 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVHOI: Bridge Multi-view Condition to Complex Human-Object Interaction Video Reenactment via 3D Foundation Model
Mar 16, 2026Human-Object Interaction (HOI) video reenactment with realistic motion remains a frontier in expressive digital human creation. Existing approaches primarily handle simple image-plane motion (e.g., in-plane translations), struggling with complex non-planar manipulations like out-of-plane reorientation. In this paper, we propose MVHOI, a two-stage HOI video reenactment framework that bridges multi-view reference conditions and video foundation models via a 3D Foundation Model (3DFM). The 3DFM first produces view-consistent object priors conditioned on implicit motion dynamics across novel viewpoints. A controllable video generation model then synthesizes high-fidelity object texture by incorporating multi-view reference images, ensuring appearance consistency via a reasonable retrieval mechanism. By enabling these two stages to mutually reinforce one another during the inference phase, our framework shows superior performance in generating long-duration HOI videos with intricate object manipulations. Extensive experiments show substantial improvements over prior approaches, especially for HOI with complex 3D object manipulations.
Bridging Human Interpretation and Machine Representation: A Landscape of Qualitative Data Analysis in the LLM Era
Jan 16, 2026LLMs are increasingly used to support qualitative research, yet existing systems produce outputs that vary widely--from trace-faithful summaries to theory-mediated explanations and system models. To make these differences explicit, we introduce a 4$\times$4 landscape crossing four levels of meaning-making (descriptive, categorical, interpretive, theoretical) with four levels of modeling (static structure, stages/timelines, causal pathways, feedback dynamics). Applying the landscape to prior LLM-based automation highlights a strong skew toward low-level meaning and low-commitment representations, with few reliable attempts at interpretive/theoretical inference or dynamical modeling. Based on the revealed gap, we outline an agenda for applying and building LLM-systems that make their interpretive and modeling commitments explicit, selectable, and governable.
