 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Spatiotemporal Graphs: Leveraging the 3D Facial Surface for Remote Physiological Measurement
Jan 20, 2026Facial remote photoplethysmography (rPPG) methods estimate physiological signals by modeling subtle color changes on the 3D facial surface over time. However, existing methods fail to explicitly align their receptive fields with the 3D facial surface-the spatial support of the rPPG signal. To address this, we propose the Facial Spatiotemporal Graph (STGraph), a novel representation that encodes facial color and structure using 3D facial mesh sequences-enabling surface-aligned spatiotemporal processing. We introduce MeshPhys, a lightweight spatiotemporal graph convolutional network that operates on the STGraph to estimate physiological signals. Across four benchmark datasets, MeshPhys achieves state-of-the-art or competitive performance in both intra- and cross-dataset settings. Ablation studies show that constraining the model's receptive field to the facial surface acts as a strong structural prior, and that surface-aligned, 3D-aware node features are critical for robustly encoding facial surface color. Together, the STGraph and MeshPhys constitute a novel, principled modeling paradigm for facial rPPG, enabling robust, interpretable, and generalizable estimation. Code is available at https://samcantrill.github.io/facial-stgraph-rppg/ .
TULUN: Transparent and Adaptable Low-resource Machine Translation
May 24, 2025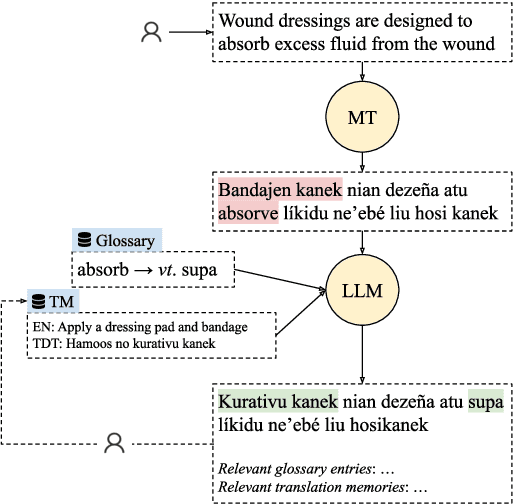
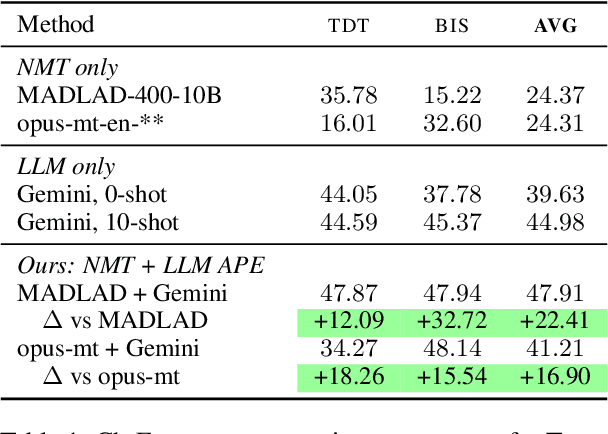
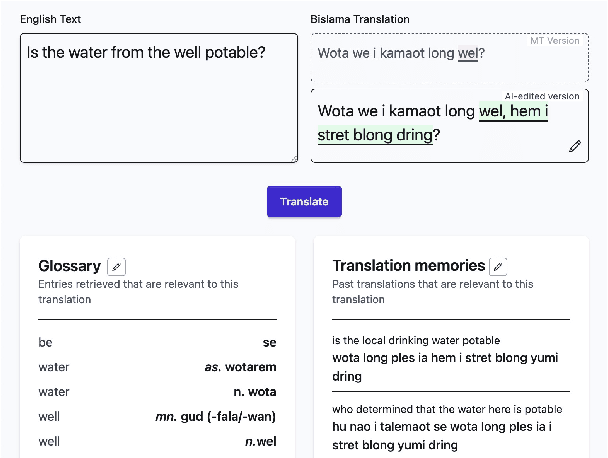
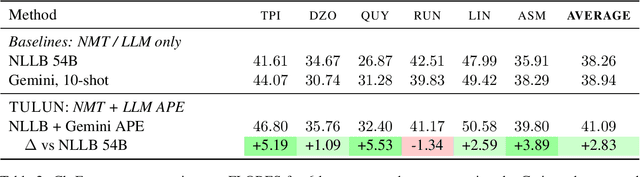
Machine translation (MT) systems that support low-resource languages often struggle on specialized domains. While researchers have proposed various techniques for domain adaptation, these approaches typically require model fine-tuning, making them impractical for non-technical users and small organizations. To address this gap, we propose Tulun, a versatile solution for terminology-aware translation, combining neural MT with large language model (LLM)-based post-editing guided by existing glossaries and translation memories. Our open-source web-based platform enables users to easily create, edit, and leverage terminology resources, fostering a collaborative human-machine translation process that respects and incorporates domain expertise while increasing MT accuracy. Evaluations show effectiveness in both real-world and benchmark scenarios: on medical and disaster relief translation tasks for Tetun and Bislama, our system achieves improvements of 16.90-22.41 ChrF++ points over baseline MT systems. Across six low-resource languages on the FLORES dataset, Tulun outperforms both standalone MT and LLM approaches, achieving an average improvement of 2.8 ChrF points over NLLB-54B.
Low-resource Machine Translation: what for? who for? An observational study on a dedicated Tetun language translation service
