 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Spatial Memory for Video World Models
Jun 08, 2026Video world models that maintain 3D spatial consistency across generated frames typically rely on explicit point cloud memory constructed in RGB space. This design is both computationally expensive, requiring repeated rendering and VAE encoding, and inherently lossy, as the round trip through pixel space discards rich features of the learned latent representation. In this paper, we introduce \emph{latent spatial memory} for video world models, a persistent 3D cache that stores scene information directly in the diffusion latent space, avoiding pixel-space reconstruction. Building on this, we propose Mirage, a latent-space spatial memory framework that constructs the memory by lifting latent tokens into 3D via depth-guided back-projection and queries it by synthesizing novel views through direct latent-space warping. This unified formulation eliminates both the information loss of pixel-space reconstruction and the computational burden of repeated encoding and rendering. Experiments show that latent spatial memory achieves up to \textbf{10.57}$\times$ faster end-to-end video generation and \textbf{55}$\times$ reduction in memory footprint relative to explicit 3D baselines. Leveraging the geometric prior of the diffusion model, Mirage attains state-of-the-art performance on WorldScore and strong reconstruction quality on RealEstate10K.
Points-to-3D: Structure-Aware 3D Generation with Point Cloud Priors
Mar 19, 2026Recent progress in 3D generation has been driven largely by models conditioned on images or text, while readily available 3D priors are still underused. In many real-world scenarios, the visible-region point cloud are easy to obtain from active sensors such as LiDAR or from feed-forward predictors like VGGT, offering explicit geometric constraints that current methods fail to exploit. In this work, we introduce Points-to-3D, a diffusion-based framework that leverages point cloud priors for geometry-controllable 3D asset and scene generation. Built on a latent 3D diffusion model TRELLIS, Points-to-3D first replaces pure-noise sparse structure latent initialization with a point cloud priors tailored input formulation.A structure inpainting network, trained within the TRELLIS framework on task-specific data designed to learn global structural inpainting, is then used for inference with a staged sampling strategy (structural inpainting followed by boundary refinement), completing the global geometry while preserving the visible regions of the input priors.In practice, Points-to-3D can take either accurate point-cloud priors or VGGT-estimated point clouds from single images as input. Experiments on both objects and scene scenarios consistently demonstrate superior performance over state-of-the-art baselines in terms of rendering quality and geometric fidelity, highlighting the effectiveness of explicitly embedding point-cloud priors for achieving more accurate and structurally controllable 3D generation.
Let Your Video Listen to Your Music!
Jun 23, 2025Aligning the rhythm of visual motion in a video with a given music track is a practical need in multimedia production, yet remains an underexplored task in autonomous video editing. Effective alignment between motion and musical beats enhances viewer engagement and visual appeal, particularly in music videos, promotional content, and cinematic editing. Existing methods typically depend on labor-intensive manual cutting, speed adjustments, or heuristic-based editing techniques to achieve synchronization. While some generative models handle joint video and music generation, they often entangle the two modalities, limiting flexibility in aligning video to music beats while preserving the full visual content. In this paper, we propose a novel and efficient framework, termed MVAA (Music-Video Auto-Alignment), that automatically edits video to align with the rhythm of a given music track while preserving the original visual content. To enhance flexibility, we modularize the task into a two-step process in our MVAA: aligning motion keyframes with audio beats, followed by rhythm-aware video inpainting. Specifically, we first insert keyframes at timestamps aligned with musical beats, then use a frame-conditioned diffusion model to generate coherent intermediate frames, preserving the original video's semantic content. Since comprehensive test-time training can be time-consuming, we adopt a two-stage strategy: pretraining the inpainting module on a small video set to learn general motion priors, followed by rapid inference-time fine-tuning for video-specific adaptation. This hybrid approach enables adaptation within 10 minutes with one epoch on a single NVIDIA 4090 GPU using CogVideoX-5b-I2V as the backbone. Extensive experiments show that our approach can achieve high-quality beat alignment and visual smoothness.
Frame-wise Conditioning Adaptation for Fine-Tuning Diffusion Models in Text-to-Video Prediction
Mar 17, 2025Text-video prediction (TVP) is a downstream video generation task that requires a model to produce subsequent video frames given a series of initial video frames and text describing the required motion. In practice TVP methods focus on a particular category of videos depicting manipulations of objects carried out by human beings or robot arms. Previous methods adapt models pre-trained on text-to-image tasks, and thus tend to generate video that lacks the required continuity. A natural progression would be to leverage more recent pre-trained text-to-video (T2V) models. This approach is rendered more challenging by the fact that the most common fine-tuning technique, low-rank adaptation (LoRA), yields undesirable results. In this work, we propose an adaptation-based strategy we label Frame-wise Conditioning Adaptation (FCA). Within the module, we devise a sub-module that produces frame-wise text embeddings from the input text, which acts as an additional text condition to aid generation. We use FCA to fine-tune the T2V model, which incorporates the initial frame(s) as an extra condition. We compare and discuss the more effective strategy for injecting such embeddings into the T2V model. We conduct extensive ablation studies on our design choices with quantitative and qualitative performance analysis. Our approach establishes a new state-of-the-art for the task of TVP. The project page is at https://github.com/Cuberick-Orion/FCA .