Wound3DAssist: A Practical Framework for 3D Wound Assessment
Aug 25, 2025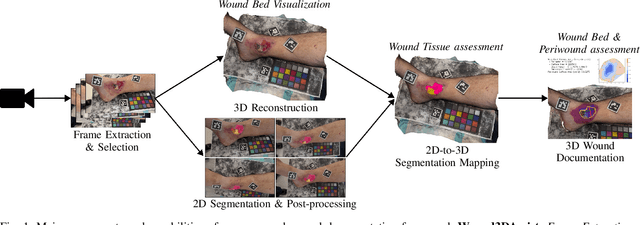
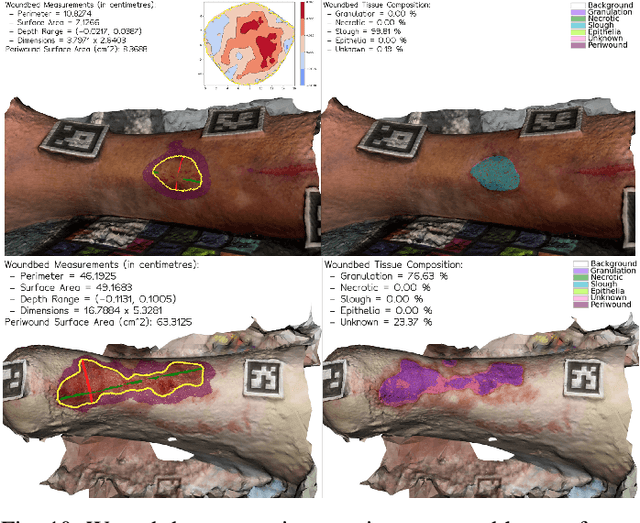
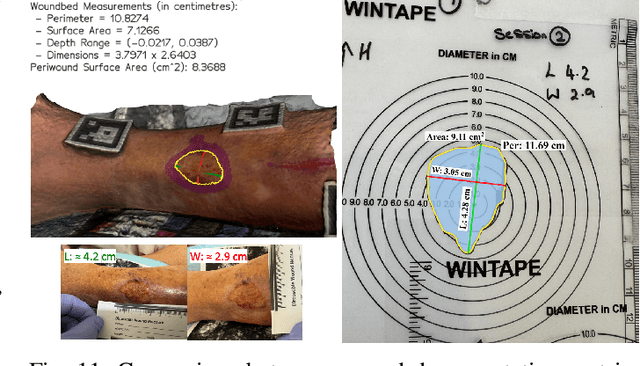
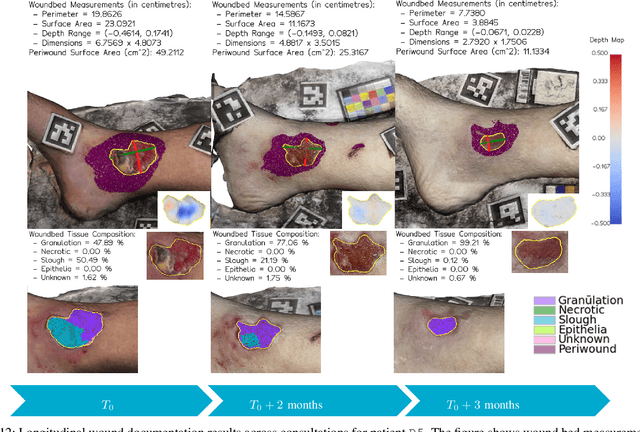
Managing chronic wounds remains a major healthcare challenge, with clinical assessment often relying on subjective and time-consuming manual documentation methods. Although 2D digital videometry frameworks aided the measurement process, these approaches struggle with perspective distortion, a limited field of view, and an inability to capture wound depth, especially in anatomically complex or curved regions. To overcome these limitations, we present Wound3DAssist, a practical framework for 3D wound assessment using monocular consumer-grade videos. Our framework generates accurate 3D models from short handheld smartphone video recordings, enabling non-contact, automatic measurements that are view-independent and robust to camera motion. We integrate 3D reconstruction, wound segmentation, tissue classification, and periwound analysis into a modular workflow. We evaluate Wound3DAssist across digital models with known geometry, silicone phantoms, and real patients. Results show that the framework supports high-quality wound bed visualization, millimeter-level accuracy, and reliable tissue composition analysis. Full assessments are completed in under 20 minutes, demonstrating feasibility for real-world clinical use.
GS-2DGS: Geometrically Supervised 2DGS for Reflective Object Reconstruction
Jun 16, 20253D modeling of highly reflective objects remains challenging due to strong view-dependent appearances. While previous SDF-based methods can recover high-quality meshes, they are often time-consuming and tend to produce over-smoothed surfaces. In contrast, 3D Gaussian Splatting (3DGS) offers the advantage