 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Priors for Identity-Disentangled Open-Set Privacy-Preserving Video FER
Mar 22, 2026Facial expression recognition relies on facial data that inherently expose identity and thus raise significant privacy concerns. Current privacy-preserving methods typically fail in realistic open-set video settings where identities are unknown, and identity labels are unavailable. We propose a two-stage framework for video-based privacy-preserving FER in challenging open-set settings that requires no identity labels at any stage. To decouple privacy and utility, we first train an identity-suppression network using intra- and inter-video knowledge priors derived from real-world videos without identity labels. This network anonymizes identity while preserving expressive cues. A subsequent denoising module restores expression-related information and helps recover FER performance. Furthermore, we introduce a falsification-based validation method that uses recognition priors to rigorously evaluate privacy robustness without requiring annotated identity labels. Experiments on three video datasets demonstrate that our method effectively protects privacy while maintaining FER accuracy comparable to identity-supervised baselines.
Facial Spatiotemporal Graphs: Leveraging the 3D Facial Surface for Remote Physiological Measurement
Jan 20, 2026Facial remote photoplethysmography (rPPG) methods estimate physiological signals by modeling subtle color changes on the 3D facial surface over time. However, existing methods fail to explicitly align their receptive fields with the 3D facial surface-the spatial support of the rPPG signal. To address this, we propose the Facial Spatiotemporal Graph (STGraph), a novel representation that encodes facial color and structure using 3D facial mesh sequences-enabling surface-aligned spatiotemporal processing. We introduce MeshPhys, a lightweight spatiotemporal graph convolutional network that operates on the STGraph to estimate physiological signals. Across four benchmark datasets, MeshPhys achieves state-of-the-art or competitive performance in both intra- and cross-dataset settings. Ablation studies show that constraining the model's receptive field to the facial surface acts as a strong structural prior, and that surface-aligned, 3D-aware node features are critical for robustly encoding facial surface color. Together, the STGraph and MeshPhys constitute a novel, principled modeling paradigm for facial rPPG, enabling robust, interpretable, and generalizable estimation. Code is available at https://samcantrill.github.io/facial-stgraph-rppg/ .
Quality-Driven and Diversity-Aware Sample Expansion for Robust Marine Obstacle Segmentation
Dec 16, 2025Marine obstacle detection demands robust segmentation under challenging conditions, such as sun glitter, fog, and rapidly changing wave patterns. These factors degrade image quality, while the scarcity and structural repetition of marine datasets limit the diversity of available training data. Although mask-conditioned diffusion models can synthesize layout-aligned samples, they often produce low-diversity outputs when conditioned on low-entropy masks and prompts, limiting their utility for improving robustness. In this paper, we propose a quality-driven and diversity-aware sample expansion pipeline that generates training data entirely at inference time, without retraining the diffusion model. The framework combines two key components:(i) a class-aware style bank that constructs high-entropy, semantically grounded prompts, and (ii) an adaptive annealing sampler that perturbs early conditioning, while a COD-guided proportional controller regulates this perturbation to boost diversity without compromising layout fidelity. Across marine obstacle benchmarks, augmenting training data with these controlled synthetic samples consistently improves segmentation performance across multiple backbones and increases visual variation in rare and texture-sensitive classes.
