to video generation. Demo page: https://ziqinzhou66.github.io/project/HiTVideo.
EZIGen: Enhancing zero-shot subject-driven image generation with precise subject encoding and decoupled guidance
Sep 12, 2024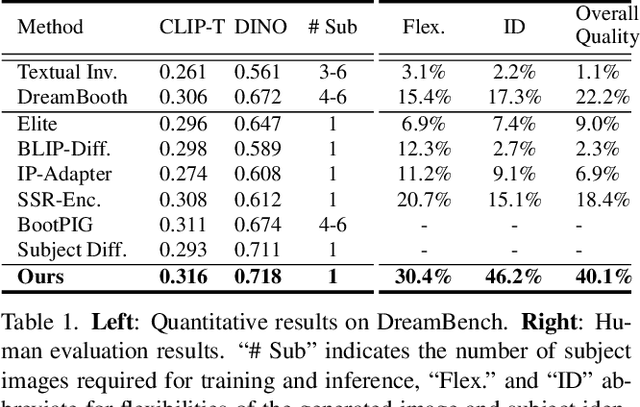

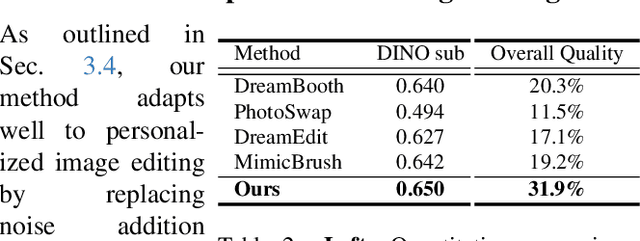

Zero-shot subject-driven image generation aims to produce images that incorporate a subject from a given example image. The challenge lies in preserving the subject's identity while aligning with the text prompt, which often requires modifying certain aspects of the subject's appearance. Despite advancements in diffusion model based methods, existing approaches still struggle to balance identity preservation with text prompt alignment. In this study, we conducted an in-depth investigation into this issue and uncovered key insights for achieving effective identity preservation while maintaining a strong balance. Our key findings include: (1) the design of the subject image encoder significantly impacts identity preservation quality, and (2) generating an initial layout is crucial for both text alignment and identity preservation. Building on these insights, we introduce a new approach called EZIGen, which employs two main strategies: a carefully crafted subject image Encoder based on the UNet architecture of the pretrained Stable Diffusion model to ensure high-quality identity transfer, following a process that decouples the guidance stages and iteratively refines the initial image layout. Through these strategies, EZIGen achieves state-of-the-art results on multiple subject-driven benchmarks with a unified model and 100 times less training data.
MuseBarControl: Enhancing Fine-Grained Control in Symbolic Music Generation through Pre-Training and Counterfactual Loss
Jul 05, 2024