Nov 19, 2024The impact of machine translation (MT) on low-resource languages remains poorly understood. In particular, observational studies of actual usage patterns are scarce. Such studies could provide valuable insights into user needs and behaviours, complementing survey-based methods. Here we present an observational analysis of real-world MT usage for Tetun, the lingua franca of Timor-Leste, using server logs from a widely-used MT service with over $70,000$ monthly active users. Our analysis of $100,000$ translation requests reveals patterns that challenge assumptions based on existing corpora. We find that users, many of them students on mobile devices, typically translate short texts into Tetun across diverse domains including science, healthcare, and daily life. This contrasts sharply with available Tetun corpora, which are dominated by news articles covering government and social issues. Our results suggest that MT systems for languages like Tetun should prioritise translating into the low-resource language, handling brief inputs effectively, and covering a wide range of domains relevant to educational contexts. More broadly, this study demonstrates how observational analysis can inform low-resource language technology development, by grounding research in practical community needs.
Orientation-conditioned Facial Texture Mapping for Video-based Facial Remote Photoplethysmography Estimation
Apr 16, 2024


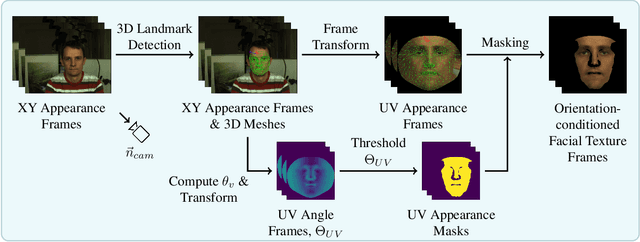
Camera-based remote photoplethysmography (rPPG) enables contactless measurement of important physiological signals such as pulse rate (PR). However, dynamic and unconstrained subject motion introduces significant variability into the facial appearance in video, confounding the ability of video-based methods to accurately extract the rPPG signal. In this study, we leverage the 3D facial surface to construct a novel orientation-conditioned facial texture video representation which improves the motion robustness of existing video-based facial rPPG estimation methods. Our proposed method achieves a significant 18.2% performance improvement in cross-dataset testing on MMPD over our baseline using the PhysNet model trained on PURE, highlighting the efficacy and generalization benefits of our designed video representation. We demonstrate significant performance improvements of up to 29.6% in all tested motion scenarios in cross-dataset testing on MMPD, even in the presence of dynamic and unconstrained subject motion, emphasizing the benefits of disentangling motion through modeling the 3D facial surface for motion robust facial rPPG estimation. We validate the efficacy of our design decisions and the impact of different video processing steps through an ablation study. Our findings illustrate the potential strengths of exploiting the 3D facial surface as a general strategy for addressing dynamic and unconstrained subject motion in videos. The code is available at https://samcantrill.github.io/orientation-uv-rppg/.