3D Gaussian Representations with Motion Trajectory Field for Dynamic Scene Reconstruction
Aug 10, 2025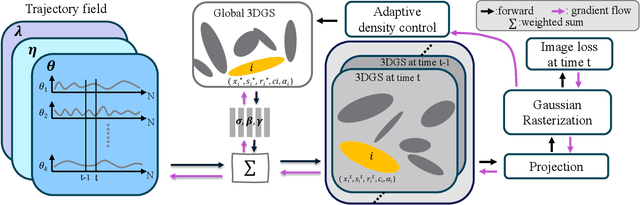
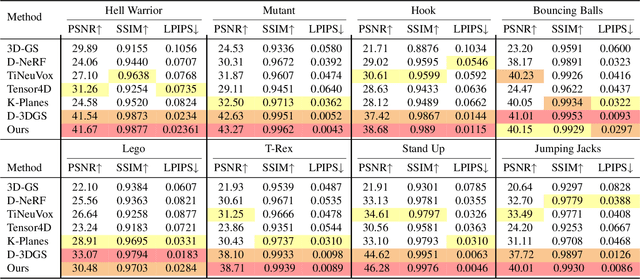
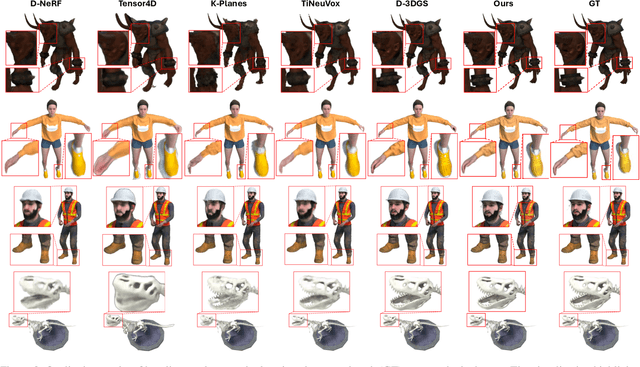

This paper addresses the challenge of novel-view synthesis and motion reconstruction of dynamic scenes from monocular video, which is critical for many robotic applications. Although Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have demonstrated remarkable success in rendering static scenes, extending them to reconstruct dynamic scenes remains challenging. In this work, we introduce a novel approach that combines 3DGS with a motion trajectory field, enabling precise handling of complex object motions and achieving physically plausible motion trajectories. By decoupling dynamic objects from static background, our method compactly optimizes the motion trajectory field. The approach incorporates time-invariant motion coefficients and shared motion trajectory bases to capture intricate motion patterns while minimizing optimization complexity. Extensive experiments demonstrate that our approach achieves state-of-the-art results in both novel-view synthesis and motion trajectory recovery from monocular video, advancing the capabilities of dynamic scene reconstruction.
GS-2DGS: Geometrically Supervised 2DGS for Reflective Object Reconstruction
Jun 16, 20253D modeling of highly reflective objects remains challenging due to strong view-dependent appearances. While previous SDF-based methods can recover high-quality meshes, they are often time-consuming and tend to produce over-smoothed surfaces. In contrast, 3D Gaussian Splatting (3DGS) offers the advantage of high speed and detailed real-time rendering, but extracting surfaces from the Gaussians can be noisy due to the lack of geometric constraints. To bridge the gap between these approaches, we propose a novel reconstruction method called GS-2DGS for reflective objects based on 2D Gaussian Splatting (2DGS). Our approach combines the rapid rendering capabilities of Gaussian Splatting with additional geometric information from foundation models. Experimental results on synthetic and real datasets demonstrate that our method significantly outperforms Gaussian-based techniques in terms of reconstruction and relighting and achieves performance comparable to SDF-based methods while being an order of magnitude faster. Code is available at https://github.com/hirotong/GS2DGS
MoKD: Multi-Task Optimization for Knowledge Distillation
May 13, 2025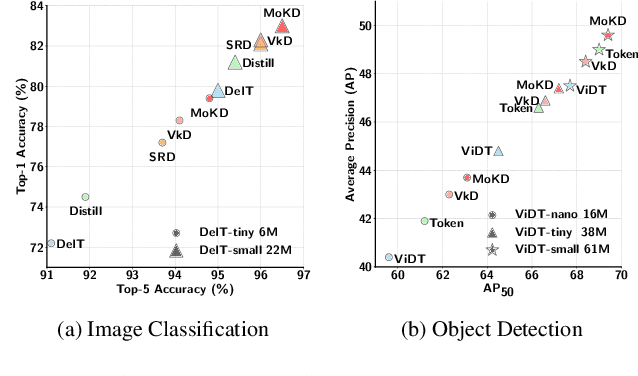
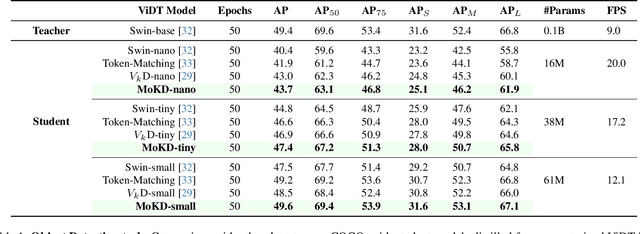
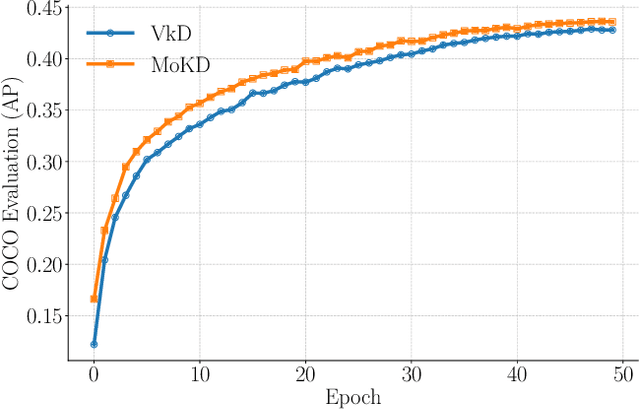
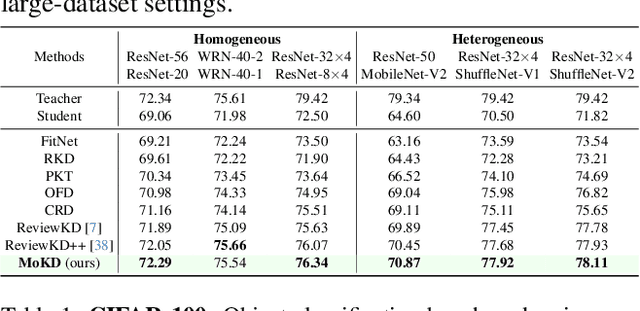