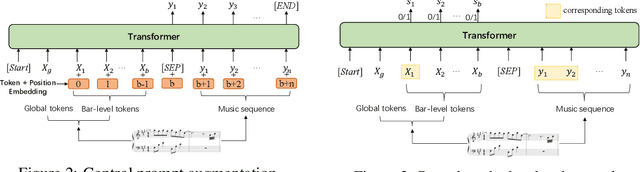
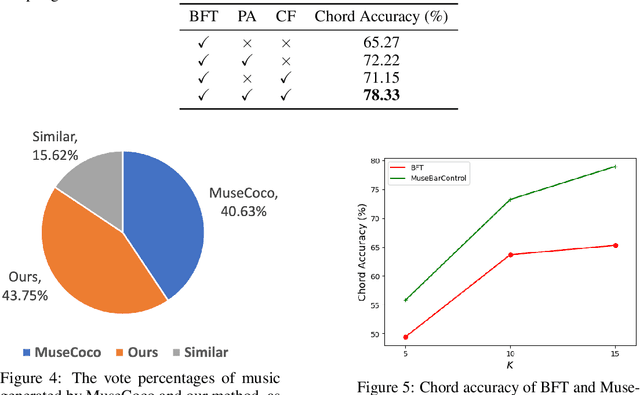
Automatically generating symbolic music-music scores tailored to specific human needs-can be highly beneficial for musicians and enthusiasts. Recent studies have shown promising results using extensive datasets and advanced transformer architectures. However, these state-of-the-art models generally offer only basic control over aspects like tempo and style for the entire composition, lacking the ability to manage finer details, such as control at the level of individual bars. While fine-tuning a pre-trained symbolic music generation model might seem like a straightforward method for achieving this finer control, our research indicates challenges in this approach. The model often fails to respond adequately to new, fine-grained bar-level control signals. To address this, we propose two innovative solutions. First, we introduce a pre-training task designed to link control signals directly with corresponding musical tokens, which helps in achieving a more effective initialization for subsequent fine-tuning. Second, we implement a novel counterfactual loss that promotes better alignment between the generated music and the control prompts. Together, these techniques significantly enhance our ability to control music generation at the bar level, showing a 13.06\% improvement over conventional methods. Our subjective evaluations also confirm that this enhanced control does not compromise the musical quality of the original pre-trained generative model.
Source-Free Unsupervised Domain Adaptation with Hypothesis Consolidation of Prediction Rationale
Feb 02, 2024Source-Free Unsupervised Domain Adaptation (SFUDA) is a challenging task where a model needs to be adapted to a new domain without access to target domain labels or source domain data. The primary difficulty in this task is that the model's predictions may be inaccurate, and using these inaccurate predictions for model adaptation can lead to misleading results. To address this issue, this paper proposes a novel approach that considers multiple prediction hypotheses for each sample and investigates the rationale behind each hypothesis. By consolidating these hypothesis rationales, we identify the most likely correct hypotheses, which we then use as a pseudo-labeled set to support a semi-supervised learning procedure for model adaptation. To achieve the optimal performance, we propose a three-step adaptation process: model pre-adaptation, hypothesis consolidation, and semi-supervised learning. Extensive experimental results demonstrate that our approach achieves state-of-the-art performance in the SFUDA task and can be easily integrated into existing approaches to improve their performance. The codes are available at \url{https://github.com/GANPerf/HCPR}.
Integrating Sensing, Communication, and Power Transfer: Multiuser Beamforming Design
Nov 15, 2023



In the sixth-generation (6G) networks, massive low-power devices are expected to sense environment and deliver tremendous data. To enhance the radio resource efficiency, the integrated sensing and communication (ISAC) technique exploits the sensing and communication functionalities of signals, while the simultaneous wireless information and power transfer (SWIPT) techniques utilizes the same signals as the carriers for both information and power delivery. The further combination of ISAC and SWIPT leads to the advanced technology namely integrated sensing, communication, and power transfer (ISCPT). In this paper, a multi-user multiple-input multiple-output (MIMO) ISCPT system is considered, where a base station equipped with multiple antennas transmits messages to multiple information receivers (IRs), transfers power to multiple energy receivers (ERs), and senses a target simultaneously. The sensing target can be regarded as a point or an extended surface. When the locations of IRs and ERs are separated, the MIMO beamforming designs are optimized to improve the sensing performance while meeting the communication and power transfer requirements. The resultant non-convex optimization problems are solved based on a series of techniques including Schur complement transformation and rank reduction. Moreover, when the IRs and ERs are co-located, the power splitting factors are jointly optimized together with the beamformers to balance the performance of communication and power transfer. To better understand the performance of ISCPT, the target positioning problem is further investigated. Simulations are conducted to verify the effectiveness of our proposed designs, which also reveal a performance tradeoff among sensing, communication, and power transfer.
Beamforming Design for RIS-Aided THz Wideband Communication Systems
Sep 21, 2023