of high speed and detailed real-time rendering, but extracting surfaces from the Gaussians can be noisy due to the lack of geometric constraints. To bridge the gap between these approaches, we propose a novel reconstruction method called GS-2DGS for reflective objects based on 2D Gaussian Splatting (2DGS). Our approach combines the rapid rendering capabilities of Gaussian Splatting with additional geometric information from foundation models. Experimental results on synthetic and real datasets demonstrate that our method significantly outperforms Gaussian-based techniques in terms of reconstruction and relighting and achieves performance comparable to SDF-based methods while being an order of magnitude faster. Code is available at https://github.com/hirotong/GS2DGS
Mastering Agile Jumping Skills from Simple Practices with Iterative Learning Control
Aug 05, 2024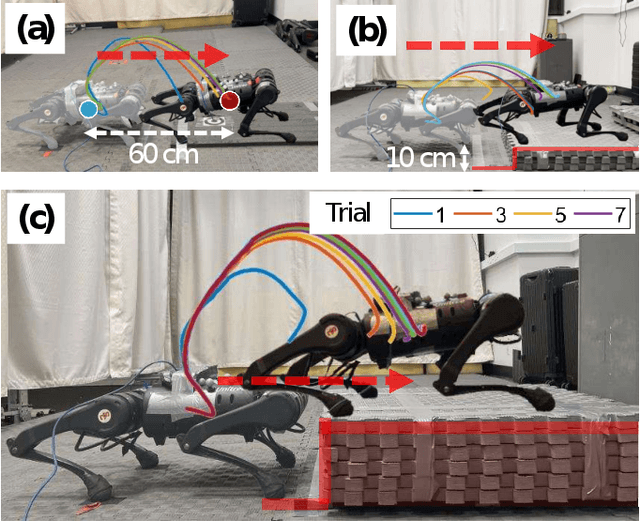
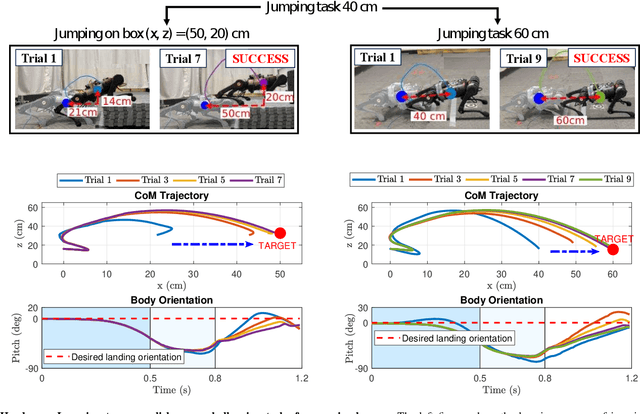
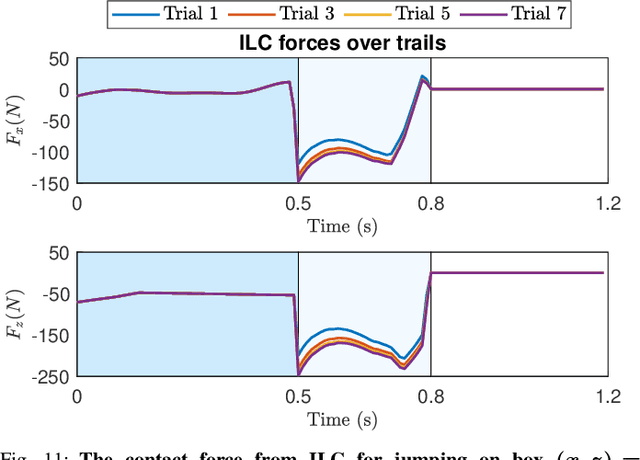
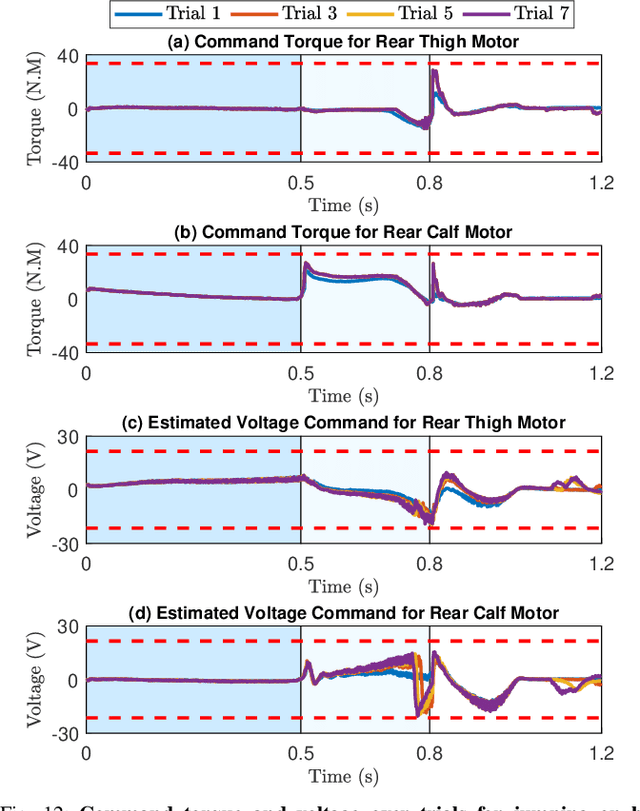
Achieving precise target jumping with legged robots poses a significant challenge due to the long flight phase and the uncertainties inherent in contact dynamics and hardware. Forcefully attempting these agile motions on hardware could result in severe failures and potential damage. Motivated by these challenging problems, we propose an Iterative Learning Control (ILC) approach that aims to learn and refine jumping skills from easy to difficult, instead of directly learning these challenging tasks. We verify that learning from simplicity can enhance safety and target jumping accuracy over trials. Compared to other ILC approaches for legged locomotion, our method can tackle the problem of a long flight phase where control input is not available. In addition, our approach allows the robot to apply what it learns from a simple jumping task to accomplish more challenging tasks within a few trials directly in hardware, instead of learning from scratch. We validate the method via extensive experiments in the A1 model and hardware for various