Compact models can be effectively trained through Knowledge Distillation (KD), a technique that transfers knowledge from larger, high-performing teacher models. Two key challenges in Knowledge Distillation (KD) are: 1) balancing learning from the teacher's guidance and the task objective, and 2) handling the disparity in knowledge representation between teacher and student models. To address these, we propose Multi-Task Optimization for Knowledge Distillation (MoKD). MoKD tackles two main gradient issues: a) Gradient Conflicts, where task-specific and distillation gradients are misaligned, and b) Gradient Dominance, where one objective's gradient dominates, causing imbalance. MoKD reformulates KD as a multi-objective optimization problem, enabling better balance between objectives. Additionally, it introduces a subspace learning framework to project feature representations into a high-dimensional space, improving knowledge transfer. Our MoKD is demonstrated to outperform existing methods through extensive experiments on image classification using the ImageNet-1K dataset and object detection using the COCO dataset, achieving state-of-the-art performance with greater efficiency. To the best of our knowledge, MoKD models also achieve state-of-the-art performance compared to models trained from scratch.
Open Set Label Shift with Test Time Out-of-Distribution Reference
May 09, 2025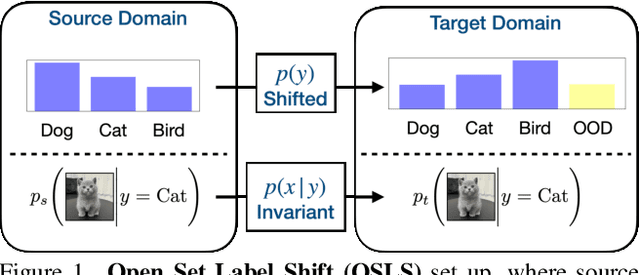
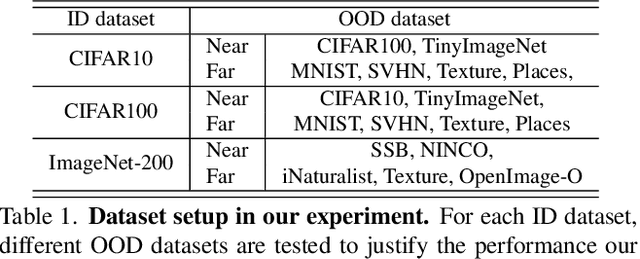
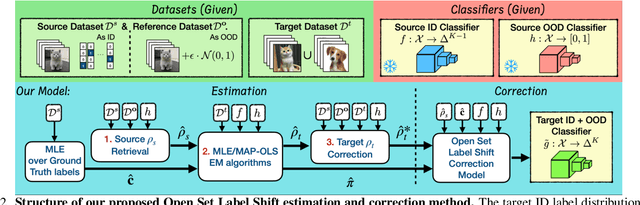

Open set label shift (OSLS) occurs when label distributions change from a source to a target distribution, and the target distribution has an additional out-of-distribution (OOD) class. In this work, we build estimators for both source and target open set label distributions using a source domain in-distribution (ID) classifier and an ID/OOD classifier. With reasonable assumptions on the ID/OOD classifier, the estimators are assembled into a sequence of three stages: 1) an estimate of the source label distribution of the OOD class, 2) an EM algorithm for Maximum Likelihood estimates (MLE) of the target label distribution, and 3) an estimate of the target label distribution of OOD class under relaxed assumptions on the OOD classifier. The sampling errors of estimates in 1) and 3) are quantified with a concentration inequality. The estimation result allows us to correct the ID classifier trained on the source distribution to the target distribution without retraining. Experiments on a variety of open set label shift settings demonstrate the effectiveness of our model. Our code is available at https://github.com/ChangkunYe/OpenSetLabelShift.