Benefiting from tens of GHz of bandwidth, terahertz (THz) communications has become a promising technology for future 6G networks. However, the conventional hybrid beamforming architecture based on frequency-independent phase-shifters is not able to cope with the beam split effect (BSE) in THz massive multiple-input multiple-output (MIMO) systems. Despite some work introducing the frequency-dependent phase shifts via the time delay network to mitigate the beam splitting in THz wideband communications, the corresponding issue in reconfigurable intelligent surface (RIS)-aided communications has not been well investigated. In this paper, the BSE in THz massive MIMO is quantified by analyzing the array gain loss. A new beamforming architecture has been proposed to mitigate this effect under RIS-aided communications scenarios. Simulations are performed to evaluate the effectiveness of the proposed system architecture in combating the array gain loss.
ZegCLIP: Towards Adapting CLIP for Zero-shot Semantic Segmentation
Dec 12, 2022



Recently, CLIP has been applied to pixel-level zero-shot learning tasks via a two-stage scheme. The general idea is to first generate class-agnostic region proposals and then feed the cropped proposal regions to CLIP to utilize its image-level zero-shot classification capability. While effective, such a scheme requires two image encoders, one for proposal generation and one for CLIP, leading to a complicated pipeline and high computational cost. In this work, we pursue a simpler-and-efficient one-stage solution that directly extends CLIP's zero-shot prediction capability from image to pixel level. Our investigation starts with a straightforward extension as our baseline that generates semantic masks by comparing the similarity between text and patch embeddings extracted from CLIP. However, such a paradigm could heavily overfit the seen classes and fail to generalize to unseen classes. To handle this issue, we propose three simple-but-effective designs and figure out that they can significantly retain the inherent zero-shot capacity of CLIP and improve pixel-level generalization ability. Incorporating those modifications leads to an efficient zero-shot semantic segmentation system called ZegCLIP. Through extensive experiments on three public benchmarks, ZegCLIP demonstrates superior performance, outperforming the state-of-the-art methods by a large margin under both "inductive" and "transductive" zero-shot settings. In addition, compared with the two-stage method, our one-stage ZegCLIP achieves a speedup of about 5 times faster during inference. We release the code at https://github.com/ZiqinZhou66/ZegCLIP.git.
Joint Sensing and Communication Rates Control for Energy Efficient Mobile Crowd Sensing
Jan 29, 2022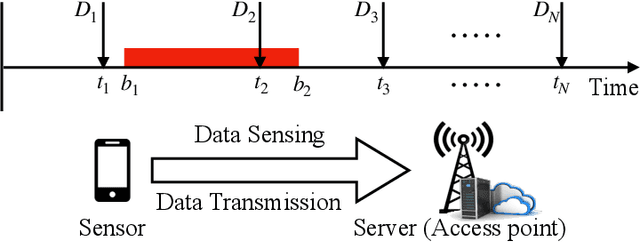