Training-Free Motion-Guided Video Generation with Enhanced Temporal Consistency Using Motion Consistency Loss
Jan 13, 2025



In this paper, we address the challenge of generating temporally consistent videos with motion guidance. While many existing methods depend on additional control modules or inference-time fine-tuning, recent studies suggest that effective motion guidance is achievable without altering the model architecture or requiring extra training. Such approaches offer promising compatibility with various video generation foundation models. However, existing training-free methods often struggle to maintain consistent temporal coherence across frames or to follow guided motion accurately. In this work, we propose a simple yet effective solution that combines an initial-noise-based approach with a novel motion consistency loss, the latter being our key innovation. Specifically, we capture the inter-frame feature correlation patterns of intermediate features from a video diffusion model to represent the motion pattern of the reference video. We then design a motion consistency loss to maintain similar feature correlation patterns in the generated video, using the gradient of this loss in the latent space to guide the generation process for precise motion control. This approach improves temporal consistency across various motion control tasks while preserving the benefits of a training-free setup. Extensive experiments show that our method sets a new standard for efficient, temporally coherent video generation.
EZIGen: Enhancing zero-shot subject-driven image generation with precise subject encoding and decoupled guidance
Sep 12, 2024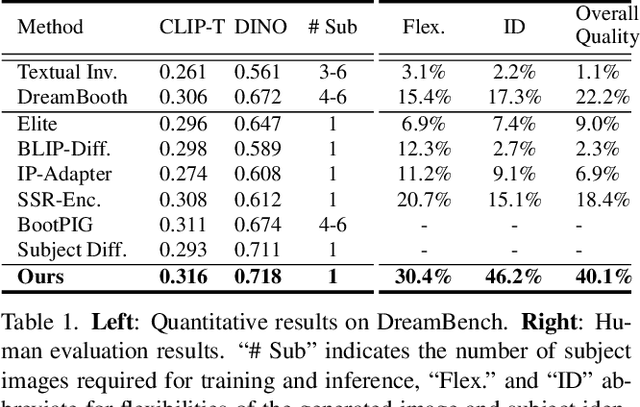


Zero-shot subject-driven image generation aims to produce images that incorporate a subject from a given example image. The challenge lies in preserving the subject's identity while aligning with the text prompt, which often requires modifying certain aspects of the subject's appearance. Despite advancements in diffusion model based methods, existing approaches still struggle to balance identity preservation with text prompt alignment. In this study, we conducted an in-depth investigation into this issue and uncovered key insights for achieving effective identity preservation while maintaining a strong balance. Our key findings include: (1) the design of the subject image encoder significantly impacts identity preservation quality, and (2) generating an initial layout is crucial for both text alignment and identity preservation. Building on these insights, we introduce a new approach called EZIGen, which employs two main strategies: a carefully crafted subject image Encoder based on the UNet architecture of the pretrained Stable Diffusion model to ensure high-quality identity transfer, following a process that decouples the guidance stages and iteratively refines the initial image layout. Through these strategies, EZIGen achieves state-of-the-art results on multiple subject-driven benchmarks with a unified model and 100 times less training data.
