 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA Diffusion: Zero-Shot LoRA Synthesis for Diffusion Model Personalization
Dec 03, 2024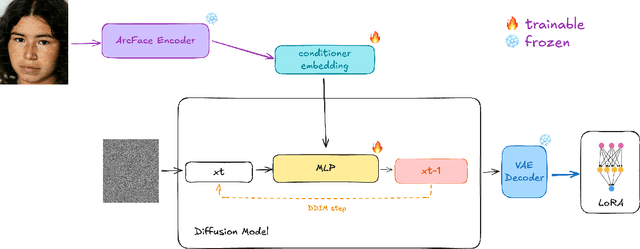
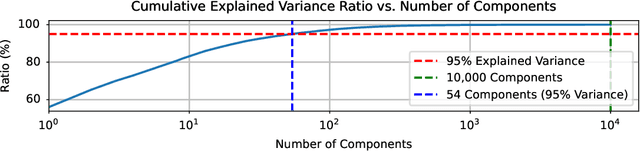
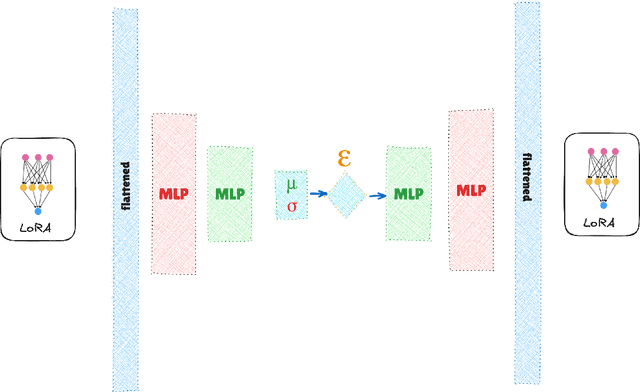
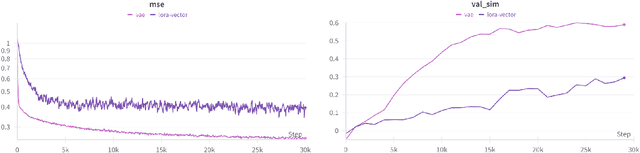
Low-Rank Adaptation (LoRA) and other parameter-efficient fine-tuning (PEFT) methods provide low-memory, storage-efficient solutions for personalizing text-to-image models. However, these methods offer little to no improvement in wall-clock training time or the number of steps needed for convergence compared to full model fine-tuning. While PEFT methods assume that shifts in generated distributions (from base to fine-tuned models) can be effectively modeled through weight changes in a low-rank subspace, they fail to leverage knowledge of common use cases, which typically focus on capturing specific styles or identities. Observing that desired outputs often comprise only a small subset of the possible domain covered by LoRA training, we propose reducing the search space by incorporating a prior over regions of interest. We demonstrate that training a hypernetwork model to generate LoRA weights can achieve competitive quality for specific domains while enabling near-instantaneous conditioning on user input, in contrast to traditional training methods that require thousands of steps.