Zero- and Few-Shots Knowledge Graph Triplet Extraction with Large Language Models
Dec 04, 2023In this work, we tested the Triplet Extraction (TE) capabilities of a variety of Large Language Models (LLMs) of different sizes in the Zero- and Few-Shots settings. In detail, we proposed a pipeline that dynamically gathers contextual information from a Knowledge Base (KB), both in the form of context triplets and of (sentence, triplets) pairs as examples, and provides it to the LLM through a prompt. The additional context allowed the LLMs to be competitive with all the older fully trained baselines based on the Bidirectional Long Short-Term Memory (BiLSTM) Network architecture. We further conducted a detailed analysis of the quality of the gathered KB context, finding it to be strongly correlated with the final TE performance of the model. In contrast, the size of the model appeared to only logarithmically improve the TE capabilities of the LLMs.
Comparing Deep Learning Models for the Task of Volatility Prediction Using Multivariate Data
Jun 23, 2023This study aims to compare multiple deep learning-based forecasters for the task of predicting volatility using multivariate data. The paper evaluates a range of models, starting from simpler and shallower ones and progressing to deeper and more complex architectures. Additionally, the performance of these models is compared against naive predictions and variations of classical GARCH models. The prediction of volatility for five assets, namely S&P500, NASDAQ100, gold, silver, and oil, is specifically addressed using GARCH models, Multi-Layer Perceptrons, Recurrent Neural Networks, Temporal Convolutional Networks, and the Temporal Fusion Transformer. In the majority of cases, the Temporal Fusion Transformer, followed by variants of the Temporal Convolutional Network, outperformed classical approaches and shallow networks. These experiments were repeated, and the differences observed between the competing models were found to be statistically significant, thus providing strong encouragement for their practical application.
Enhancing Clinical Information Extraction with Transferred Contextual Embeddings
Sep 22, 2021
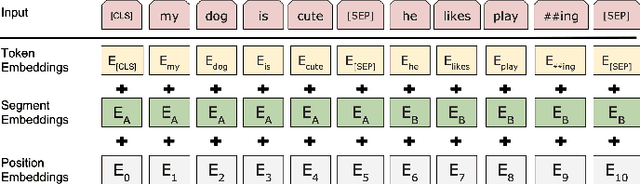
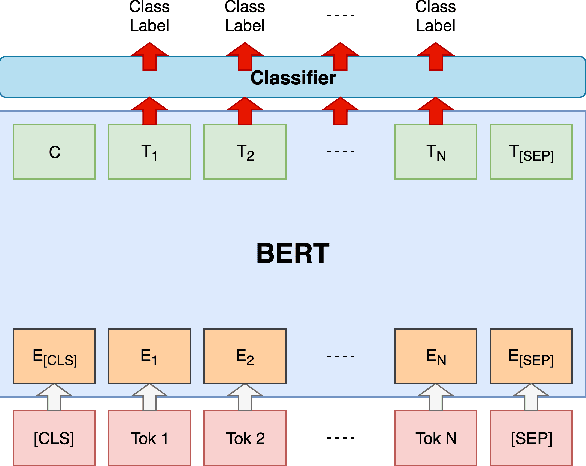
The Bidirectional Encoder Representations from Transformers (BERT) model has achieved the state-of-the-art performance for many natural language processing (NLP) tasks. Yet, limited research has been contributed to studying its effectiveness when the target domain is shifted from the pre-training corpora, for example, for biomedical or clinical NLP applications. In this paper, we applied it to a widely studied a hospital information extraction (IE) task and analyzed its performance under the transfer learning setting. Our application became the new state-of-the-art result by a clear margin, compared with a range of existing IE models. Specifically, on this nursing handover data set, the macro-average F1 score from our model was 0.438, whilst the previous best deep learning models had 0.416. In conclusion, we showed that BERT based pre-training models can be transferred to health-related documents under mild conditions and with a proper fine-tuning process.