Multiview Detection with Cardboard Human Modeling
Jul 10, 2022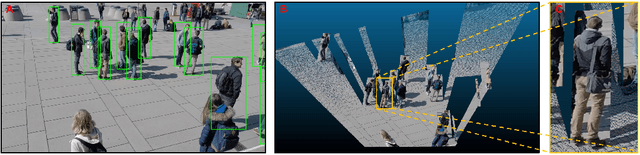
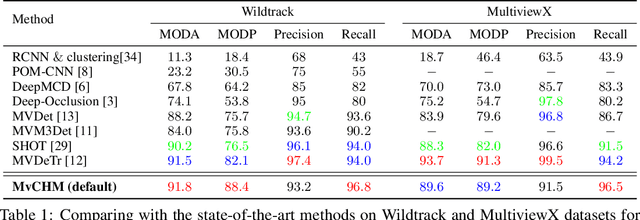
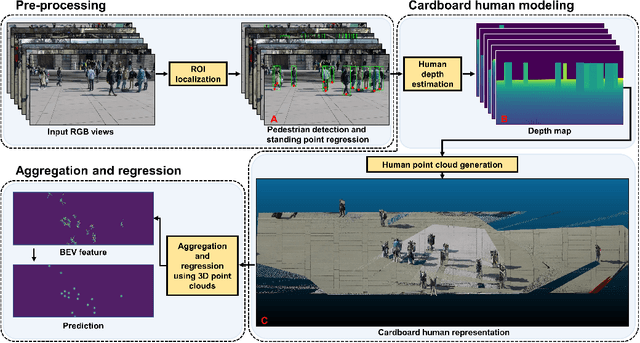

Multiview detection uses multiple calibrated cameras with overlapping fields of views to locate occluded pedestrians. In this field, existing methods typically adopt a "human modeling - aggregation" strategy. To find robust pedestrian representations, some intuitively use locations of detected 2D bounding boxes, while others use entire frame features projected to the ground plane. However, the former does not consider human appearance and leads to many ambiguities, and the latter suffers from projection errors due to the lack of accurate height of the human torso and head. In this paper, we propose a new pedestrian representation scheme based on human point clouds modeling. Specifically, using ray tracing for holistic human depth estimation, we model pedestrians as upright, thin cardboard point clouds on the ground. Then, we aggregate the point clouds of the pedestrian cardboard across multiple views for a final decision. Compared with existing representations, the proposed method explicitly leverages human appearance and reduces projection errors significantly by relatively accurate height estimation. On two standard evaluation benchmarks, the proposed method achieves very competitive results.
ABCP: Automatic Block-wise and Channel-wise Network Pruning via Joint Search
Oct 08, 2021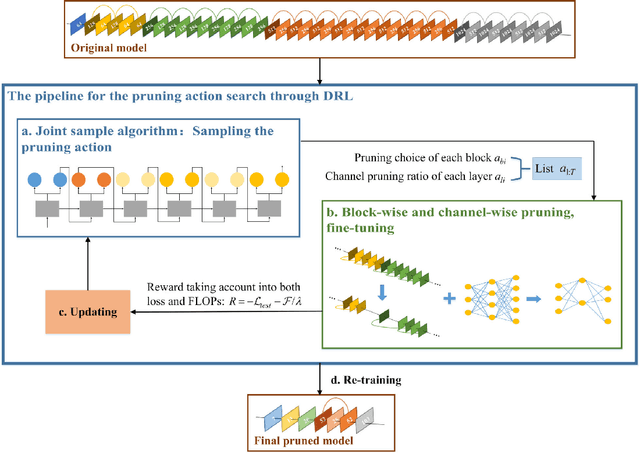
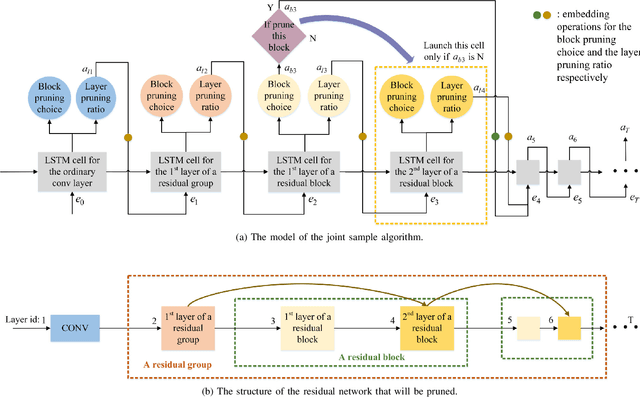


Currently, an increasing number of model pruning methods are proposed to resolve the contradictions between the computer powers required by the deep learning models and the resource-constrained devices. However, most of the traditional rule-based network pruning methods can not reach a sufficient compression ratio with low accuracy loss and are time-consuming as well as laborious. In this paper, we propose Automatic Block-wise and Channel-wise Network Pruning (ABCP) to jointly search the block-wise and channel-wise pruning action with deep reinforcement learning. A joint sample algorithm is proposed to simultaneously generate the pruning choice of each residual block and the channel pruning ratio of each convolutional layer from the discrete and continuous search space respectively. The best pruning action taking both the accuracy and the complexity of the model into account is obtained finally. Compared with the traditional rule-based pruning method, this pipeline saves human labor and achieves a higher compression ratio with lower accuracy loss. Tested on the mobile robot detection dataset, the pruned YOLOv3 model saves 99.5% FLOPs, reduces 99.5% parameters, and achieves 37.3 times speed up with only 2.8% mAP loss. The results of the transfer task on the sim2real detection dataset also show that our pruned model has much better robustness performance.