 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRT: Masked Region Transformer for Layered Image Generation and Editing at Scale
May 26, 2026Layered image generation and editing is a fundamental capability that enables layer-wise reuse, editing, and composition of generated visual content, analogous to word-level editing in natural language. Despite its importance, this remains an underexplored area at scale. To address this gap, we present MRT, a 20B-parameter masked region diffusion model tailored for multi-layer transparent image generation and editing, trained on over 10M multilingual design samples spanning diverse aspect ratios and textual prompts. To fully leverage this scale, we make two key technical contributions. First, we unify three complementary tasks including text-to-layers, image-to-layers, and layers-to-layers within a shared masked region diffusion framework, where selective token masking enables flexible layer-wise generation and editing. Second, to enable overflow layer generation, we introduce an overflow-aware canvas layer that handles boundary inconsistencies and supports semi-transparent background synthesis, enabling complete editable layers extending beyond visible canvas boundaries. Additionally, we apply diffusion distillation to achieve 8-step, real-time multi-layer generation with minimal quality degradation. Extensive experiments demonstrate that our framework substantially outperforms prior state-of-the-art approaches, including various commercial systems, across all three tasks, establishing a new benchmark for multi-layer transparent image generation. Notably, our model significantly outperforms the concurrent Qwen-Image-Layered model in image-to-layers quality according to user-study results, while achieving 10-100\times faster inference and reducing activation GPU memory consumption by 50-90\% during image-to-layer inference.
From Tokens to Numbers: Continuous Number Modeling for SVG Generation
Feb 02, 2026For certain image generation tasks, vector graphics such as Scalable Vector Graphics (SVGs) offer clear benefits such as increased flexibility, size efficiency, and editing ease, but remain less explored than raster-based approaches. A core challenge is that the numerical, geometric parameters, which make up a large proportion of SVGs, are inefficiently encoded as long sequences of tokens. This slows training, reduces accuracy, and hurts generalization. To address these problems, we propose Continuous Number Modeling (CNM), an approach that directly models numbers as first-class, continuous values rather than discrete tokens. This formulation restores the mathematical elegance of the representation by aligning the model's inputs with the data's continuous nature, removing discretization artifacts introduced by token-based encoding. We then train a multimodal transformer on 2 million raster-to-SVG samples, followed by fine-tuning via reinforcement learning using perceptual feedback to further improve visual quality. Our approach improves training speed by over 30% while maintaining higher perceptual fidelity compared to alternative approaches. This work establishes CNM as a practical and efficient approach for high-quality vector generation, with potential for broader applications. We make our code available http://github.com/mikeogezi/CNM.
LoRA Diffusion: Zero-Shot LoRA Synthesis for Diffusion Model Personalization
Dec 03, 2024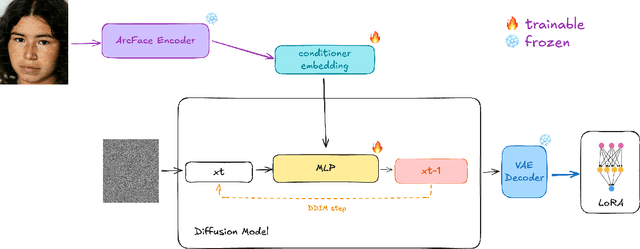
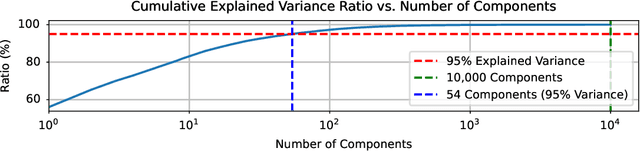
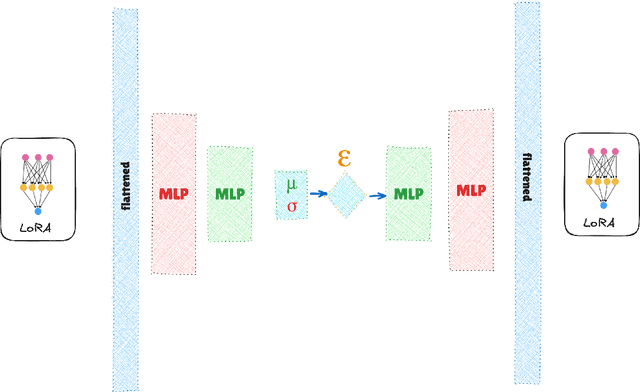
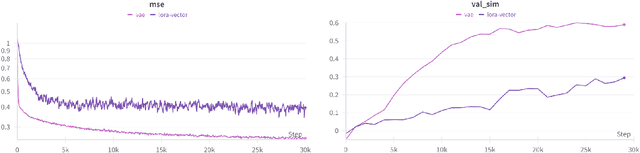
Low-Rank Adaptation (LoRA) and other parameter-efficient fine-tuning (PEFT) methods provide low-memory, storage-efficient solutions for personalizing text-to-image models. However, these methods offer little to no improvement in wall-clock training time or the number of steps needed for convergence compared to full model fine-tuning. While PEFT methods assume that shifts in generated distributions (from base to fine-tuned models) can be effectively modeled through weight changes in a low-rank subspace, they fail to leverage knowledge of common use cases, which typically focus on capturing specific styles or identities. Observing that desired outputs often comprise only a small subset of the possible domain covered by LoRA training, we propose reducing the search space by incorporating a prior over regions of interest. We demonstrate that training a hypernetwork model to generate LoRA weights can achieve competitive quality for specific domains while enabling near-instantaneous conditioning on user input, in contrast to traditional training methods that require thousands of steps.
EZIGen: Enhancing zero-shot subject-driven image generation with precise subject encoding and decoupled guidance
Sep 12, 2024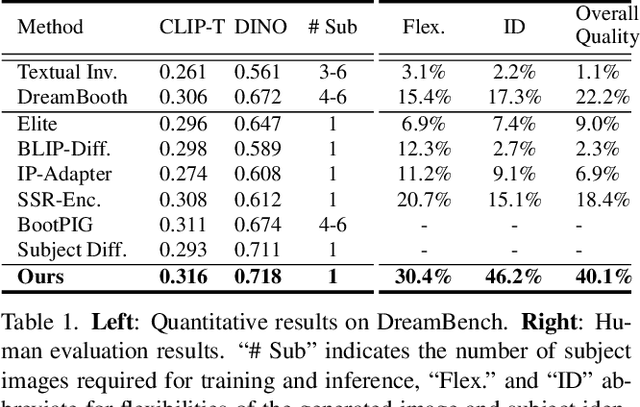