jumping tasks. Starting from a small jump (e.g., a forward leap of 40cm), our learning approach empowers the robot to accomplish a variety of challenging targets, including jumping onto a 20cm high box, jumping to a greater distance of up to 60cm, as well as performing jumps while carrying an unknown payload of 2kg. Our framework can allow the robot to reach the desired position and orientation targets with approximate errors of 1cm and 1 degree within a few trials.
Adaptive-Frequency Model Learning and Predictive Control for Dynamic Maneuvers on Legged Robots
Jul 20, 2024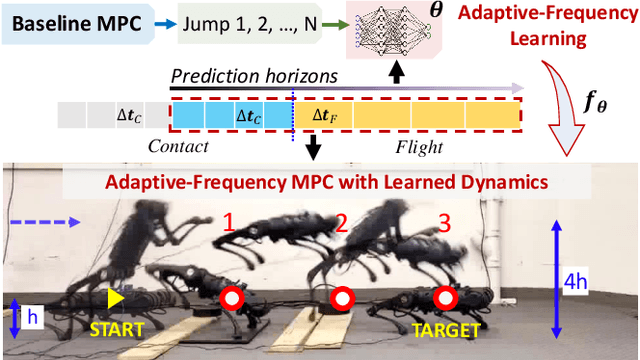
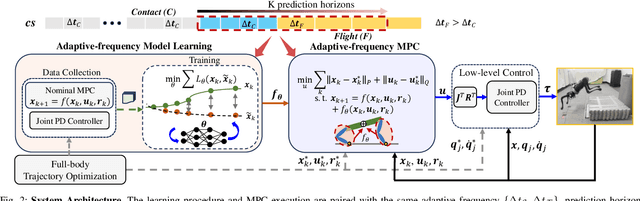


Achieving both target accuracy and robustness in dynamic maneuvers with long flight phases, such as high or long jumps, has been a significant challenge for legged robots. To address this challenge, we propose a novel learning-based control approach consisting of model learning and model predictive control (MPC) utilizing an adaptive frequency scheme. Compared to existing MPC techniques, we learn a model directly from experiments, accounting not only for leg dynamics but also for modeling errors and unknown dynamics mismatch in hardware and during contact. Additionally, learning the model with adaptive frequency allows us to cover the entire flight phase and final jumping target, enhancing the prediction accuracy of the jumping trajectory. Using the learned model, we also design an adaptive-frequency MPC to effectively leverage different jumping phases and track the target accurately. In hardware experiments with a Unitree A1 robot, we demonstrate that our approach outperforms baseline MPC using a nominal model, reducing the jumping distance error up to 8 times. We achieve jumping distance errors of less than 3 percent during continuous jumping on uneven terrain with randomly-placed perturbations of random heights (up to 4 cm or 27 percent of the robot's standing height). Our approach obtains distance errors of 1-2 cm on 34 single and continuous jumps with different jumping targets and model uncertainties.