Analyzing the Granularity and Cost of Annotation in Clinical Sequence Labeling
Aug 23, 2021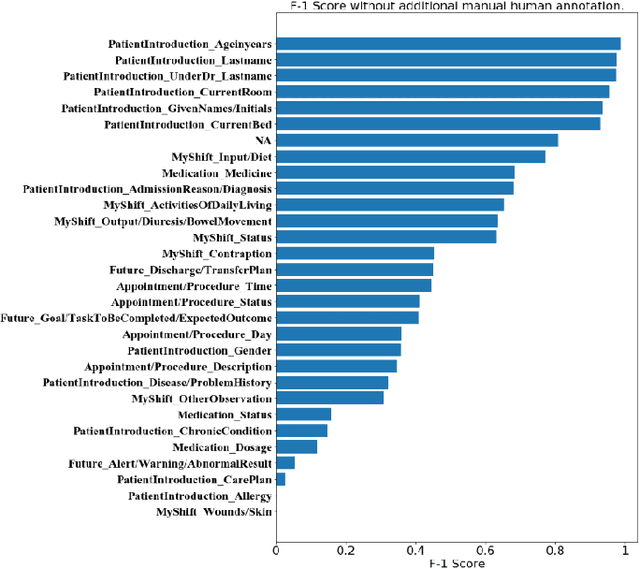
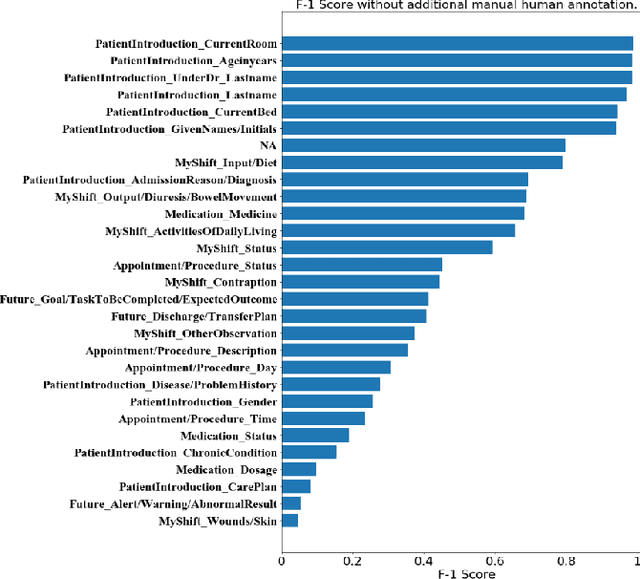
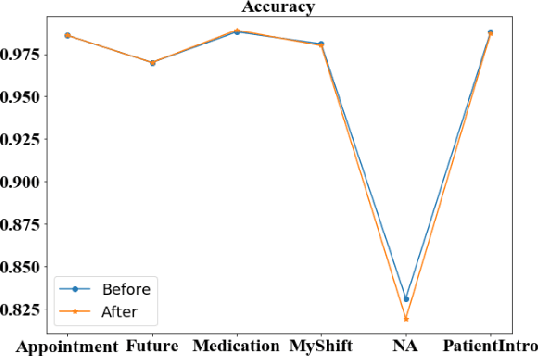
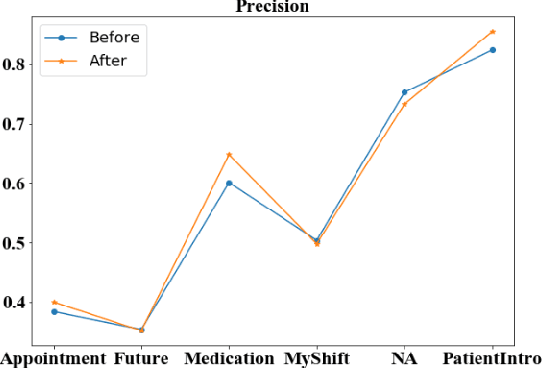
Well-annotated datasets, as shown in recent top studies, are becoming more important for researchers than ever before in supervised machine learning (ML). However, the dataset annotation process and its related human labor costs remain overlooked. In this work, we analyze the relationship between the annotation granularity and ML performance in sequence labeling, using clinical records from nursing shift-change handover. We first study a model derived from textual language features alone, without additional information based on nursing knowledge. We find that this sequence tagger performs well in most categories under this granularity. Then, we further include the additional manual annotations by a nurse, and find the sequence tagging performance remaining nearly the same. Finally, we give a guideline and reference to the community arguing it is not necessary and even not recommended to annotate in detailed granularity because of a low Return on Investment. Therefore we recommend emphasizing other features, like textual knowledge, for researchers and practitioners as a cost-effective source for increasing the sequence labeling performance.