Learning from Noisy Labels with Contrastive Co-Transformer
Mar 04, 2025



Deep learning with noisy labels is an interesting challenge in weakly supervised learning. Despite their significant learning capacity, CNNs have a tendency to overfit in the presence of samples with noisy labels. Alleviating this issue, the well known Co-Training framework is used as a fundamental basis for our work. In this paper, we introduce a Contrastive Co-Transformer framework, which is simple and fast, yet able to improve the performance by a large margin compared to the state-of-the-art approaches. We argue the robustness of transformers when dealing with label noise. Our Contrastive Co-Transformer approach is able to utilize all samples in the dataset, irrespective of whether they are clean or noisy. Transformers are trained by a combination of contrastive loss and classification loss. Extensive experimental results on corrupted data from six standard benchmark datasets including Clothing1M, demonstrate that our Contrastive Co-Transformer is superior to existing state-of-the-art methods.
DGNS: Deformable Gaussian Splatting and Dynamic Neural Surface for Monocular Dynamic 3D Reconstruction
Dec 05, 2024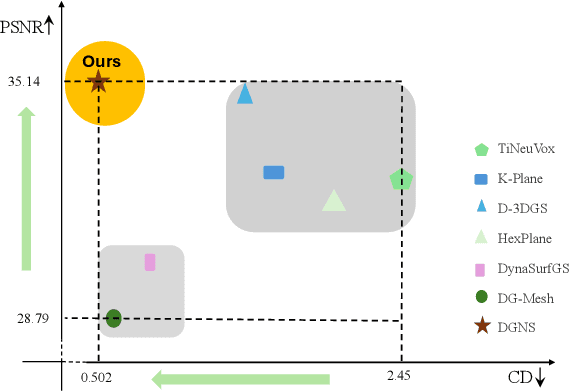
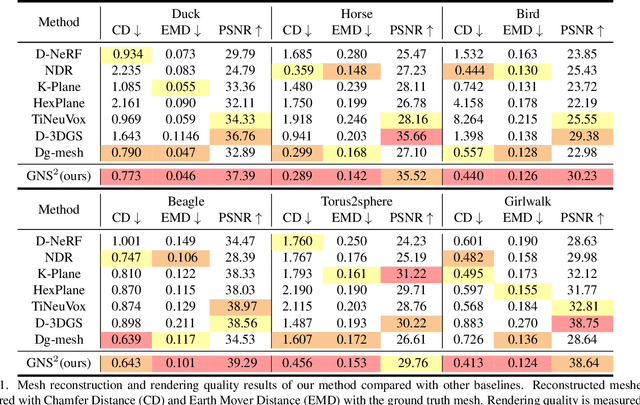

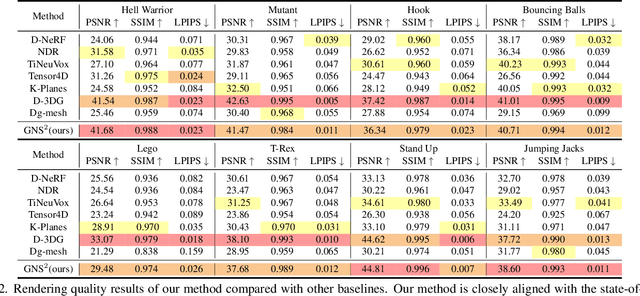
Dynamic scene reconstruction from monocular video is critical for real-world applications. This paper tackles the dual challenges of dynamic novel-view synthesis and 3D geometry reconstruction by introducing a hybrid framework: Deformable Gaussian Splatting and Dynamic Neural Surfaces (DGNS), in which both modules can leverage each other for both tasks. During training, depth maps generated by the deformable Gaussian splatting module guide the ray sampling for faster processing and provide depth supervision within the dynamic neural surface module to improve geometry reconstruction. Simultaneously, the dynamic neural surface directs the distribution of Gaussian primitives around the surface, enhancing rendering quality. To further refine depth supervision, we introduce a depth-filtering process on depth maps derived from Gaussian rasterization. Extensive experiments on public datasets demonstrate that DGNS achieves state-of-the-art performance in both novel-view synthesis and 3D reconstruction.