Zero-shot subject-driven image generation aims to produce images that incorporate a subject from a given example image. The challenge lies in preserving the subject's identity while aligning with the text prompt, which often requires modifying certain aspects of the subject's appearance. Despite advancements in diffusion model based methods, existing approaches still struggle to balance identity preservation with text prompt alignment. In this study, we conducted an in-depth investigation into this issue and uncovered key insights for achieving effective identity preservation while maintaining a strong balance. Our key findings include: (1) the design of the subject image encoder significantly impacts identity preservation quality, and (2) generating an initial layout is crucial for both text alignment and identity preservation. Building on these insights, we introduce a new approach called EZIGen, which employs two main strategies: a carefully crafted subject image Encoder based on the UNet architecture of the pretrained Stable Diffusion model to ensure high-quality identity transfer, following a process that decouples the guidance stages and iteratively refines the initial image layout. Through these strategies, EZIGen achieves state-of-the-art results on multiple subject-driven benchmarks with a unified model and 100 times less training data.
High Energy Density Radiative Transfer in the Diffusion Regime with Fourier Neural Operators
May 07, 2024



Radiative heat transfer is a fundamental process in high energy density physics and inertial fusion. Accurately predicting the behavior of Marshak waves across a wide range of material properties and drive conditions is crucial for design and analysis of these systems. Conventional numerical solvers and analytical approximations often face challenges in terms of accuracy and computational efficiency. In this work, we propose a novel approach to model Marshak waves using Fourier Neural Operators (FNO). We develop two FNO-based models: (1) a base model that learns the mapping between the drive condition and material properties to a solution approximation based on the widely used analytic model by Hammer & Rosen (2003), and (2) a model that corrects the inaccuracies of the analytic approximation by learning the mapping to a more accurate numerical solution. Our results demonstrate the strong generalization capabilities of the FNOs and show significant improvements in prediction accuracy compared to the base analytic model.
ToDo: Token Downsampling for Efficient Generation of High-Resolution Images
Feb 28, 2024
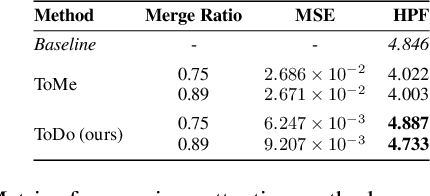

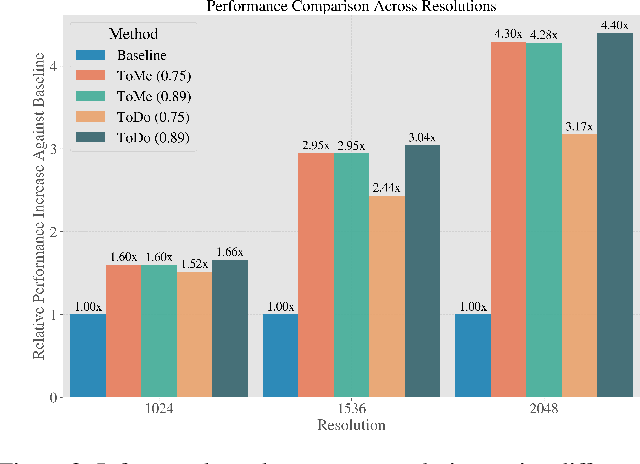
Attention mechanism has been crucial for image diffusion models, however, their quadratic computational complexity limits the sizes of images we can process within reasonable time and memory constraints. This paper investigates the importance of dense attention in generative image models, which often contain redundant features, making them suitable for sparser attention mechanisms. We propose a novel training-free method ToDo that relies on token downsampling of key and value tokens to accelerate Stable Diffusion inference by up to 2x for common sizes and up to 4.5x or more for high resolutions like 2048x2048. We demonstrate that our approach outperforms previous methods in balancing efficient throughput and fidelity.