ARVo: Learning All-Range Volumetric Correspondence for Video Deblurring
Mar 07, 2021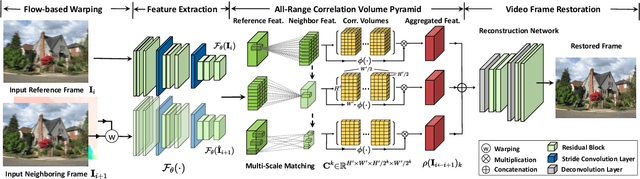
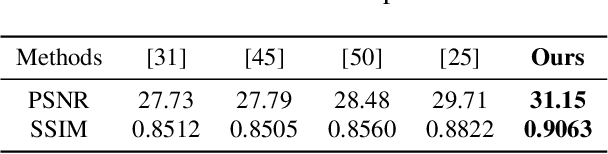
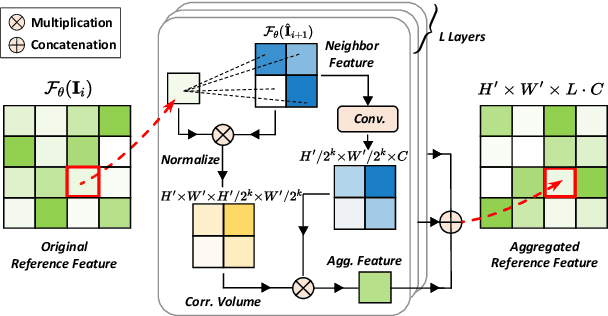

Video deblurring models exploit consecutive frames to remove blurs from camera shakes and object motions. In order to utilize neighboring sharp patches, typical methods rely mainly on homography or optical flows to spatially align neighboring blurry frames. However, such explicit approaches are less effective in the presence of fast motions with large pixel displacements. In this work, we propose a novel implicit method to learn spatial correspondence among blurry frames in the feature space. To construct distant pixel correspondences, our model builds a correlation volume pyramid among all the pixel-pairs between neighboring frames. To enhance the features of the reference frame, we design a correlative aggregation module that maximizes the pixel-pair correlations with its neighbors based on the volume pyramid. Finally, we feed the aggregated features into a reconstruction module to obtain the restored frame. We design a generative adversarial paradigm to optimize the model progressively. Our proposed method is evaluated on the widely-adopted DVD dataset, along with a newly collected High-Frame-Rate (1000 fps) Dataset for Video Deblurring (HFR-DVD). Quantitative and qualitative experiments show that our model performs favorably on both datasets against previous state-of-the-art methods, confirming the benefit of modeling all-range spatial correspondence for video deblurring.
Learning to Continually Learn Rapidly from Few and Noisy Data
Mar 06, 2021



Neural networks suffer from catastrophic forgetting and are unable to sequentially learn new tasks without guaranteed stationarity in data distribution. Continual learning could be achieved via replay -- by concurrently training externally stored old data while learning a new task. However, replay becomes less effective when each past task is allocated with less memory. To overcome this difficulty, we supplemented replay mechanics with meta-learning for rapid knowledge acquisition. By employing a meta-learner, which \textit{learns a learning rate per parameter per past task}, we found that base learners produced strong results when less memory was available. Additionally, our approach inherited several meta-learning advantages for continual learning: it demonstrated strong robustness to continually learn under the presence of noises and yielded base learners to higher accuracy in less updates.