SOAF: Scene Occlusion-aware Neural Acoustic Field
Jul 02, 2024



This paper tackles the problem of novel view audio-visual synthesis along an arbitrary trajectory in an indoor scene, given the audio-video recordings from other known trajectories of the scene. Existing methods often overlook the effect of room geometry, particularly wall occlusion to sound propagation, making them less accurate in multi-room environments. In this work, we propose a new approach called Scene Occlusion-aware Acoustic Field (SOAF) for accurate sound generation. Our approach derives a prior for sound energy field using distance-aware parametric sound-propagation modelling and then transforms it based on scene transmittance learned from the input video. We extract features from the local acoustic field centred around the receiver using a Fibonacci Sphere to generate binaural audio for novel views with a direction-aware attention mechanism. Extensive experiments on the real dataset~\emph{RWAVS} and the synthetic dataset~\emph{SoundSpaces} demonstrate that our method outperforms previous state-of-the-art techniques in audio generation. Project page: https://github.com/huiyu-gao/SOAF/.
HashPoint: Accelerated Point Searching and Sampling for Neural Rendering
Apr 22, 2024
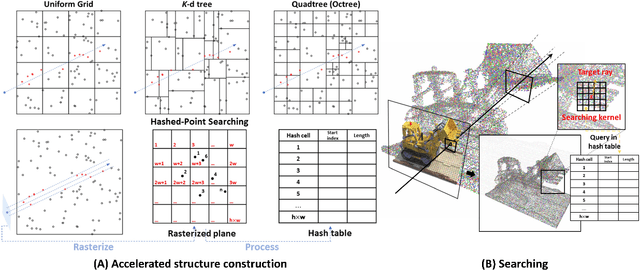

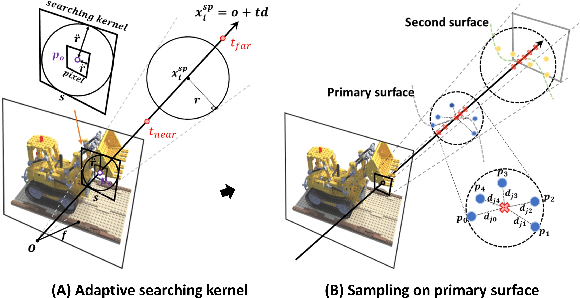
In this paper, we address the problem of efficient point searching and sampling for volume neural rendering. Within this realm, two typical approaches are employed: rasterization and ray tracing. The rasterization-based methods enable real-time rendering at the cost of increased memory and lower fidelity. In contrast, the ray-tracing-based methods yield superior quality but demand longer rendering time. We solve this problem by our HashPoint method combining these two strategies, leveraging rasterization for efficient point searching and sampling, and ray marching for rendering. Our method optimizes point searching by rasterizing points within the camera's view, organizing them in a hash table, and facilitating rapid searches. Notably, we accelerate the rendering process by adaptive sampling on the primary surface encountered by the ray. Our approach yields substantial speed-up for a range of state-of-the-art ray-tracing-based methods, maintaining equivalent or superior accuracy across synthetic and real test datasets. The code will be available at https://jiahao-ma.github.io/hashpoint/.