Facial Expression Recognition with Controlled Privacy Preservation and Feature Compensation
Dec 03, 2024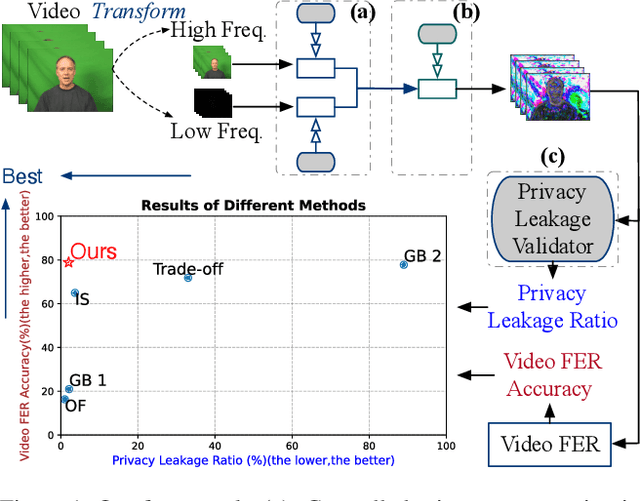
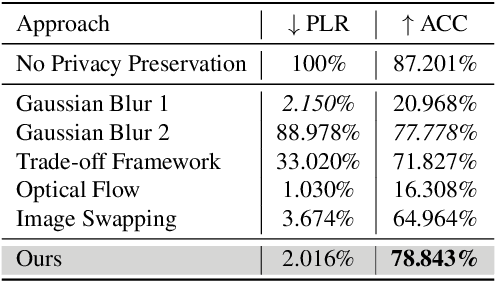
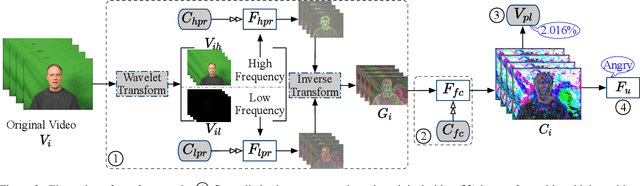
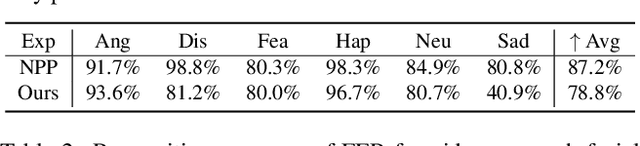
Facial expression recognition (FER) systems raise significant privacy concerns due to the potential exposure of sensitive identity information. This paper presents a study on removing identity information while preserving FER capabilities. Drawing on the observation that low-frequency components predominantly contain identity information and high-frequency components capture expression, we propose a novel two-stream framework that applies privacy enhancement to each component separately. We introduce a controlled privacy enhancement mechanism to optimize performance and a feature compensator to enhance task-relevant features without compromising privacy. Furthermore, we propose a novel privacy-utility trade-off, providing a quantifiable measure of privacy preservation efficacy in closed-set FER tasks. Extensive experiments on the benchmark CREMA-D dataset demonstrate that our framework achieves 78.84% recognition accuracy with a privacy (facial identity) leakage ratio of only 2.01%, highlighting its potential for secure and reliable video-based FER applications.