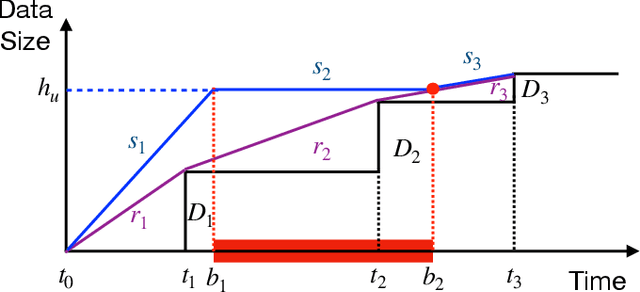
Driven by the fast development of Internet of Things (IoT) applications, tremendous data need to be collected by sensors and passed to the servers for further process. As a promising solution, the mobile crowd sensing (MCS) enables controllable sensing and transmission processes for multiple types of data in a single device. To achieve the energy efficient MCS, the data sensing and transmission over a long-term time duration should be designed accounting for the differentiated requirements of IoT tasks including data size and delay tolerance. The said design is achieved by jointly optimizing the sensing and transmission rates, which leads to a complex optimization problem due to the restraining relationship between the controlling variables as well as the existence of busy time interval during which no data can be sensed. To deal with such problem, a vital concept namely height is introduced, based on which the classical string-pulling algorithms can be applied for obtaining the corresponding optimal sensing and transmission rates. Therefore, the original rates optimization problem can be converted to a searching problem for the optimal height. Based on the property of the objective function, the upper and lower bounds of the area where the optimal height lies in are derived. The whole searching area is further divided into a series of sub-areas due to the format change of the objective function with the varying heights. Finally, the optimal height in each sub-area is obtained based on the convexity of the objective function and the global optimal height is further determined by comparing the local optimums. The above solving approach is further extended for the case with limited data buffer capacity of the server. Simulations are conducted to evaluate the performance of the proposed design.
Integrated Sensing and Over-the-Air Computation: Dual-Functional MIMO Beamforming Design
Jan 29, 2022
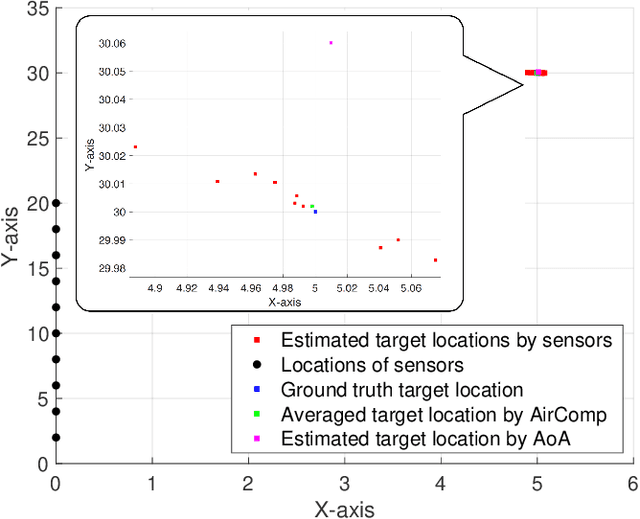
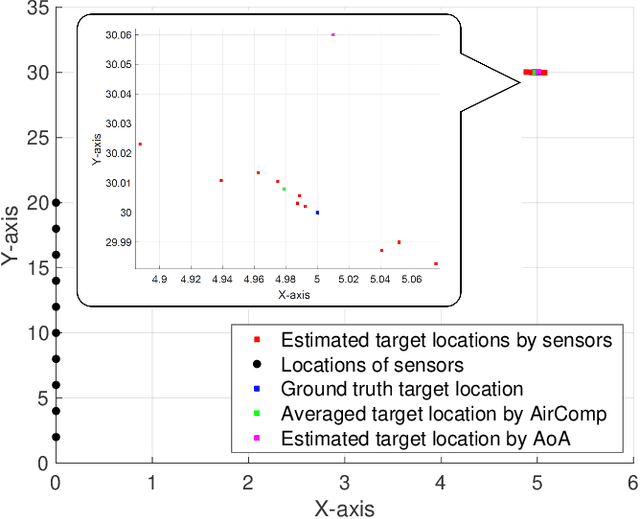

To support the unprecedented growth of the Internet of Things (IoT) applications and the access of tremendous IoT devices, two new technologies emerge recently to overcome the shortage of spectrum resources. The first one, known as integrated sensing and communication (ISAC), aims to share the spectrum bandwidth for both radar sensing and data communication. The second one, called over-the-air computation (AirComp), enables simultaneous transmission and computation of data from multiple IoT devices in the same frequency. The promising performance of ISAC and AirComp motivates the current work on developing a framework that combines the merits of both called integrated sensing and AirComp (ISAA). Two schemes are designed to support multiple-input-multiple-output (MIMO) ISAA simultaneously, namely the shared and separated schemes. The performance metrics of radar sensing and AirComp are evaluated by the mean square errors of the estimated target response matrix and the received computation results, respectively. The design challenge of MIMO ISAA lies in the joint optimization of radar sensing beamformers and data transmission beamformers at the IoT devices, and data aggregation beamformer at the server, which results in complex non-convex problem. To solve this problem, an algorithmic solution based on the technique of semidefinite relaxation is proposed. The results reveal that the beamformer at each sensor needs to account for supporting dual-functional signals in the shared scheme, while dedicated beamformers for sensing and AirComp are needed to mitigate the mutual interference between the two functionalities in the separated scheme. The use case of target location estimation based on ISAA is demonstrated in simulation to show the performance superiority.