* CVPR2024 Highlight
Homography Guided Temporal Fusion for Road Line and Marking Segmentation
Apr 11, 2024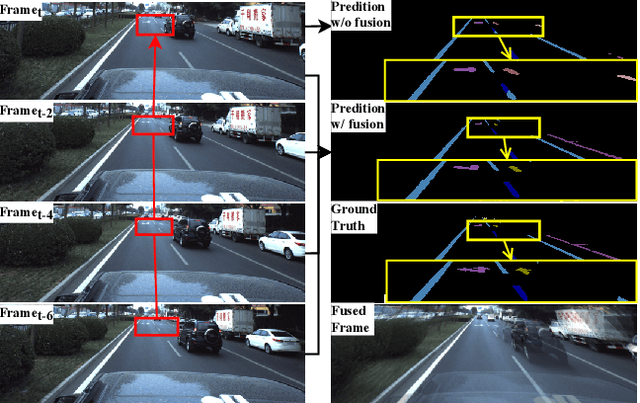
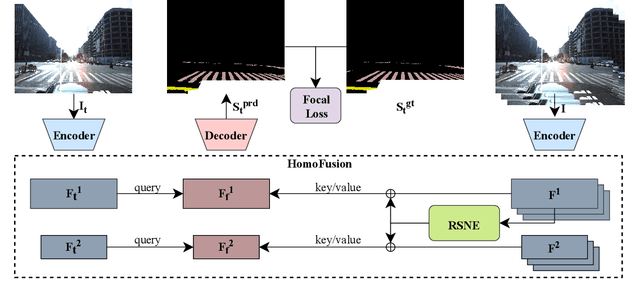


Reliable segmentation of road lines and markings is critical to autonomous driving. Our work is motivated by the observations that road lines and markings are (1) frequently occluded in the presence of moving vehicles, shadow, and glare and (2) highly structured with low intra-class shape variance and overall high appearance consistency. To solve these issues, we propose a Homography Guided Fusion (HomoFusion) module to exploit temporally-adjacent video frames for complementary cues facilitating the correct classification of the partially occluded road lines or markings. To reduce computational complexity, a novel surface normal estimator is proposed to establish spatial correspondences between the sampled frames, allowing the HomoFusion module to perform a pixel-to-pixel attention mechanism in updating the representation of the occluded road lines or markings. Experiments on ApolloScape, a large-scale lane mark segmentation dataset, and ApolloScape Night with artificial simulated night-time road conditions, demonstrate that our method outperforms other existing SOTA lane mark segmentation models with less than 9\% of their parameters and computational complexity. We show that exploiting available camera intrinsic data and ground plane assumption for cross-frame correspondence can lead to a light-weight network with significantly improved performances in speed and accuracy. We also prove the versatility of our HomoFusion approach by applying it to the problem of water puddle segmentation and achieving SOTA performance.
Syn3DWound: A Synthetic Dataset for 3D Wound Bed Analysis
Nov 27, 2023


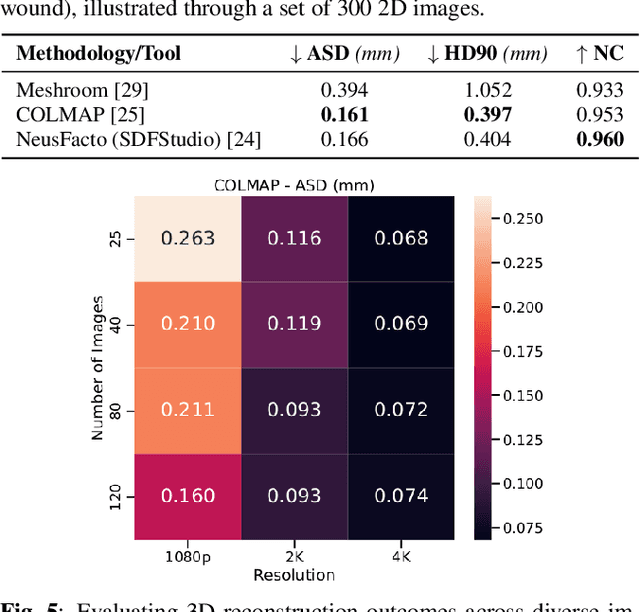
Wound management poses a significant challenge, particularly for bedridden patients and the elderly. Accurate diagnostic and healing monitoring can significantly benefit from modern image analysis, providing accurate and precise measurements of wounds. Despite several existing techniques, the shortage of expansive and diverse training datasets remains a significant obstacle to constructing machine learning-based frameworks. This paper introduces Syn3DWound, an open-source dataset of high-fidelity simulated wounds with 2D and 3D annotations. We propose baseline methods and a benchmarking framework for automated 3D morphometry analysis and 2D/3D wound segmentation.